La forma general de reconocer el tipo de archivo es mirando su extensión. Pero esto no es generalmente el caso. Algunas familias de sistemas operativos (principalmente Windows) imponen este tipo de estándar para reconocer archivos mediante la asociación de una extensión con un tipo de archivo. Otros sistemas operativos como Linux (y sus variantes) usan el número mágico para reconocer los tipos de archivos. Un Número Mágico es un valor constante, utilizado para la identificación de un archivo. Este método brinda más flexibilidad para nombrar un archivo y no exige la presencia de una extensión. Los números mágicos son buenos para reconocer archivos, ya que a veces es posible que un archivo no tenga la extensión de archivo correcta (o que no tenga ninguna).
En este artículo aprenderemos a reconocer archivos por su extensión, usando python. Estaríamos usando la biblioteca Python Magic para proporcionar tales capacidades a nuestro programa. Para instalar la biblioteca, ejecute el siguiente comando en el intérprete de comandos de su sistema operativo:
pip install python-magic
Para fines de demostración, usaríamos un nombre de archivo pple.jpg con los siguientes contenidos:-
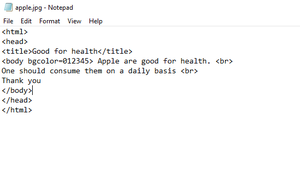
Aparentemente por el contenido, el archivo es un archivo HTML. Pero dado que se guarda con una extensión .jpg, el sistema operativo no podrá reconocer su tipo de archivo real. Entonces este archivo sería apropiado para nuestro programa.
Python3
import magic
# printing the human readable type of the file
print(magic.from_file('apple.jpg'))
# printing the mime type of the file
print(magic.from_file('apple.jpg', mime = True))
Producción:
HTML document, ASCII text, with CRLF line terminators text/html
Explicación:
En primer lugar, importamos la biblioteca mágica . Luego usamos el método magic.from_file() para lograr el tipo de archivo legible por humanos. Después de lo cual usamos el atributo mime=True para obtener el tipo mime del archivo.
Cosas a considerar al usar el código anterior:
- El código funciona en Linux y Mac OS. Pero existe un comando de terminal incorporado llamado archivo en esos sistemas operativos, que proporciona la misma funcionalidad que este programa, sin instalar ninguna otra biblioteca.
- El reconocimiento de tipo de archivo mediante extensiones también existe en las versiones más recientes de la biblioteca.
- Dado que el reconocimiento del tipo de archivo generalmente ocurre mediante la búsqueda de huellas dactilares en el encabezado del archivo, no es obligatorio cargar todo el archivo para el reconocimiento del tipo. También se pueden proporcionar pequeñas secciones de los archivos como argumento usando magic.from_buffer() y pasando los bytes iniciales del archivo usando open(‘file.ext’, ‘rb’).read(n) (Solo recomendado si conoce el formato de encabezado del tipo de archivo).