Un filtro de Kalman es un algoritmo de estimación óptimo. Puede ayudarnos a predecir/estimar la posición de un objeto cuando estamos en estado de duda debido a diferentes limitaciones, como la precisión o las restricciones físicas, que discutiremos en breve.
Aplicación del filtro de Kalman:
Los filtros de Kalman se utilizan cuando:
- Variable de interés que solo puede medirse indirectamente.
- Las mediciones están disponibles desde varios sensores, pero pueden estar sujetas a ruido, es decir, Sensor Fusion.
Profundicemos en cada uno de los usos uno por uno.
- Medición indirecta:
para medir la variable de interés (variable en consideración) que solo se puede medir indirectamente. Este tipo de variable se denomina variable estimada de estado. Entendámoslo con un ejemplo.
Ejemplo:
Digamos que quieres saber qué tan feliz es tu perro Jacky. Por lo tanto, su variable de interés, y es la felicidad de Jacky. Ahora, la única forma de medir la felicidad de Jacky es medirla indirectamente, ya que la felicidad no es un estado físico que pueda medirse directamente. Puedes elegir ver a Jacky agitar la cola y predecir si está feliz o no. También puede tener un enfoque completamente diferente para darle una idea o estimar cuán feliz es Jacky. Esta idea única es el Filtro Kalman. Y eso es lo que quise decir cuando dije que el filtro de Kalman es un algoritmo de estimación óptimo. - Sensor Fusion:
Ahora tienes la intuición de qué es exactamente este filtro. Kalman Filter combina la medición y la predicción para encontrar la estimación óptima de la posición del automóvil.
Ejemplo:
suponga que tiene un automóvil a control remoto y está funcionando a una velocidad de 1 m/s. digamos que después de 1 segundo necesitas predecir la posición exacta del auto ¿cuál será tu predicción?
Bueno, si conoce alguna fórmula básica de tiempo, distancia y velocidad, podrá decir correctamente 1 metro por delante de la posición actual. Pero, ¿qué tan preciso es este modelo?
Siempre hay algunas variaciones del escenario ideal y esa desviación es la causa del error. Ahora, para minimizar el error en la predicción del estado, se toma la medida de un sensor. La medición del sensor también tiene algún error. Entonces, ahora tenemos dos distribuciones de probabilidad (el sensor y la predicción, ya que no siempre son un número, sino la función de distribución de probabilidad (pdf)) que se supone que indican la ubicación del automóvil. Una vez que combinamos estas dos curvas gaussianas, podemos obtener una gaussiana completamente nueva que tiene mucha menos variación.
Ejemplo:
Suponga que tiene un amigo (Sensor 2) que es bueno en matemáticas pero no tan bueno en física y usted (Sensor 1) es bueno en física pero no tanto en matemáticas. Ahora, el día del examen, cuando tu objetivo está obteniendo un buen resultado, tú y tu amigo se unen para sobresalir en ambas materias. Ambos colaboran para minimizar el error y maximizar el resultado (salida).
Ejemplo:
es como cuando necesita averiguar sobre un incidente, le pregunta a diferentes personas al respecto y, después de escuchar todas sus historias, crea la suya propia, que parece ser mucho más precisa que cualquiera de las historias individuales. Ver siempre está relacionado con nuestra vida diaria y siempre podemos hacer una conexión con lo que ya hemos experimentado.
Código: implementación de Python del filtro 1-D Kalman
def update(mean1, var1, mean2, var2): new_mean = float(var2 * mean1 + var1 * mean2) / (var1 + var2) new_var = 1./(1./var1 + 1./var2) return [new_mean, new_var] def predict(mean1, var1, mean2, var2): new_mean = mean1 + mean2 new_var = var1 + var2 return [new_mean, new_var] measurements = [5., 6., 7., 9., 10.] motion = [1., 1., 2., 1., 1.] measurement_sig = 4. motion_sig = 2. mu = 0. sig = 10000. # print out ONLY the final values of the mean although for a better understanding you may choose to # and the variance in a list [mu, sig]. for measurement, motion in zip(measurements, motion): mu, sig = update(measurement, measurement_sig, mu, sig) mu, sig = predict(motion, motion_sig, mu, sig) print([mu, sig])
Explicación:
Como hemos discutido, hay dos pasos principales en el proceso completo, primero el paso de actualización y luego el paso de predicción. Estos dos pasos se repiten una y otra vez para estimar la posición exacta del robot.
El paso de predicción:
la nueva posición p’ se puede calcular usando la fórmula
donde p es la posición anterior, v es la velocidad y dt es el paso de tiempo.
la nueva velocidad v’ será la misma que la velocidad anterior como su constante (suposición). Esto en la ecuación se puede dar como
Ahora a escribir esta cosa completa en una sola array.
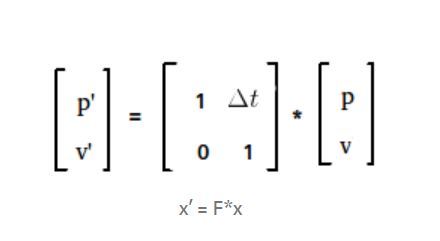
Paso de predicción
El paso de actualización:
el filtro que acaba de implementar está en python y también en 1-D. Mayormente tratamos con más de una dimensión y el lenguaje cambia para la misma. Así que implementemos un filtro de Kalman en C++.
Requisito:
Biblioteca Eigen
Necesitará la biblioteca Eigen, especialmente la clase Dense para poder trabajar con el álgebra lineal requerida en el proceso. Descargue la biblioteca y péguela en la carpeta que contiene los archivos de código, en caso de que no sepa cómo funcionan las bibliotecas en C++. Consulte también la documentación oficial para comprender mejor cómo utilizar su funcionalidad. Tengo que admitir que la forma en que lo han explicado en la documentación es increíble y mejor que cualquier tutorial que puedas pedir.
Ahora, implementando la misma función de predicción y actualización en c ++ usando esta nueva arma (biblioteca) que hemos encontrado para lidiar con la parte de álgebra en el proceso.
Paso de predicción:
P’ = F * P * F.transponer() + Q
Aquí
Bu se convierte en cero
ya que esto se usa para incorporar cambios relacionados con la fricción o cualquier otra fuerza que sea difícil de calcular.
v es el ruido del proceso
lo que determina el ruido aleatorio que puede estar presente en el sistema como un todo.
void KalmanFilter::Predict()
{
x = F * x;
MatrixXd Ft = F.transpose();
P = F * P * Ft + Q;
}
Con eso, pudimos calcular el valor predicho de X y la array de covarianza P.
Paso de actualización:
dónde
w
representa sensor
ruido de medición.
Entonces, para lidar, la función de medición se ve así:
También se puede representar en forma matricial:
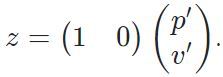
Representación en forma de array
En este paso, usamos las últimas mediciones para actualizar nuestra estimación y nuestra incertidumbre.
H es la función de medición que asigna el estado a la medición y ayuda a calcular el error (y) comparando la medición (z) con nuestra predicción (H*x).
El error se mapea en una array S, que se obtiene proyectando el
Incertidumbre del sistema (P)
en el espacio de medición usando la función de medición (H) + Array
R
esos personajes
Ruido de medición.
Esto luego se mapea en la variable llamada K.
K es la ganancia de Kalman
y decide si se debe dar más peso a la medida tomada oa la predicción según los datos anteriores y su incertidumbre.
Y finalmente nosotros
actualizar nuestra estimación (x) y nuestra incertidumbre (P)
usando esta ecuación usando la ganancia de Kalman.
x = x + (k * y)
pags = (yo – k * h) * pags
Aquí
yo
es una array identidad.
void KalmanFilter::Update(const VectorXd& z)
{
VectorXd z_pred = H * x;
VectorXd y = z - z_pred;
MatrixXd Ht = H.transpose();
MatrixXd S = H * P * Ht + R;
MatrixXd Si = S.inverse();
MatrixXd PHt = P * Ht;
MatrixXd K = PHt * Si;
// new estimate
x = x + (K * y);
long x_size = x_.size();
MatrixXd I = MatrixXd::Identity(x_size, x_size);
P = (I - K * H) * P;
}
Código:
// create a 4D state vector, we don't know yet the values of the x state x = VectorXd(4); // state covariance matrix P P = MatrixXd(4, 4); P << 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1000, 0, 0, 0, 0, 1000; // measurement covariance R = MatrixXd(2, 2); R << 0.0225, 0, 0, 0.0225; // measurement matrix H = MatrixXd(2, 4); H << 1, 0, 0, 0, 0, 1, 0, 0; // the initial transition matrix F F = MatrixXd(4, 4); F << 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1; // set the acceleration noise components noise_ax = 5; noise_ay = 5;
La razón por la que no inicialicé las arrays al principio es que esa no es la parte principal mientras escribimos un filtro de Kalman. Primero, debemos saber cómo funcionan las dos funciones principales. luego viene la inicialización y otras cosas.
Algunos inconvenientes :
Publicación traducida automáticamente
Artículo escrito por amankrsharma3 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA