OpenCV (visión por computadora de código abierto) es una biblioteca de funciones de programación destinadas principalmente a la visión por computadora en tiempo real. OpenCV en python ayuda a procesar una imagen y aplicar varias funciones como cambiar el tamaño de la imagen, manipulación de píxeles, detección de objetos, etc. En este artículo, aprenderemos cómo usar contornos para detectar el texto en una imagen y guardarlo en un archivo de texto.
Instalaciones requeridas:
pip install opencv-python pip install pytesseract
El paquete OpenCV se utiliza para leer una imagen y realizar ciertas técnicas de procesamiento de imágenes. Python-tesseract es un contenedor para el motor Tesseract-OCR de Google que se utiliza para reconocer texto de imágenes.
Descargue el archivo ejecutable tesseract desde este enlace .
Enfoque:
después de las importaciones necesarias, se lee una imagen de muestra utilizando la función imread de opencv.
Aplicación de procesamiento de imagen para la imagen:
El espacio de color de la imagen se cambia primero y se almacena en una variable. Para la conversión de color usamos la función cv2.cvtColor(input_image, flag). El indicador del segundo parámetro determina el tipo de conversión. Podemos elegir entre cv2.COLOR_BGR2GRAY y cv2.COLOR_BGR2HSV . cv2.COLOR_BGR2GRAY nos ayuda a convertir una imagen RGB en una imagen en escala de grises y cv2.COLOR_BGR2HSV se utiliza para convertir una imagen RGB en una imagen de espacio de color HSV (tono, saturación, valor). Aquí usamos cv2.COLOR_BGR2GRAY . Se aplica un umbral a la imagen convertida mediante la función cv2.threshold.
Hay 3 tipos de umbralización:
- Umbral simple
- Umbral adaptativo
- Binarización de Otsu
Para obtener más información sobre el umbral, consulte Técnicas de umbral mediante OpenCV .
cv2.threshold() tiene 4 parámetros, el primer parámetro es la imagen con cambio de espacio de color, seguido del valor de umbral mínimo, el valor de umbral máximo y el tipo de umbral que debe aplicarse.
Para obtener una estructura rectangular:
cv2.getStructuringElement() se usa para definir un elemento estructural como elíptico, circular, rectangular, etc. Aquí, usamos el elemento estructural rectangular (cv2.MORPH_RECT). cv2.getStructuringElement toma un tamaño adicional del parámetro del kernel . Un kernel más grande agruparía bloques de texto más grandes. Después de elegir el kernel correcto, la dilatación se aplica a la imagen con la función cv2.dilate. La dilatación hace que los grupos de texto se detecten con mayor precisión ya que dilata (expande) un bloque de texto.
Encontrar contornos:
cv2.findContours() se usa para encontrar contornos en la imagen dilatada. Hay tres argumentos en cv.findContours(): la imagen de origen, el modo de recuperación de contorno y el método de aproximación de contorno.
Esta función devuelve contornos y jerarquía. Contornos es una lista de Python de todos los contornos de la imagen. Cada contorno es una array Numpy de coordenadas (x, y) de puntos límite en el objeto. Los contornos se utilizan normalmente para encontrar un objeto blanco en un fondo negro. Todas las técnicas de procesamiento de imágenes anteriores se aplican para que los contornos puedan detectar los bordes de los límites de los bloques de texto de la imagen. Un archivo de texto se abre en modo de escritura y se vacía. Este archivo de texto se abre para guardar el texto de la salida del OCR.
Aplicación de reconocimiento óptico de caracteres:
Recorra cada contorno y tome las coordenadas x e y y el ancho y alto usando la función cv2.boundingRect(). Luego dibuje un rectángulo en la imagen usando la función cv2.rectangle() con la ayuda de las coordenadas x e y obtenidas y el ancho y alto. Hay 5 parámetros en cv2.rectangle(), el primer parámetro especifica la imagen de entrada, seguido de las coordenadas x e y (coordenadas iniciales del rectángulo), las coordenadas finales del rectángulo que es (x+w, y+ h), el color del límite del rectángulo en valor RGB y el tamaño del límite. Ahora recorta la región rectangular y luego pásala al teseracto para extraer el texto de la imagen. Luego, abrimos el archivo de texto creado en modo agregar para agregar el texto obtenido y cerrar el archivo.
Imagen de muestra utilizada para el código:

Python3
# Import required packages
import cv2
import pytesseract
# Mention the installed location of Tesseract-OCR in your system
pytesseract.pytesseract.tesseract_cmd = 'System_path_to_tesseract.exe'
# Read image from which text needs to be extracted
img = cv2.imread("sample.jpg")
# Preprocessing the image starts
# Convert the image to gray scale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Performing OTSU threshold
ret, thresh1 = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV)
# Specify structure shape and kernel size.
# Kernel size increases or decreases the area
# of the rectangle to be detected.
# A smaller value like (10, 10) will detect
# each word instead of a sentence.
rect_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (18, 18))
# Applying dilation on the threshold image
dilation = cv2.dilate(thresh1, rect_kernel, iterations = 1)
# Finding contours
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_NONE)
# Creating a copy of image
im2 = img.copy()
# A text file is created and flushed
file = open("recognized.txt", "w+")
file.write("")
file.close()
# Looping through the identified contours
# Then rectangular part is cropped and passed on
# to pytesseract for extracting text from it
# Extracted text is then written into the text file
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Drawing a rectangle on copied image
rect = cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Cropping the text block for giving input to OCR
cropped = im2[y:y + h, x:x + w]
# Open the file in append mode
file = open("recognized.txt", "a")
# Apply OCR on the cropped image
text = pytesseract.image_to_string(cropped)
# Appending the text into file
file.write(text)
file.write("\n")
# Close the file
file.close
Salida:
archivo de texto final:
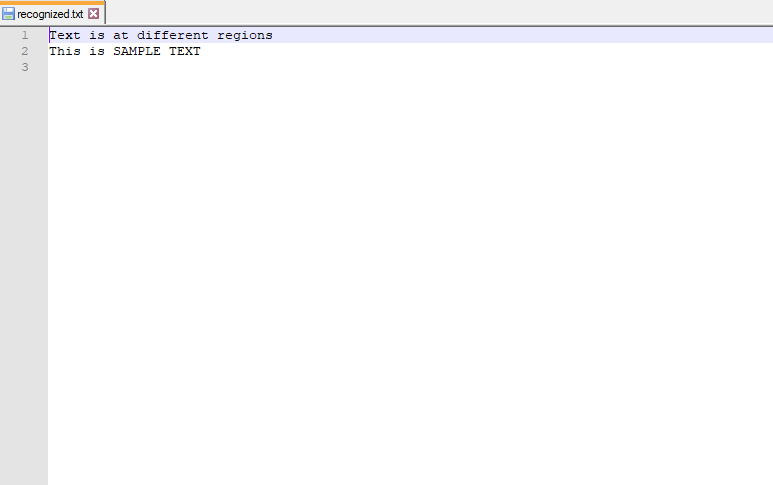
Bloques de texto detectados:

Publicación traducida automáticamente
Artículo escrito por AnandhJagadeesan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA