En este artículo, vamos a discutir la creación de un marco de datos Pyspark a partir de una lista de tuplas.
Para hacer esto, usaremos el método createDataFrame() de pyspark. Este método crea un dataframe a partir de RDD, list o Pandas Dataframe. Aquí los datos serán la lista de tuplas y las columnas serán una lista de nombres de columnas.
Sintaxis:
marco de datos = chispa.createDataFrame (datos, columnas)
Ejemplo 1:
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of tuples of college data
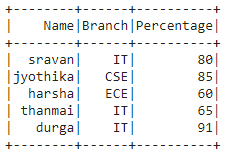
data = [("sravan", "IT", 80),
("jyothika", "CSE", 85),
("harsha", "ECE", 60),
("thanmai", "IT", 65),
("durga", "IT", 91)]
# giving column names of dataframe
columns = ["Name", "Branch", "Percentage"]
# creating a dataframe
dataframe = spark.createDataFrame(data, columns)
# show data frame
dataframe.show()
Producción:
Ejemplo 2:
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of tuples of plants data
data = [("mango", "AP", "Guntur"),
("mango", "AP", "Chittor"),
("sugar cane", "AP", "amaravathi"),
("paddy", "TS", "adilabad"),
("wheat", "AP", "nellore")]
# giving column names of dataframe
columns = ["Crop Name", "State", "District"]
# creating a dataframe
dataframe = spark.createDataFrame(data, columns)
# show data frame
dataframe.show()
Producción:

Ejemplo 3:
Código de Python para contar los registros (tuplas) en la lista
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving
# an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
#list of tuples of plants data
data = [("mango", "AP", "Guntur"),
("mango", "AP", "Chittor"),
("sugar cane", "AP", "amaravathi"),
("paddy", "TS", "adilabad"),
("wheat", "AP", "nellore")]
# giving column names of dataframe
columns = ["Crop Name", "State", "District"]
# creating a dataframe
dataframe = spark.createDataFrame(data, columns)
#count records in the list
dataframe.count()
Producción:
5
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA