En general, las imágenes en las computadoras se almacenan en forma de array. En el caso de la imagen en color , la imagen se representa en forma de array tridimensional o se puede decir que usamos tres arrays 2d para representar tres canales de color, una array 2d para representar el canal rojo, una para el verde y otra para representar el azul. En el caso de la imagen en escala de grises , existe un solo canal, por lo que usamos una sola array 2d para representar imágenes en escala de grises.
Siempre que decimos núcleo o máscara , generalmente nos referimos a una array de tamaño pequeño que se puede usar para aplicar efectos en nuestra imagen, como desenfoque , relieve , detección de bordes , nitidez , etc. y el proceso de aplicar estos efectos píxel por píxel se conoce como convolución. .
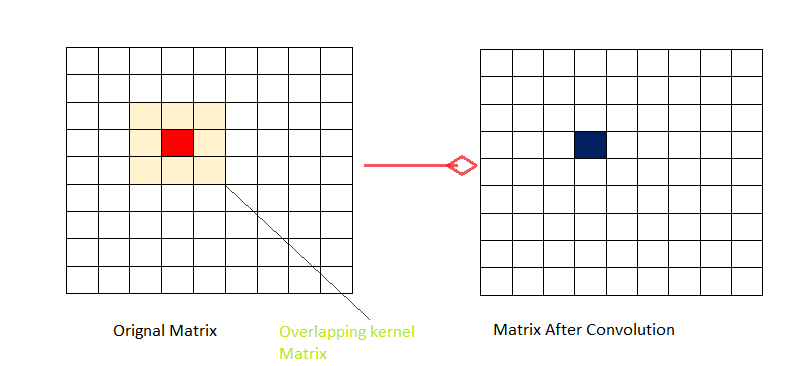
Para imaginar cómo funciona la convolución, consideremos el kernel de tamaño 3×3 y la array de imagen de tamaño 9×9 como se muestra. Ahora seleccionamos el bloque de píxeles de 3 × 3 (mismo tamaño que el kernel) en la array de la imagen y multiplicamos el bloque seleccionado en la imagen con nuestro kernel y luego tomamos la suma. Esa suma obtenida como resultante se convierte en nuestro nuevo valor de píxel y la posición de este valor de píxel es la posición central como lo muestra el color azul en el diagrama. Para obtener la imagen filtrada completa, hacemos rodar la array del núcleo píxel por píxel sobre la array de la imagen y llevamos a cabo este proceso en el ciclo.
¿Qué es el filtro de viñetas?
El filtro Viñeta generalmente se usa para enfocar la atención del espectador en ciertas partes de la imagen sin ocultar otras partes por completo. Generalmente , la parte enfocada tiene mayor brillo y saturación y el brillo y la saturación disminuyen a medida que avanzamos radialmente desde el centro hacia la periferia.
¿Cómo crear y aplicar un filtro?
Dado que deseamos mantener el brillo y la saturación de la imagen normales en el centro e intentar reducir esto a medida que avanzamos radialmente hacia afuera desde el centro de la imagen, debemos usar una función de distribución que asigne más pesos al píxel más cercano en comparación con el píxel. que está lejos. Esta es la razón principal por la que usaremos la distribución gaussiana y como sabemos que en la distribución gaussiana la mayoría de los valores son efectivamente cercanos a cero y ninguno cero. Así que estaremos creando una máscara de tamaño suficientemente grande. Para crear una función gaussiana 2-d, crearemos dos funciones gaussianas 1-dy multiplica estos dos. Uno perteneciente a la dirección X y otro a la dirección Y. Dado que nuestra array de kernel actual es grande en tamaño, normalizaremos para reducir el tamaño del kernel; de lo contrario, el costo de aplicar un filtro será demasiado alto.
OpenCV proporciona una función llamada getGaussianKernel que usaremos para construir nuestro kernel 2D cuyo tamaño coincida con el tamaño de la imagen.
función getGaussianKernel
El primer parámetro de la función, es decir, ksize: decide el tamaño del kernel y generalmente preferimos un valor impar positivo. El segundo parámetro de la función, es decir, sigma: es la desviación estándar de la Gaussiana y controla el radio de la imagen central brillante. La función calcula y devuelve la array del tamaño asignado en el primer parámetro y contiene coeficientes de filtro gaussiano .
Mask = (scale size) * (Normalized kernel matrix )
Después de la creación de la máscara, iteraremos sobre todos los canales de color y aplicaremos la máscara a cada canal. El escalado es un paso importante; de lo contrario, todos los valores de píxeles estarán cerca de 0 después de superponer la máscara en la imagen y la imagen se verá negra.
A continuación se muestra la implementación.
Python3
import numpy as np
import cv2
#reading the image
input_image = cv2.imread('food.jpeg')
#resizing the image according to our need
# resize() function takes 2 parameters,
# the image and the dimensions
input_image = cv2.resize(input_image, (480, 480))
# Extracting the height and width of an image
rows, cols = input_image.shape[:2]
# generating vignette mask using Gaussian
# resultant_kernels
X_resultant_kernel = cv2.getGaussianKernel(cols,200)
Y_resultant_kernel = cv2.getGaussianKernel(rows,200)
#generating resultant_kernel matrix
resultant_kernel = Y_resultant_kernel * X_resultant_kernel.T
#creating mask and normalising by using np.linalg
# function
mask = 255 * resultant_kernel / np.linalg.norm(resultant_kernel)
output = np.copy(input_image)
# applying the mask to each channel in the input image
for i in range(3):
output[:,:,i] = output[:,:,i] * mask
#displaying the original image
cv2.imshow('Original', input_image)
#displaying the vignette filter image
cv2.imshow('VIGNETTE', output)
# Maintain output window utill
# user presses a key
cv2.waitKey(0)
# Destroying present windows on screen
cv2.destroyAllWindows()
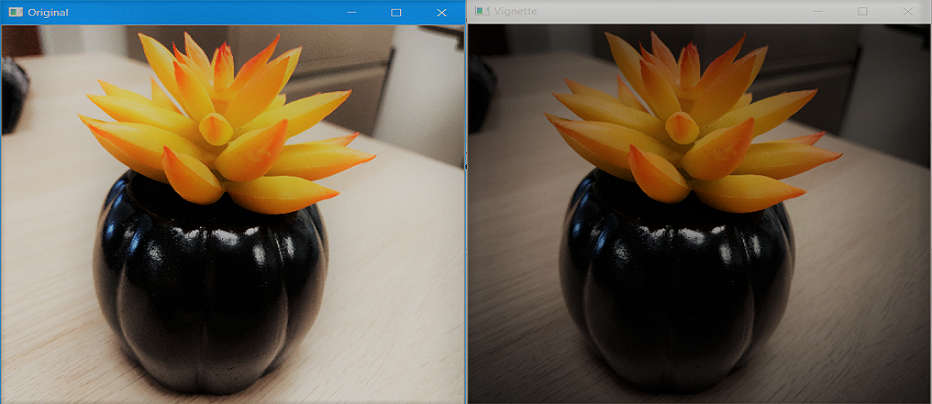
Producción:
Publicación traducida automáticamente
Artículo escrito por AyushMalik y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA