En este artículo, vamos a ver cómo detectar manos usando Python.
Usaremos las bibliotecas mediapipe y OpenCV en python para detectar la mano derecha y la mano izquierda. Usaremos el modelo Hands de las soluciones de mediapipe para detectar manos, es un modelo de detección de palma que opera en la imagen completa y devuelve un cuadro delimitador de mano orientado.
Bibliotecas requeridas
- Mediapipe es el marco de código abierto de Google, que se utiliza para el procesamiento de medios. Es multiplataforma o podemos decir que es amigable con la plataforma. Puede ejecutarse en Android, iOS y la web, eso es lo que significa multiplataforma, para ejecutarse en todas partes.
- OpenCV es una biblioteca de Python que está diseñada para resolver problemas de visión por computadora. OpenCV admite una amplia variedad de lenguajes de programación como C++, Python, Java, etc. Compatibilidad con múltiples plataformas, incluidas Windows, Linux y MacOS.
Instalación de bibliotecas necesarias
pip install mediapipe pip install opencv-python
Implementación paso a paso
Paso 1: importa todas las bibliotecas requeridas
Python3
# Importing Libraries import cv2 import mediapipe as mp # Used to convert protobuf message # to a dictionary. from google.protobuf.json_format import MessageToDict
Paso 2: Inicializar el modelo Hands
Python3
# Initializing the Model mpHands = mp.solutions.hands hands = mpHands.Hands( static_image_mode=False, model_complexity=1 min_detection_confidence=0.75, min_tracking_confidence=0.75, max_num_hands=2)
Veamos los parámetros para el modelo de manos:
Manos (static_image_mode=False, model_complexity=1 min_detection_confidence=0.75, min_tracking_confidence=0.75, max_num_hands=2)
Dónde:
- static_image_mode : se usa para especificar si la imagen de entrada debe ser una imagen estática o una transmisión de video. El valor predeterminado es Falso.
- model_complexity : Complejidad del modelo de punto de referencia de la mano: 0 o 1. La precisión del punto de referencia, así como la latencia de inferencia, generalmente aumentan con la complejidad del modelo. Predeterminado a 1.
- min_detection_confidence : se utiliza para especificar el valor mínimo de confianza con el que la detección del modelo de detección de personas debe considerarse exitosa. Puede especificar un valor en [0.0,1.0]. El valor predeterminado es 0,5.
- min_tracking_confidence : Se utiliza para especificar el valor mínimo de confianza con el que se debe considerar exitosa la detección del modelo de seguimiento de hitos. Puede especificar un valor en [0.0,1.0]. El valor predeterminado es 0,5.
- max_num_hands : Número máximo de manos a detectar. Por defecto es 2.
Paso 3: el modelo de manos procesa la imagen y detecta las manos
Capture los fotogramas continuamente desde la cámara usando OpenCV y luego voltee la imagen alrededor del eje y, es decir, cv2.flip (imagen, código de giro) y convierta la imagen BGR en una imagen RGB y haga predicciones usando el modelo de manos inicializado.
La predicción hecha por el modelo se guarda en la variable de resultados desde la cual podemos acceder a los puntos de referencia usando results.multi_hand_landmarks, results.multi_handedness respectivamente y Si las manos están presentes en el marco, verifique ambas manos, si es así, coloque el texto «Both Hands» en la imagen de lo contrario para una sola mano, almacene la función MessageToDict() en la variable de etiqueta. Si la etiqueta es «Izquierda», coloque el texto «Mano izquierda» en la imagen y si la etiqueta es «Derecha», coloque el texto «Mano derecha» en la imagen.
Python3
# Start capturing video from webcam
cap = cv2.VideoCapture(0)
while True:
# Read video frame by frame
success, img = cap.read()
# Flip the image(frame)
img = cv2.flip(img, 1)
# Convert BGR image to RGB image
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Process the RGB image
results = hands.process(imgRGB)
# If hands are present in image(frame)
if results.multi_hand_landmarks:
# Both Hands are present in image(frame)
if len(results.multi_handedness) == 2:
# Display 'Both Hands' on the image
cv2.putText(img, 'Both Hands', (250, 50),
cv2.FONT_HERSHEY_COMPLEX, 0.9,
(0, 255, 0), 2)
# If any hand present
else:
for i in results.multi_handedness:
# Return whether it is Right or Left Hand
label = MessageToDict(i)[
'classification'][0]['label']
if label == 'Left':
# Display 'Left Hand' on left side of window
cv2.putText(img, label+' Hand', (20, 50),
cv2.FONT_HERSHEY_COMPLEX, 0.9,
(0, 255, 0), 2)
if label == 'Right':
# Display 'Left Hand' on left side of window
cv2.putText(img, label+' Hand', (460, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# Display Video and when 'q' is entered, destroy the window
cv2.imshow('Image', img)
if cv2.waitKey(1) & 0xff == ord('q'):
break
A continuación se muestra la implementación completa:
Python3
# Importing Libraries
import cv2
import mediapipe as mp
# Used to convert protobuf message to a dictionary.
from google.protobuf.json_format import MessageToDict
# Initializing the Model
mpHands = mp.solutions.hands
hands = mpHands.Hands(
static_image_mode=False,
model_complexity=1
min_detection_confidence=0.75,
min_tracking_confidence=0.75,
max_num_hands=2)
# Start capturing video from webcam
cap = cv2.VideoCapture(0)
while True:
# Read video frame by frame
success, img = cap.read()
# Flip the image(frame)
img = cv2.flip(img, 1)
# Convert BGR image to RGB image
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Process the RGB image
results = hands.process(imgRGB)
# If hands are present in image(frame)
if results.multi_hand_landmarks:
# Both Hands are present in image(frame)
if len(results.multi_handedness) == 2:
# Display 'Both Hands' on the image
cv2.putText(img, 'Both Hands', (250, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# If any hand present
else:
for i in results.multi_handedness:
# Return whether it is Right or Left Hand
label = MessageToDict(i)
['classification'][0]['label']
if label == 'Left':
# Display 'Left Hand' on
# left side of window
cv2.putText(img, label+' Hand',
(20, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
if label == 'Right':
# Display 'Left Hand'
# on left side of window
cv2.putText(img, label+' Hand', (460, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# Display Video and when 'q'
# is entered, destroy the window
cv2.imshow('Image', img)
if cv2.waitKey(1) & 0xff == ord('q'):
break
Producción:
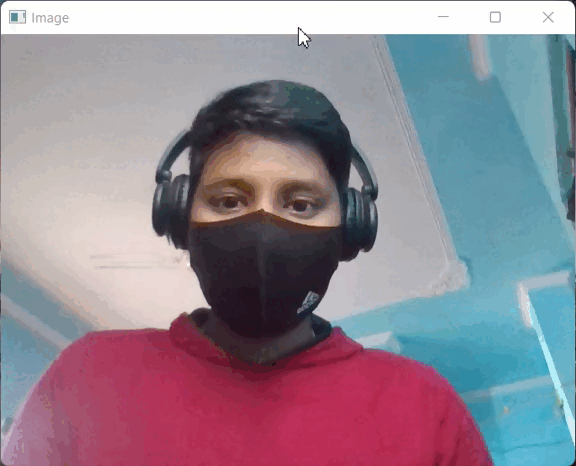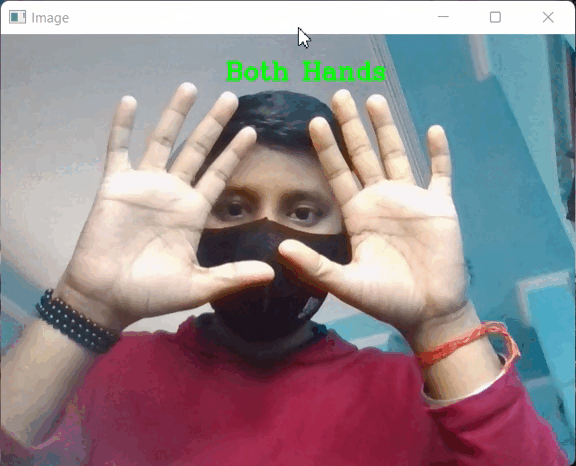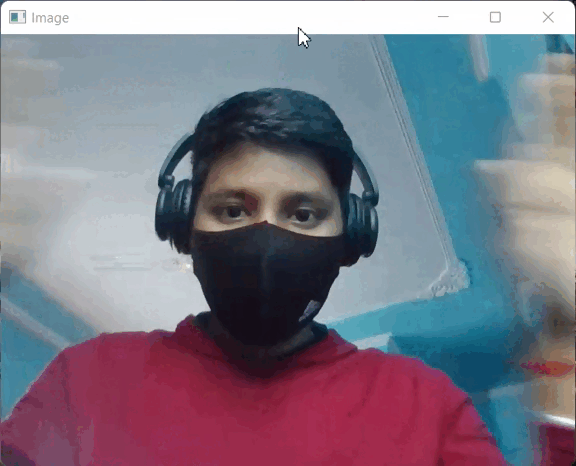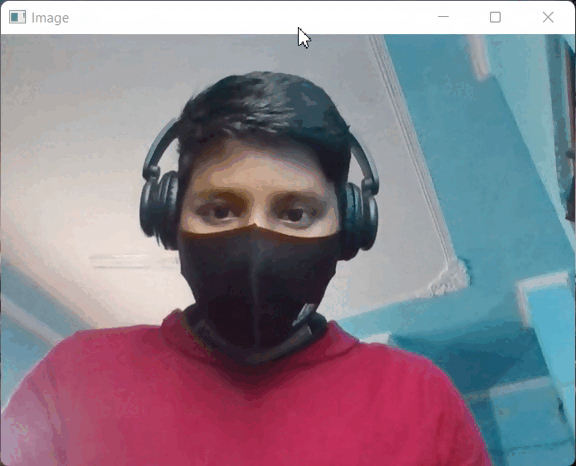
PRODUCCIÓN