Desde que los humanos comenzaron a educarse sobre el mundo que los rodea, la pintura se ha mantenido como la principal forma de expresar emociones y comprensión. Por ejemplo, la imagen del tigre a continuación tiene el contenido de un tigre de los tigres del mundo real. Pero tenga en cuenta que el estilo de texturizado y coloreado depende en gran medida del creador.
¿Qué es la Transferencia de Estilo en Redes Neuronales?
Supongamos que tiene su fotografía (P), capturada desde su teléfono. Desea estilizar su fotografía como se muestra a continuación.
Este proceso de tomar el contenido de una imagen (P) y el estilo de otra imagen (A) para generar una imagen (X) que coincida con el contenido de P y el estilo de A se denomina transferencia de estilo o armonización profunda. No puede obtener X simplemente superponiendo P y A.
Architecture & Algorithm
Gatys et al en 2015 demostraron que es posible separar el contenido y el estilo de una imagen y, por lo tanto, es posible combinar el contenido y el estilo de diferentes imágenes. Usó una red neuronal convolucional (CNN), llamada vgg-19 (vgg significa Visual Geometric Group) que tiene 19 capas de profundidad (con 16 capas CONV y 3 capas FC).
vgg-19 está previamente capacitado en el conjunto de datos de ImageNet por Standford Vision Lab de la Universidad de Stanford. Gatys usó agrupación promedio y no capas FC.
La agrupación se utiliza normalmente para reducir el volumen espacial de los vectores de características. Esto ayuda a reducir la cantidad de cálculos. Hay 2 tipos de agrupación como se muestra a continuación:
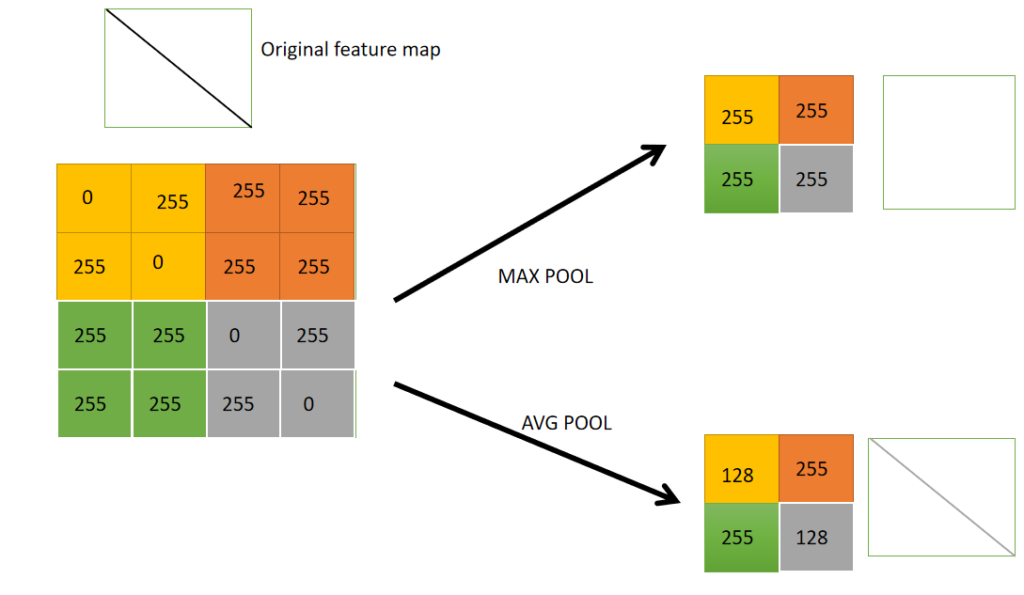
Proceso de agrupación
Pérdidas en Transferencia de Estilo:
- Pérdida de contenido
Seleccionemos una capa oculta (L) en vgg-19 para calcular la pérdida de contenido. Sea p: imagen original yx: imagen generada. Sean P l y F l las representaciones de características de las respectivas imágenes correspondientes a la capa L. Entonces la pérdida de contenido se definirá como:
- Pérdida de estilo
Para esto, primero tenemos que calcular Gram Matrix . El cálculo de la correlación entre diferentes filtros/canales involucra el producto escalar entre los mapas de características vectorizados i y j en la capa l. La array así obtenida se denomina Array Gram (G). La pérdida de estilo es el cuadrado de la diferencia entre la array Gram de la imagen de estilo con la array Gram de la imagen generada.
- La pérdida total
se define mediante la siguiente fórmula (con α y β son hiperparámetros que se establecen según el requisito).
La imagen generada X, en teoría, es tal que la pérdida de contenido y estilo es mínima. Eso significa que X coincide con el contenido de P y el estilo de A al mismo tiempo. Hacer esto generará la salida deseada.
Nota: Este es un nuevo campo muy emocionante que es posible gracias a las optimizaciones de hardware, el paralelismo con CUDA (Arquitectura de dispositivo unificado de cómputo) y el concepto de hiperprocesamiento de Intel.
Código y salida
Puede encontrar el código completo, los archivos de datos y las salidas de Style Transfer (bonificación por quedarse: ¡también tiene código para diseñar audio!) aquí Github Repo de __CA__ .
Publicación traducida automáticamente
Artículo escrito por gauravkabrageek y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA