Plotly es una biblioteca de Python que se utiliza para diseñar gráficos, especialmente gráficos interactivos. Puede trazar varios gráficos y tablas como histograma, diagrama de barras, diagrama de caja, diagrama de dispersión y muchos más. Se utiliza principalmente en el análisis de datos, así como en el análisis financiero. plotly es una biblioteca de visualización interactiva.
Gráfico de rayos de sol en Plotly
El gráfico Sunburst visualiza datos estratificados gradualmente desde las raíces hasta las hojas. La raíz comienza desde el centro y se agregan chorros a los anillos exteriores. Cada nivel de la jerarquía está representado por un anillo o círculo con el círculo más interno, los anillos adicionales se dividen en segmentos que representan puntos de datos y el tamaño del segmento representa valores de datos.
Sintaxis: plotly.express.sunburst(data_frame=Ninguno, nombres=Ninguno, valores=Ninguno, padres=Ninguno, ruta=Ninguno, ids=Ninguno, color=Ninguno, color_continuous_scale=Ninguno, range_color=Ninguno, color_continuous_midpoint=Ninguno, color_discrete_sequence= Ninguno, color_discrete_map={}, hover_name=Ninguno, hover_data=Ninguno, custom_data=Ninguno, etiquetas={}, título=Ninguno, plantilla=Ninguno, ancho=Ninguno, alto=Ninguno, branchvalues=Ninguno, profundidad máxima=Ninguno)
Parámetros:
data_frame: este argumento debe pasarse para que se utilicen los nombres de las columnas (y no los nombres de las palabras clave).
nombres: ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan como etiquetas para los sectores.
valores: ya sea un nombre de una columna en data_frame o una serie de pandas o un objeto tipo array. Los valores de esta columna o array_like se utilizan para establecer valores asociados a sectores.
padres: ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto similar a una array. Los valores de esta columna o array_like se utilizan como elementos primarios en los gráficos sunburst y treemap.
ruta: cualquiera de los nombres de las columnas en data_frame, o pandas Series, o array_like objects Lista de nombres de columnas o columnas de un marco de datos rectangular que define la jerarquía de sectores, desde la raíz hasta las hojas.
ids: ya sea un nombre de una columna en data_frame, o una serie de pandas o un objeto tipo array. Los valores de esta columna o array_like se usan para establecer ID de sectores
Ejemplo:
Python3
import plotly.express as px df = px.data.iris() fig = px.sunburst(df, path=['sepal_length', 'sepal_width', 'petal_length'], values='petal_width') fig.show()
Producción:
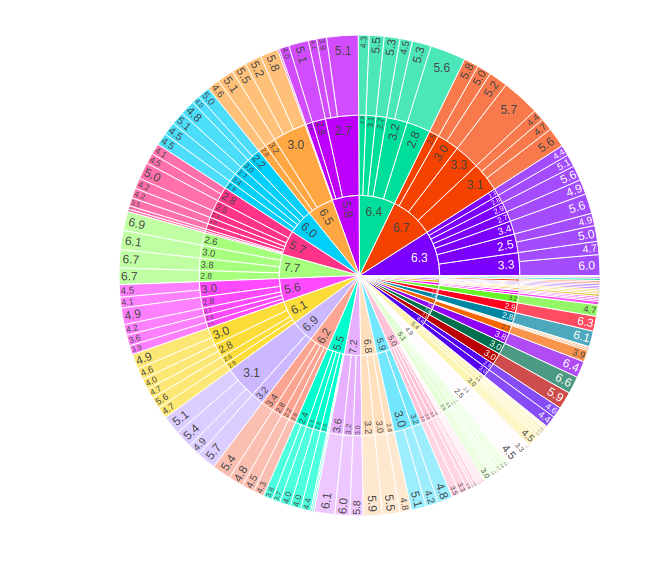
Trazado de datos jerárquicos
El marco de datos rectangular representa los datos jerárquicos donde diferentes columnas corresponden a diferentes niveles de jerarquía. Para trazar dichas columnas se utiliza el parámetro de ruta . El parámetro de ruta toma el nombre de las columnas en data_frame, o pandas Series, u objetos tipo array, lista de nombres de columnas o columnas de un marco de datos rectangular que define la jerarquía de sectores, desde la raíz hasta las hojas.
Nota: Cuando se pasan ID o padres junto con la ruta, se genera un error.
Ejemplo:
Python3
import plotly.express as px df = px.data.tips() fig = px.sunburst(df, path=['day', 'sex'], values='total_bill') fig.show()
Producción:
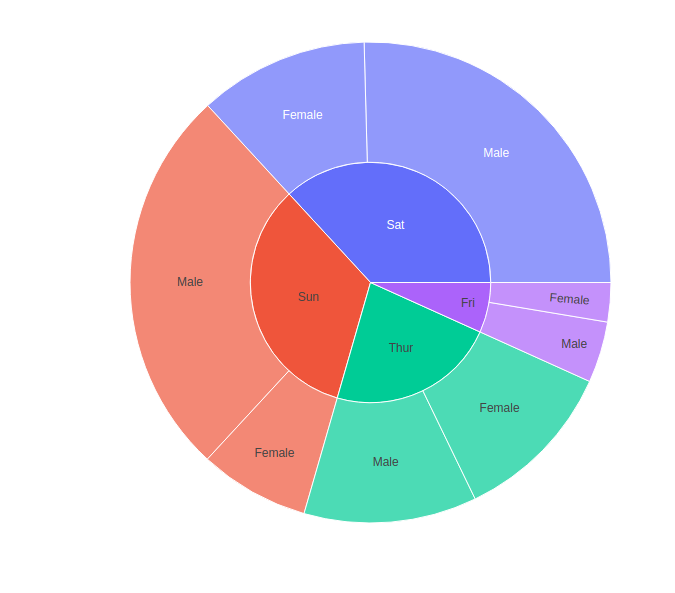
Trazado de datos jerárquicos con el argumento de color continuo
Si se pasa el argumento de color, el color del Node se calcula como los valores de color promedio de sus hijos por sus valores.
Ejemplo:
Python3
import plotly.express as px df = px.data.tips() fig = px.sunburst(df, path=['day', 'sex'], values='total_bill', color='total_bill') fig.show()
Producción:
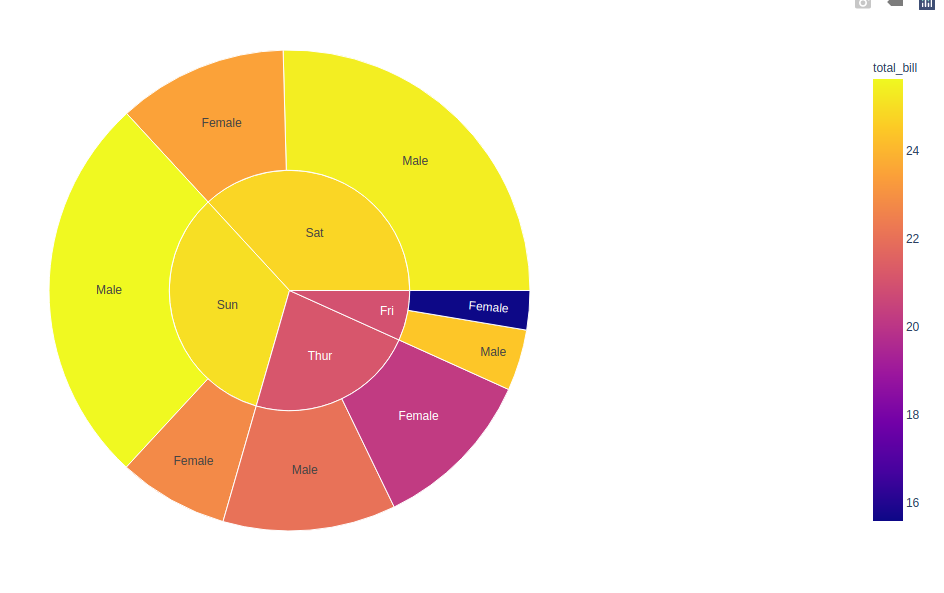
Trazado de datos jerárquicos con el argumento de color discreto
Cuando se pasan datos no numéricos al argumento de color, se utilizan datos discretos. Si una columna de color de un sector tiene el mismo valor para todos sus hijos, entonces se usa el color correspondiente; de lo contrario, se usará el mismo primer color del color discreto.
Ejemplo:
Python3
import plotly.express as px df = px.data.tips() fig = px.sunburst(df, path=['day', 'sex'], values='total_bill', color='time') fig.show()
Producción:
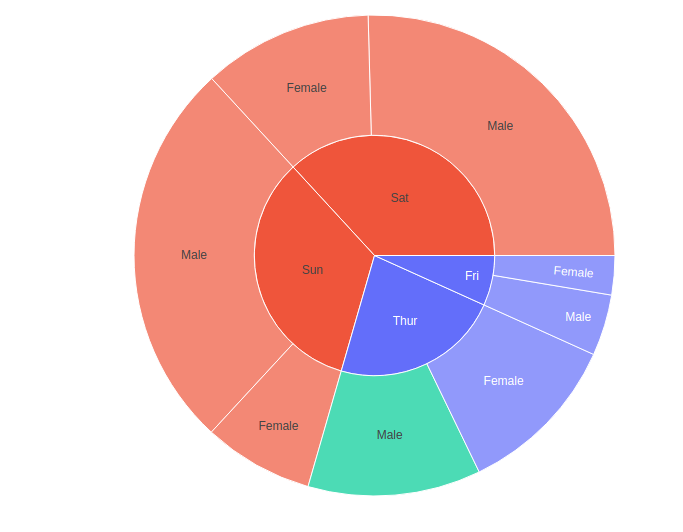
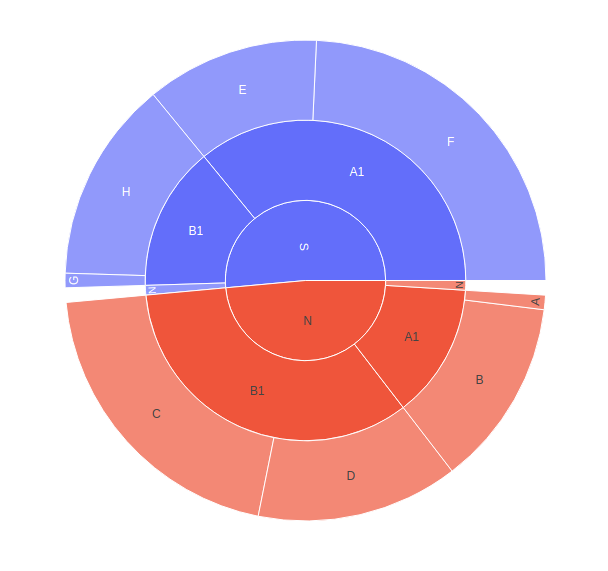
Trazado de datos jerárquicos con valores faltantes
Si el conjunto de datos no tiene una forma completamente rectangular, los valores faltantes deben mencionarse como ninguno. Ninguna entrada de los padres debe ser una hoja, de lo contrario, se generará valueError.
Ejemplo:
Python3
import plotly.express as px import pandas as pd A = ["A", "B", "C", "D", None, "E", "F", "G", "H", None] B = ["A1", "A1", "B1", "B1", "N", "A1", "A1", "B1", "B1", "N"] C = ["N", "N", "N", "N", "N", "S", "S", "S", "S", "S"] D = [1, 13, 21, 14, 1, 12, 25, 1, 14, 1] df = pd.DataFrame( dict(A=A, B=B, C=C, D=D) ) fig = px.sunburst(df, path=['C', 'B', 'A'], values='D') fig.show()
Producción:
Publicación traducida automáticamente
Artículo escrito por nishantsundriyal98 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA