En este artículo, vamos a ver un par de métodos para crear columnas no jerárquicas al aplicar el módulo groupby .
Estamos utilizando el conjunto de datos de las empresas Fortune 500 para demostrar el problema y la solución. Tenemos que obtener una copia del sitio web data.world .
Para cada «Sector» e «Industria», busque el promedio total de empleados y el cambio de ingresos mínimo y máximo.
Veamos un ejemplo con implementación:
Paso 1: comencemos importando pandas y el conjunto de datos con el «Rank» de la empresa como índice.
Python3
import pandas as pd # load the dataset df = pd.read_csv( "https://raw.githubusercontent.com/sasankac/TestDataSet/master/Fortune500.csv") # print the columns print(df.columns)
Producción:

Paso 2: hay una gran cantidad de columnas que no nos interesan en el conjunto de datos, como la ubicación de la sede, la dirección,… Las eliminaré del conjunto de datos.
Python3
# remove unwanted columns remove_columns =['Website','Hqaddr','Hqzip', 'Hqtel', 'Ceo','Ceo-title', 'Address', 'Ticker', 'Prftchange', 'Assets', 'Totshequity'] df = df.drop(columns= remove_columns,axis = 1) print(df.columns)
Producción:

Método 1:
En este método, usaremos el método to_flat_index para generar columnas no jerárquicas. Permítanme, primero agrupar, las columnas para identificar los datos a continuación. Para cada «Sector» e «Industria», busque el promedio total de empleados y el cambio de ingresos mínimo y máximo. La sintaxis para groupby y aggregation es la siguiente
Sintaxis: df.groupby([‘columna de agrupación 1′,’ columna de agrupación 2”]).agg({ ‘columna agregada 1’ :[‘función agregada 1′,’ función agregada 2′] })
Ahora, según el requisito, asignemos los nombres de las columnas del conjunto de datos a la sintaxis.
- Columnas de agrupación: ‘Sector’, ‘Industria’
- Columnas agregadas: ‘Empleados’, ‘Revchange’
- Funciones agregadas: ‘sum’, ‘mean’, ‘min’ ”max3. Obtener los resultados aplicando la sintaxis anterior.
Implementación:
Python3
df_result = (df
.groupby(['Sector','Industry'])
.agg({'Employees':['sum', 'mean'],
'Revchange':['min','max']}))
# printing top 15 rows
df_result.head(15)
Producción:
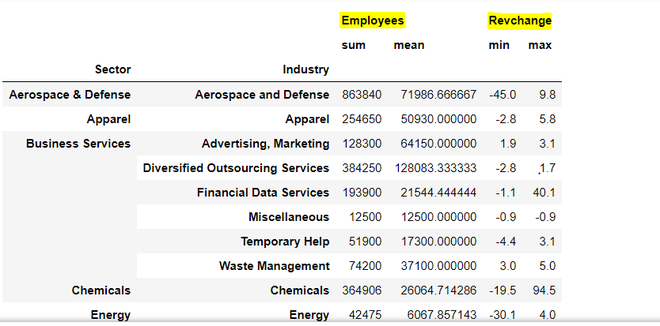
En cuanto a los resultados, tenemos 6 columnas jerárquicas, es decir, suma y media para empleados (resaltadas en amarillo) y columnas mínimas y máximas para Revchange. Podemos convertir las columnas jerárquicas en columnas no jerárquicas usando el método .to_flat_index que se introdujo en la versión 0.24 de pandas.
Python3
df_result.columns = ['_'.join(cols).lower() for cols in df_result.columns.to_flat_index()] df_result.head(10)
Producción:
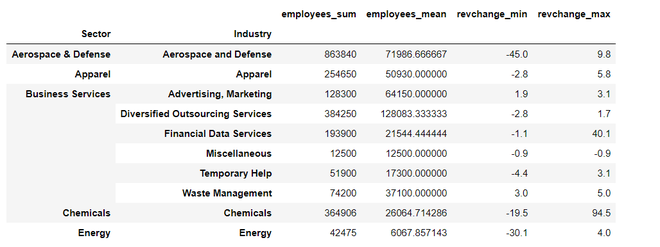
Una vez que la función se aplica con éxito, todas las columnas no se aplanan con el nombre de la columna adjunto con las funciones agregadas.
Plena aplicación:
Python3
"""
Program: For each "Sector" and "Industry" Find the total, average employees, and the minimum, maximum revenue change.
"""
import pandas as pd
"""
Function: Convert hierarchial columns to non-hierarchial columns
params: dataframe with hierarchial columns
return : dataframe with non-hierarchial columns
"""
def return_non_hierarchial(df):
df.columns = ['_'.join(x) for x in df.columns.to_flat_index()]
return df
# load the dataset with rank as index
df = pd.read_csv(
"https://raw.githubusercontent.com/sasankac/TestDataSet/master/Fortune500.csv", index_col="Rank")
# remove unwanted columns
remove_columns = ['Website', 'Hqaddr', 'Hqzip', 'Hqtel', 'Ceo',
'Ceo-title', 'Address', 'Ticker', 'Prftchange',
'Assets', 'Totshequity']
df = df.drop(columns=remove_columns, axis=1)
# Identify the data as per the requirement
df_result = (df
.groupby(['Sector', 'Industry'])
.agg({'Employees': ['sum', 'mean'],
'Revchange': ['min', 'max']})
.astype(int)
.pipe(return_non_hierarchial))
# print the data
df_result.head(15)
Producción:
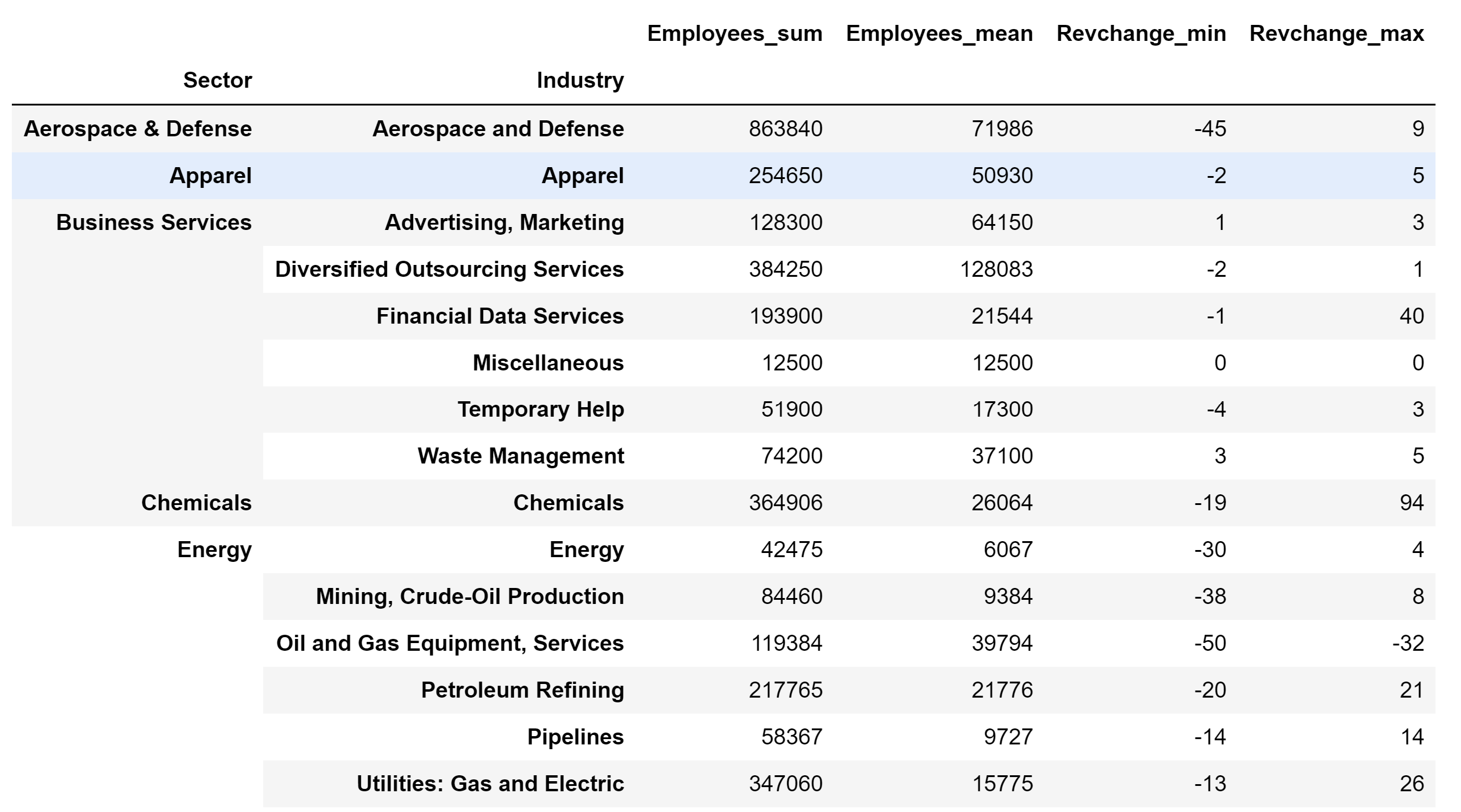
Método 2:
Pandas ha introducido objetos de agregación con nombre para crear columnas no jerárquicas. Usaré el mismo requisito mencionado anteriormente y lo aplicaré a la agregación con nombre.
La sintaxis para este método groupby es la siguiente:
df.groupby([‘columna de agrupación 1′,’ columna de agrupación 2”]).agg({ ‘Columna con nombre’ = NamedAgg(columna=’columna agregada’, aggfunc=’función agregada’))
Implementación:
Python3
""" Program: For each "Sector" and "Industry" Find the total, average employees, and the minimum, maximum revenue change. """ import pandas as pd # load the dataset with rank as index df = pd.read_csv( "https://raw.githubusercontent.com/sasankac/TestDataSet/master/Fortune500.csv", index_col="Rank") # remove unwanted columns remove_columns = ['Website', 'Hqaddr', 'Hqzip', 'Hqtel', 'Ceo', 'Ceo-title', 'Address', 'Ticker', 'Prftchange', 'Assets', 'Totshequity'] df = df.drop(columns=remove_columns, axis=1) # Identify the data as per the requirement df_result = (df .groupby(['Sector', 'Industry']) .agg(Employees_sum=pd.NamedAgg(column='Employees', aggfunc='sum'), Employees_average=pd.NamedAgg( column='Employees', aggfunc='mean'), Revchange_minimum=pd.NamedAgg( column='Revchange', aggfunc='min'), Revchange_maximum=pd.NamedAgg(column='Revchange', aggfunc='max')) .astype(int)) # print the data df_result.head(15)
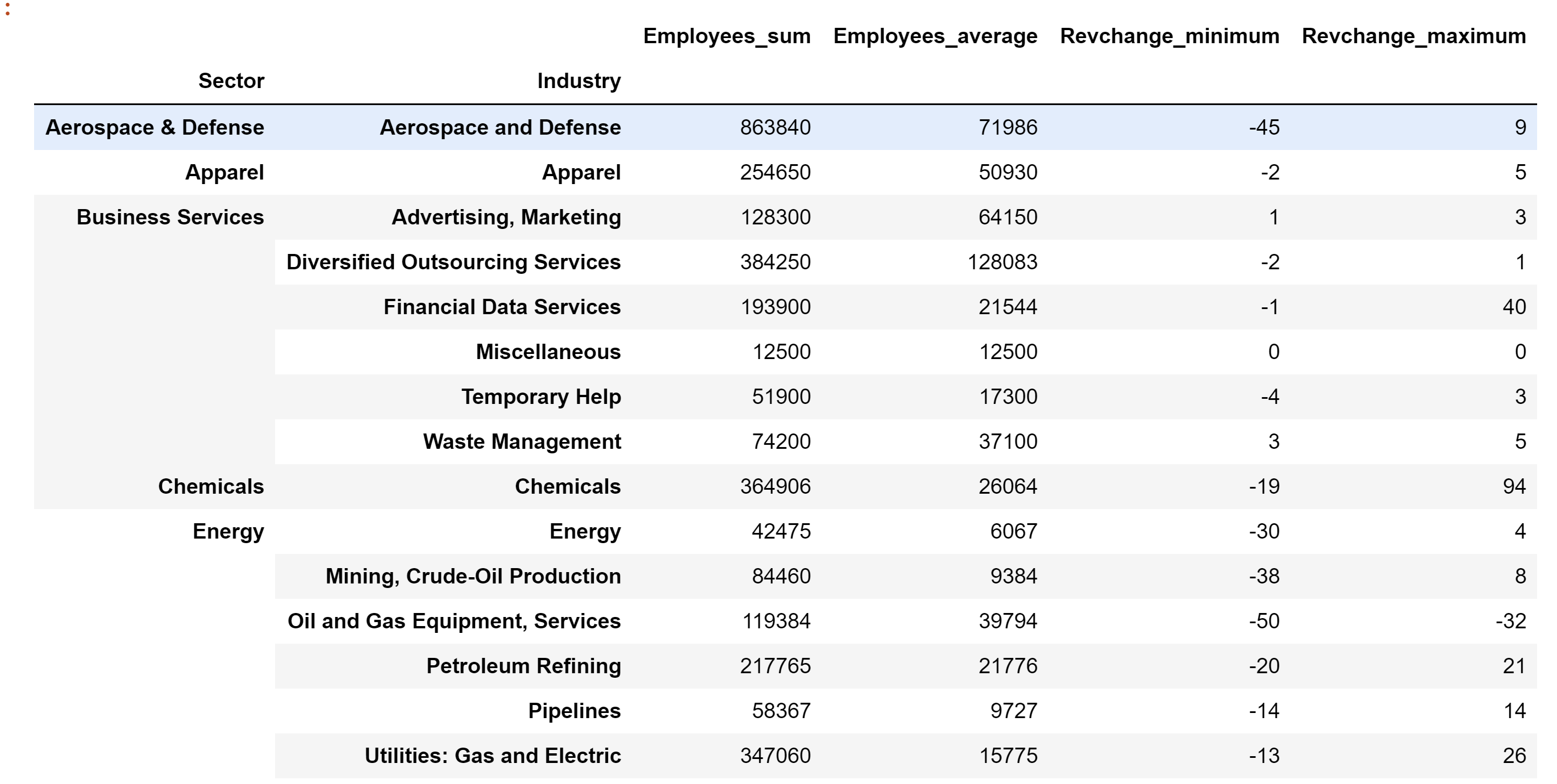
Producción:
Publicación traducida automáticamente
Artículo escrito por sasankac280689 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA