Prerrequisitos: Pandas
En este artículo, estamos encontrando y contando los valores únicos presentes en el grupo/columna con Pandas. Los valores únicos son los valores distintos que ocurren solo una vez en el conjunto de datos o las primeras apariciones de valores duplicados que se cuentan como valores únicos.
Acercarse:
- Importa la biblioteca de pandas.
- Importe o cree un marco de datos usando la función DataFrame() en la que pasa los datos como un parámetro en el que desea crear un marco de datos, deje que se llame «df», o para importar un conjunto de datos, use la función pandas.read_csv() en la que pasa la ruta y el nombre del conjunto de datos.
- Seleccione la columna en la que desea verificar o contar los valores únicos.
- Para encontrar valores únicos, usamos la función unique() proporcionada por pandas y la almacenamos en una variable, denominándola como ‘unique_values’.
Sintaxis: pandas.unique(df(nombre_columna)) o df[‘nombre_columna’].unique()
- Dará los valores únicos presentes en ese grupo/columna.
- Para contar la cantidad de valores únicos, primero debemos inicializar la variable let denominada como ‘contar’ como 0, luego ejecutar el ciclo for para ‘valores_únicos’ y contar la cantidad de veces que se ejecuta el ciclo e incrementar el valor de ‘contar ‘ por 1
- Luego imprima el ‘recuento’, este valor almacenado es el número de valores únicos presentes en ese grupo/columna en particular.
- Para encontrar la cantidad de veces que se repite el valor único en la columna en particular, estamos usando la función value_counts() proporcionada por Pandas.
Sintaxis: pandas.value_counts(df[‘column_name’] o df[‘column_name’].value_counts()
- Esto le dará la cantidad de veces que cada valor único se repite en esa columna en particular.
Para una mejor comprensión del tema. Tomemos algunos ejemplos e implementemos las funciones como se discutió anteriormente en el enfoque.
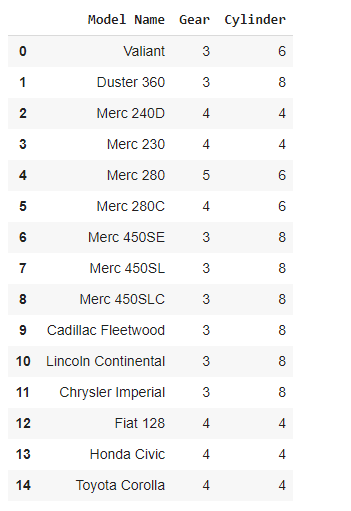
Ejemplo 1: Creación de DataFrame usando la biblioteca pandas.
Python
# importing library
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using
# pandas DataFrame function.
car_df = pd.DataFrame(car_data)
# printing the dataframe
car_df
Producción:
Ejemplo 2: Impresión de valores únicos presentes en los grupos per.
Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# printing the unique values present in the Gear column
# finding unique values present
# in the Gear column using unique() function
print(f"Unique values present in Gear column are: {car_df['Gear'].unique()}")
# printing the unique values present
# in the Cylinder column
# finding unique values present in the
# Cylinder column using unique() function
print(f"Unique values present in Cylinder column are: {car_df['Cylinder'].unique()}")
Producción:

De la imagen de salida anterior, podemos observar que estamos obteniendo tres valores únicos de ambos grupos.
Ejemplo 3: Otra forma de encontrar valores únicos presentes en por grupos.
Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8, 8,
8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# finding unique values present in the
# groups using unique() function
unique_gear = pd.unique(car_df.Gear)
unique_cyl = pd.unique(car_df.Cylinder)
# printing the unique values present in the Gear column
print(f"Unique values present in Gear column are: {unique_gear}")
# printing the unique values present in the Cylinder column
print(f"Unique values present in Cylinder column are: {unique_cyl}")
Producción:
El resultado es similar pero la diferencia es que en este ejemplo habíamos encontrado los valores únicos presentes en cada grupo usando la función pd.unique() en la que habíamos pasado nuestra columna de marco de datos.
Ejemplo 4: contar el número de veces que se repite cada valor único.
Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3,
3, 3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# counting number of times each unique values
# present in the particular group using
# value_counts() function
gear_count = pd.value_counts(car_df.Gear)
cyl_count = pd.value_counts(car_df.Cylinder)
# another way of obtaining the same output
g_count = car_df['Gear'].value_counts()
cy_count = car_df['Cylinder'].value_counts()
print('----Output from first method-----')
# printing number of times each unique
# values present in the particular group
print(gear_count)
print(cyl_count)
# printing output from the second method
print('----Output from second method----')
print(g_count)
print(cy_count)
Producción:
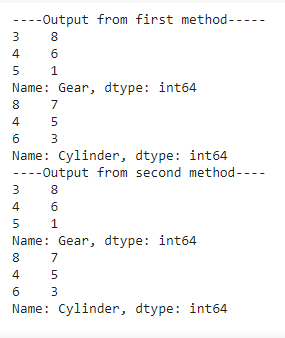
De la imagen de salida anterior, estamos obteniendo el mismo resultado de ambos métodos para escribir el código.
Podemos observar que en la columna Engranaje obtenemos valores únicos 3,4 y 5 que se repiten 8,6 y 1 vez respectivamente, mientras que en la columna Cilindro obtenemos valores únicos 8,4 y 6 que se repiten 7,5 y 3 veces respectivamente.
Ejemplo 5: Contando el número de valores únicos presentes en el grupo.
Python
# importing libraries
import pandas as pd
# storing the data of cars in the dictionary
car_data = {'Model Name': ['Valiant',
'Duster 360',
'Merc 240D',
'Merc 230',
'Merc 280',
'Merc 280C',
'Merc 450SE',
'Merc 450SL',
'Merc 450SLC',
'Cadillac Fleetwood',
'Lincoln Continental',
'Chrysler Imperial',
'Fiat 128',
'Honda Civic',
'Toyota Corolla'],
'Gear': [3, 3, 4, 4, 5, 4, 3, 3,
3, 3, 3, 3, 4, 4, 4],
'Cylinder': [6, 8, 4, 4, 6, 6, 8,
8, 8, 8, 8, 8, 4, 4, 4]}
# creating DataFrame for the data using pandas
car_df = pd.DataFrame(car_data)
# finding unique values present in the particular group.
name_count = pd.unique(car_df['Model Name'])
gear_count = pd.unique(car_df.Gear)
cyl_count = pd.unique(car_df.Cylinder)
# initializing variable to 0 for counting
name_unique = 0
gear_unique = 0
cyl_unique = 0
# writing separate for loop of each groups
for item in name_count:
name_unique += 1
for item in gear_count:
gear_unique += 1
for item in gear_count:
cyl_unique += 1
# printing the number of unique values present in each group
print(f'Number of unique values present in Model Name: {name_unique}')
print(f'Number of unique values present in Gear: {gear_unique}')
print(f'Number of unique values present in Cylinder: {cyl_unique}')
Producción:

De la imagen de salida anterior, podemos observar que estamos obteniendo 15,3 y 3 valores únicos presentes en las columnas Nombre del modelo, Engranaje y Cilindro, respectivamente.
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA