En este artículo, veamos cómo podemos contar distintos en la agregación de pandas. Entonces, para contar los distintos en la agregación de pandas, vamos a usar el método groupby() y add().
- groupby(): este método se utiliza para dividir los datos en grupos según algunos criterios. Los objetos de Pandas se pueden dividir en cualquiera de sus ejes. Podemos crear una agrupación de categorías y aplicar una función a las categorías. La definición abstracta de agrupación es proporcionar un mapeo de etiquetas a nombres de grupos
- agg(): Este método se usa para pasar una función o lista de funciones a aplicar en una serie o incluso cada elemento de la serie por separado. En el caso de una lista de funciones, el método agg() devuelve múltiples resultados.
A continuación se muestran algunos ejemplos que muestran cómo contar distintos en la agregación de Pandas:
Ejemplo 1:
Python
# import module
import pandas as pd
import numpy as np
# create Data frame
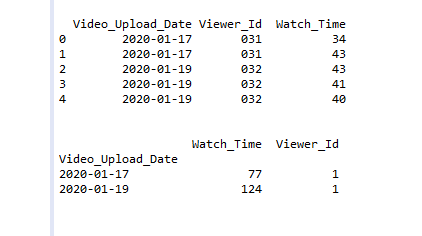
df = pd.DataFrame({'Video_Upload_Date': ['2020-01-17',
'2020-01-17',
'2020-01-19',
'2020-01-19',
'2020-01-19'],
'Viewer_Id': ['031', '031', '032',
'032', '032'],
'Watch_Time': [34, 43, 43, 41, 40]})
# print original Dataframe
print(df)
# let's Count distinct in Pandas aggregation
df = df.groupby("Video_Upload_Date").agg(
{"Watch_Time": np.sum, "Viewer_Id": pd.Series.nunique})
# print final output
print(df)
Producción:
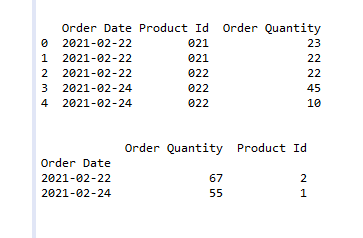
Ejemplo 2:
Python
# import module
import pandas as pd
import numpy as np
# create Data frame
df = pd.DataFrame({'Order Date': ['2021-02-22',
'2021-02-22',
'2021-02-22',
'2021-02-24',
'2021-02-24'],
'Product Id': ['021', '021',
'022', '022', '022'],
'Order Quantity': [23, 22, 22,
45, 10]})
# print original Dataframe
print(df)
# let's Count distinct in Pandas aggregation
df = df.groupby("Order Date").agg({"Order Quantity": np.sum,
"Product Id": pd.Series.nunique})
# print final output
print(df)
Producción: