Un valor atípico es un elemento/objeto de datos que se desvía significativamente del resto de los objetos (llamados normales). Pueden ser causados por errores de medición o de ejecución. El análisis para la detección de valores atípicos se denomina minería de valores atípicos. Hay muchas formas de detectar los valores atípicos, y el proceso de eliminación es el marco de datos igual que eliminar un elemento de datos del marco de datos del panda.
Aquí, el marco de datos de pandas se usa para un enfoque más realista, ya que en el proyecto del mundo real es necesario detectar los valores atípicos que surgen durante el paso de análisis de datos, el mismo enfoque se puede usar en listas y objetos de tipo serie.
Conjunto de datos:
El conjunto de datos utilizado es el conjunto de datos de viviendas de Boston, ya que está precargado en la biblioteca sklearn.
Python3
# Importing import sklearn from sklearn.datasets import load_boston import pandas as pd import matplotlib.pyplot as plt # Load the dataset bos_hou = load_boston() # Create the dataframe column_name = bos_hou.feature_names df_boston = pd.DataFrame(bos_hou.data) df_boston.columns = column_name df_boston.head()
Producción:
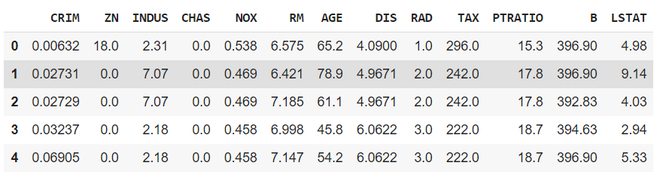
parte del conjunto de datos
Detección de valores atípicos
Los valores atípicos se pueden detectar mediante visualización, implementando fórmulas matemáticas en el conjunto de datos o utilizando el enfoque estadístico. Todos estos se discuten a continuación.
1. Visualización
Ejemplo 1: uso de diagrama de caja
Captura el resumen de los datos de manera efectiva y eficiente con solo una simple caja y bigotes. Boxplot resume los datos de muestra utilizando los percentiles 25, 50 y 75. Uno puede simplemente obtener información (cuartiles, mediana y valores atípicos) en el conjunto de datos con solo mirar su diagrama de caja.
Python3
# Box Plot import seaborn as sns sns.boxplot(df_boston['DIS'])
Salida :
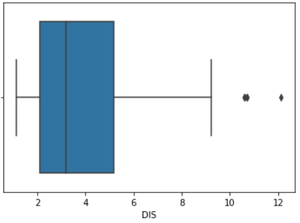
Diagrama de caja: columna DIS
En el gráfico anterior, puede ver claramente que los valores superiores a 10 actúan como valores atípicos.
Python3
# Position of the Outlier print(np.where(df_boston['DIS']>10))
Producción:
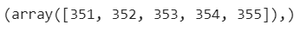
Índice de valores atípicos
Ejemplo 2: Uso de ScatterPlot .
Se usa cuando tiene datos numéricos emparejados, o cuando su variable dependiente tiene valores múltiples para cada variable independiente de lectura, o cuando intenta determinar la relación entre las dos variables. En el proceso de utilizar el gráfico de dispersión, también se puede utilizar para la detección de valores atípicos.
Para trazar el diagrama de dispersión, se requieren dos variables que de alguna manera estén relacionadas entre sí. Así que aquí, se utilizan ‘Proporción de acres comerciales no minoristas por ciudad’ y ‘Tasa de impuesto a la propiedad de valor total por $10,000’ cuyos nombres de columna son «INDUS» e «TAX» respectivamente.
Python3
# Scatter plot
fig, ax = plt.subplots(figsize = (18,10))
ax.scatter(df_boston['INDUS'], df_boston['TAX'])
# x-axis label
ax.set_xlabel('(Proportion non-retail business acres)/(town)')
# y-axis label
ax.set_ylabel('(Full-value property-tax rate)/( $10,000)')
plt.show()
Salida :
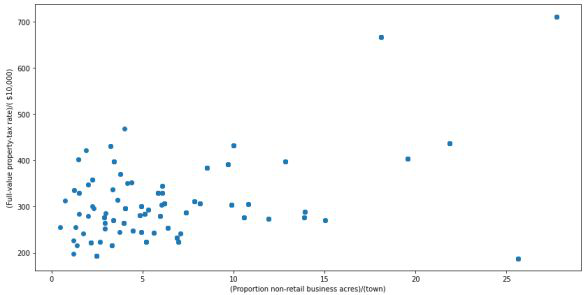
Gráfico de dispersión
Mirar el gráfico puede resumir que la mayoría de los puntos de datos están en la esquina inferior izquierda del gráfico, pero hay algunos puntos que son exactamente opuestos a la esquina superior derecha del gráfico. Esos puntos en la esquina superior derecha se pueden considerar valores atípicos.
El uso de la aproximación puede decir que todos los puntos de datos que son x> 20 e y> 600 son valores atípicos. El siguiente código puede obtener la posición exacta de todos aquellos puntos que cumplan estas condiciones.
Python3
# Position of the Outlier print(np.where((df_boston['INDUS']>20) & (df_boston['TAX']>600)))
Salida :
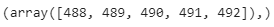
Índice de valores atípicos
2. Puntuación Z
La puntuación Z también se denomina puntuación estándar. Este valor/puntuación ayuda a comprender qué tan lejos está el punto de datos de la media. Y después de configurar un valor de umbral, se pueden utilizar los valores de puntuación z de los puntos de datos para definir los valores atípicos.
Puntuación Z = (punto_datos -media) / std. desviación
Python3
# Z score from scipy import stats import numpy as np z = np.abs(stats.zscore(df_boston['DIS'])) print(z)
Salida :

parte de la lista (z)
El resultado anterior es solo una instantánea de parte de los datos; la longitud real de la lista (z) es 506, que es el número de filas. Imprime los valores de puntuación z de cada elemento de datos de la columna
Ahora, para definir un valor de umbral atípico, se elige que generalmente es 3.0. Como el 99,7% de los puntos de datos se encuentran entre +/- 3 desviaciones estándar (usando el enfoque de distribución gaussiana).
Python3
threshold = 3 # Position of the outlier print(np.where(z > 3))
Producción:
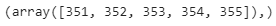
Índice de valores atípicos
3. IQR (rango intercuartílico)
IQR (rango intercuartílico) El enfoque de rango intercuartílico para encontrar los valores atípicos es el enfoque más utilizado y confiable en el campo de la investigación.
IQR = Cuartil3 – Cuartil1
Python3
# IQR Q1 = np.percentile(df_boston['DIS'], 25, interpolation = 'midpoint') Q3 = np.percentile(df_boston['DIS'], 75, interpolation = 'midpoint') IQR = Q3 - Q1
Producción:
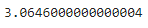
Para definir el valor base de valores atípicos se define por encima y por debajo del rango normal de los conjuntos de datos, es decir, los límites superior e inferior, defina el límite superior e inferior (se considera el valor 1.5*IQR):
superior = Q3 +1.5*RIC
inferior = Q1 – 1.5*RIQ
En la fórmula anterior, según las estadísticas, se toma el aumento de escala de 0,5 de IQR (new_IQR = IQR + 0,5*IQR), para considerar todos los datos entre 2,7 desviaciones estándar en la Distribución Gaussiana.
Python3
# Above Upper bound
upper = df_boston['DIS'] >= (Q3+1.5*IQR)
print("Upper bound:",upper)
print(np.where(upper))
# Below Lower bound
lower = df_boston['DIS'] <= (Q1-1.5*IQR)
print("Lower bound:", lower)
print(np.where(lower))
Producción:
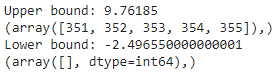
Límites definidos e índice de valores atípicos correspondiente a los límites
Eliminando los valores atípicos
Para eliminar el valor atípico, se debe seguir el mismo proceso de eliminar una entrada del conjunto de datos usando su posición exacta en el conjunto de datos porque en todos los métodos anteriores para detectar los valores atípicos, el resultado final es la lista de todos los elementos de datos que satisfacen la definición de valor atípico. según el método utilizado.
Referencias: ¿Cómo eliminar exactamente una fila en python?
dataframe.drop(row_index, inplace = True
El código anterior se puede usar para eliminar una fila del conjunto de datos dados los índices de fila que se eliminarán. Inplace =True se usa para decirle a Python que realice el cambio requerido en el conjunto de datos original. row_index puede ser solo un valor o una lista de valores o una array NumPy, pero debe ser unidimensional.
Ejemplo:
df_boston.drop(listas[0],inplace = True)
Código completo : detectar los valores atípicos mediante IQR y eliminarlos.
Python3
# Importing
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
# Load the dataset
bos_hou = load_boston()
# Create the dataframe
column_name = bos_hou.feature_names
df_boston = pd.DataFrame(bos_hou.data)
df_boston.columns = column_name
df_boston.head()
''' Detection '''
# IQR
Q1 = np.percentile(df_boston['DIS'], 25,
interpolation = 'midpoint')
Q3 = np.percentile(df_boston['DIS'], 75,
interpolation = 'midpoint')
IQR = Q3 - Q1
print("Old Shape: ", df_boston.shape)
# Upper bound
upper = np.where(df_boston['DIS'] >= (Q3+1.5*IQR))
# Lower bound
lower = np.where(df_boston['DIS'] <= (Q1-1.5*IQR))
''' Removing the Outliers '''
df_boston.drop(upper[0], inplace = True)
df_boston.drop(lower[0], inplace = True)
print("New Shape: ", df_boston.shape)
Salida :
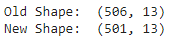
Publicación traducida automáticamente
Artículo escrito por rajeshsharma7 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA