1. Modelo de datos de red: es una versión avanzada del modelo de datos jerárquicos. Para organizar los datos, utiliza gráficos dirigidos en lugar de una estructura de árbol. En este niño puede tener más de un padre. Utiliza el concepto de dos estructuras de datos, es decir, Registros y Conjuntos. 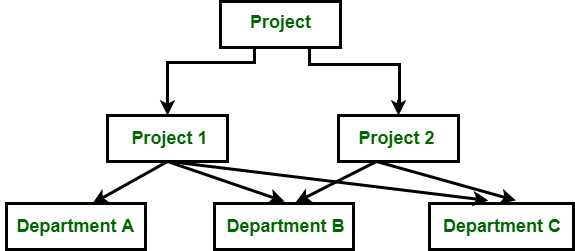
En la figura anterior, el Proyecto es un Node raíz que tiene dos hijos, es decir, el Proyecto 1 y el Proyecto 2. El Proyecto 1 tiene 3 hijos y el Proyecto 2 tiene 2 hijos. En total hay 5 hijos, es decir, Departamento A, Departamento B y Departamento C, son hijos relacionados con la red, ya que dijimos que este modelo puede tener más de un padre. Entonces, para el Departamento B y el Departamento C tienen dos padres, es decir, Proyecto 1 y Proyecto 2.
2. Modelo de datos relacionales : el modelo de datos relacionales fue desarrollado por EF Codd en 1970. No hay enlaces físicos como en el modelo de datos jerárquicos. Las siguientes son propiedades del modelo de datos relacionales:
- Los datos se representan únicamente en forma de tabla.
- Se trata sólo de datos, no de estructura física.
- Proporciona información sobre metadatos.
- En la intersección de la fila y la columna, solo habrá un valor para la tupla.
- Proporciona una manera de manejar las consultas con facilidad.
Difference between Network and Relational Data Model :
| Modelo de datos de red | Modelo de datos relacionales |
|---|---|
| Organiza registros entre sí a través de enlaces o punteros. | Organiza los registros en forma de tabla y la relación entre tablas se establece mediante campos comunes. |
| Organiza registros en forma de gráficos dirigidos. | Organiza registros en forma de tablas. |
| En esta relación entre varios registros se representa físicamente a través de una lista enlazada. | En esta relación entre varios registros se representa lógicamente a través de tablas. |
| Faltan instalaciones de consulta declarativas. | Proporciona facilidad de consulta declarativa usando SQL. |
| La complejidad aumenta la carga del programador para el diseño de la base de datos, así como para la manipulación de datos. | Como los detalles del nivel físico están ocultos para los usuarios finales, este modelo es muy simple de entender. |
| Los algoritmos de recuperación son complejos pero simétricos. | Los algoritmos de recuperación son simples y simétricos. |
| En este modelo hay una independencia parcial de los datos. | Este modelo proporciona independencia de datos. |
| VAX-DBMS, DMS-1100 de UNIVAC y SUPRADBMS utilizan este modelo. | Se utiliza principalmente en aplicaciones del mundo real. Oracle, SQL. |
Publicación traducida automáticamente
Artículo escrito por itskawal2000 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA