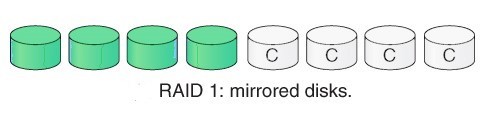
1. RAID 1:
RAID 1 también se denomina duplicación de datos. Porque replica los datos de la unidad 1 a la unidad 2. La mitad de la unidad se usa para almacenar los datos y la otra actúa como un espejo de los datos ya almacenados. Este nivel proporciona una redundancia del 100 % en caso de fallo.
Ventaja:
buena tolerancia a fallas, es decir. capacidad de mantener la funcionalidad incluso si un disco falla.
Desventaja:
es caro porque se requiere una unidad adicional para la duplicación.
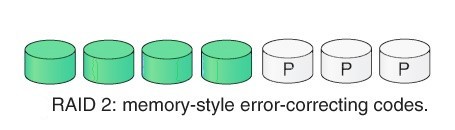
2. RAID 2:
RAID 2 consta de bandas a nivel de bits. Registra el código de corrección de errores (ECC) utilizando paridad de código Hamming. En este nivel, cada bit de datos de una palabra se graba en un disco separado y los códigos ECC de las palabras de datos se almacenan en un conjunto diferente de discos.
Ventaja:
en caso de corrección de errores, utiliza código hamming.
Desventaja:
tiene una estructura compleja y un alto costo debido a la unidad adicional.
Diferencia entre RAID 1 y RAID 2:
| NO SEÑOR. | RAID 1 | RAID 2 |
|---|---|---|
| 1. | RAID 1 significa Redundant Array of Independent Disk nivel 1. | RAID 2 significa Redundant Array of Independent Disk nivel 2. |
| 2. | En la tecnología RAID 1, se utiliza Disk Mirroring. | En la tecnología RAID 2, se utiliza el fraccionamiento a nivel de bits. |
| 3. | En RAID 1, la mitad de la unidad se usa para almacenar datos y la otra mitad es solo un espejo para los datos ya almacenados. | En RAID 2, cada bit de datos en una palabra se graba en un disco separado y los códigos ECC se almacenan en discos diferentes |
| 4. | Buena tolerancia a fallas en comparación con RAID 2. | La tolerancia a fallos no es tan buena. |
| 5. | No se utilizan códigos Hamming. | Los códigos Hamming se utilizan para la corrección de errores. |
| 6. | Se requiere unidad adicional para duplicar. | Se requiere unidad adicional para la corrección de errores. |
Publicación traducida automáticamente
Artículo escrito por nishthagoel712 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA