De acuerdo con la definición dada en Wikipedia, el cuarteto de Anscombe comprende cuatro conjuntos de datos que tienen propiedades estadísticas simples casi idénticas, pero que parecen muy diferentes cuando se grafican. Cada conjunto de datos consta de once (x,y) puntos. Fueron construidos en 1973 por el estadístico Francis Anscombe para demostrar tanto la importancia de graficar los datos antes de analizarlos como el efecto de los valores atípicos en las propiedades estadísticas.
Comprensión simple:
una vez que Francis John «Frank» Anscombe, un estadístico de gran reputación, encontró 4 conjuntos de 11 puntos de datos en su sueño y solicitó al consejo como su último deseo trazar esos puntos. Esos 4 conjuntos de 11 puntos de datos se dan a continuación.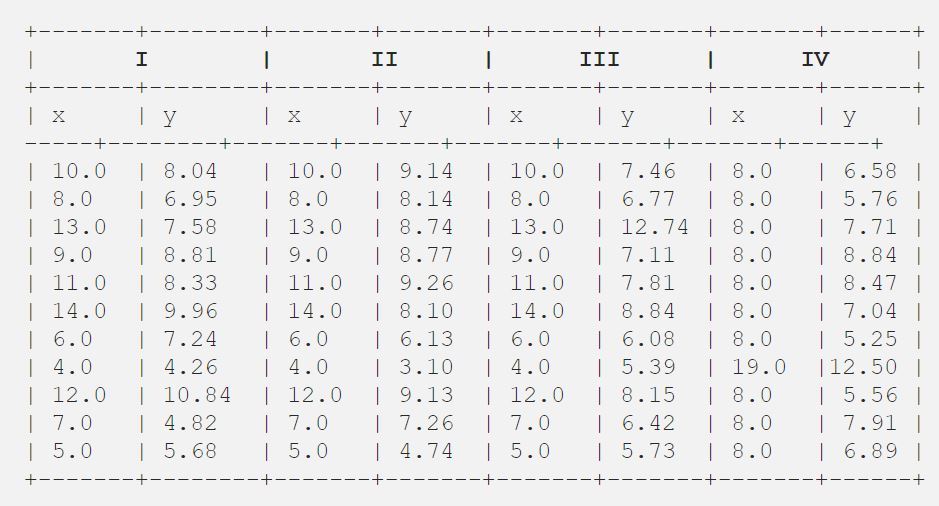
Después de eso, el consejo los analizó usando solo estadísticas descriptivas y encontró la media, la desviación estándar y la correlación entre x e y.
Descargue el archivo csv aquí.
Código: programa de Python para encontrar la media, la desviación estándar y la correlación entre x e y
# Import the required libraries
import pandas as pd
import statistics
from scipy.stats import pearsonr
# Import the csv file
df = pd.read_csv("anscombe.csv")
# Convert pandas dataframe into pandas series
list1 = df['x1']
list2 = df['y1']
# Calculating mean for x1
print('%.1f' % statistics.mean(list1))
# Calculating standard deviation for x1
print('%.2f' % statistics.stdev(list1))
# Calculating mean for y1
print('%.1f' % statistics.mean(list2))
# Calculating standard deviation for y1
print('%.2f' % statistics.stdev(list2))
# Calculating pearson correlation
corr, _ = pearsonr(list1, list2)
print('%.3f' % corr)
# Similarly calculate for the other 3 samples
# This code is contributed by Amiya Rout
Producción:
9.0 3.32 7.5 2.03 0.816
Así que déjame mostrarte el resultado en forma tabular para una mejor comprensión.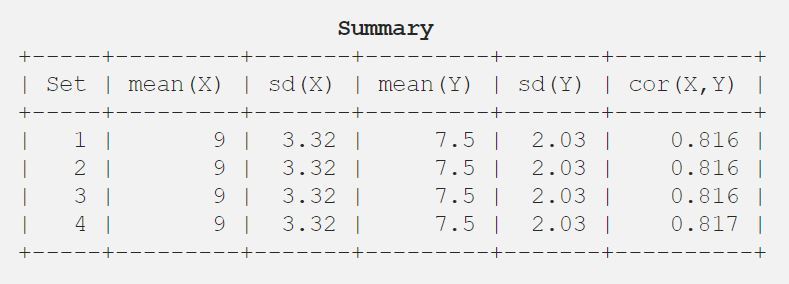
Código: programa de Python para trazar un diagrama de dispersión
# Import the required libraries
from matplotlib import pyplot as plt
import pandas as pd
# Import the csv file
df = pd.read_csv("anscombe.csv")
# Convert pandas dataframe into pandas series
list1 = df['x1']
list2 = df['y1']
# Function to plot scatter
plt.scatter(list1, list2)
# Function to show the plot
plt.show()
# Similarly plot scatter plot for other 3 data sets
# This code is contributed by Amiya Rout
Para la línea de regresión, consulte esto.
Salida: 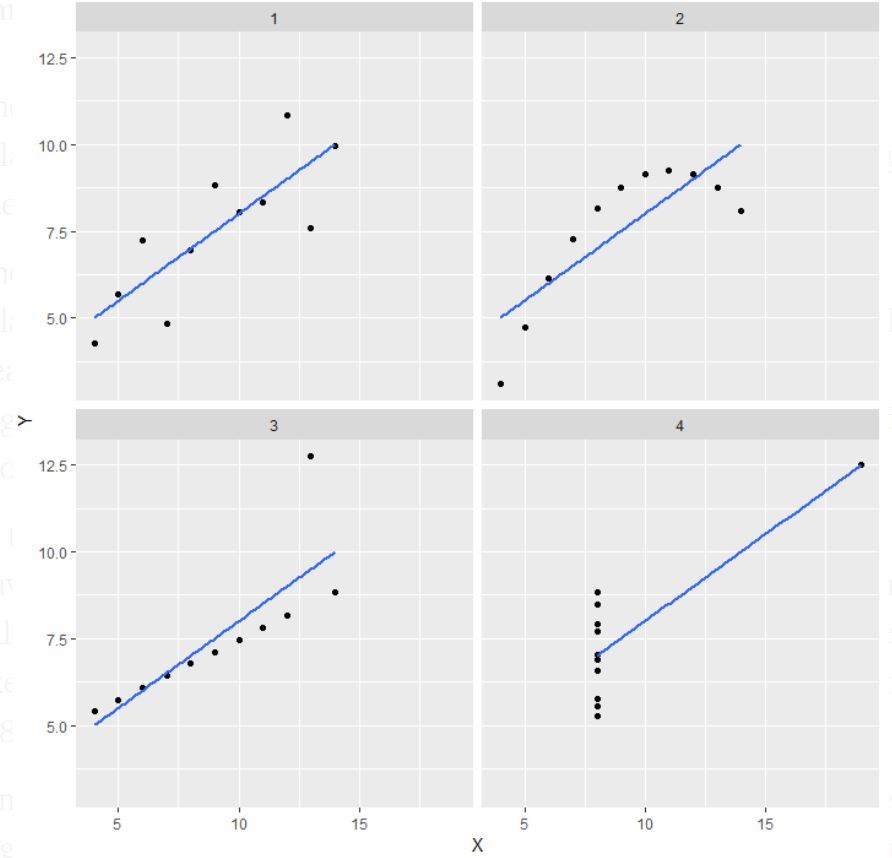
Nota: Se menciona en la definición que el cuarteto de Anscombe comprende cuatro conjuntos de datos que tienen propiedades estadísticas simples casi idénticas, pero que parecen muy diferentes cuando se grafican.
Explicación de esta salida:
- En el primero (arriba a la izquierda), si observa el diagrama de dispersión, verá que parece haber una relación lineal entre x e y.
- En el segundo (arriba a la derecha), si observa esta figura, puede concluir que existe una relación no lineal entre x e y.
- En el tercero (abajo a la izquierda) puede decir cuándo hay una relación lineal perfecta para todos los puntos de datos excepto uno que parece ser un valor atípico que se indica que está lejos de esa línea.
- Finalmente, el cuarto (abajo a la derecha) muestra un ejemplo cuando un punto de apalancamiento alto es suficiente para producir un coeficiente de correlación alto.
Aplicación:
el cuarteto todavía se usa a menudo para ilustrar la importancia de mirar un conjunto de datos gráficamente antes de comenzar a analizar de acuerdo con un tipo particular de relación y la insuficiencia de las propiedades estadísticas básicas para describir conjuntos de datos realistas.
Publicación traducida automáticamente
Artículo escrito por AmiyaRanjanRout y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA