Según Arthur Samuel, «el aprendizaje automático permite que una máquina aprenda automáticamente de los datos, mejore el rendimiento de una experiencia y prediga cosas sin una programación explícita».
En palabras simples, cuando alimentamos los datos de entrenamiento al algoritmo de aprendizaje automático, este algoritmo producirá un modelo matemático y, con la ayuda del modelo matemático, la máquina hará una predicción y tomará una decisión sin ser programada explícitamente. Además, durante el entrenamiento de datos, cuanto más trabaje la máquina con ellos, más experiencia obtendrá y se producirá un resultado más eficiente.
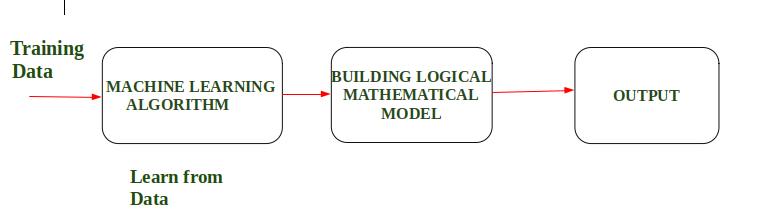
Ejemplo: en un automóvil sin conductor, los datos de entrenamiento se alimentan a un algoritmo, como conducir un automóvil en una autopista, una calle transitada y una calle estrecha con factores como el límite de velocidad, el estacionamiento, detenerse en la señal, etc. Después de eso, se crea un modelo lógico y matemático en el base de eso y después de eso, el coche funcionará de acuerdo con el modelo lógico. Además, cuantos más datos se alimentan, más eficiente es la producción.
Diseño de un sistema de aprendizaje en aprendizaje automático:
Según Tom Mitchell, “Se dice que un programa de computadora aprende de la experiencia (E), con respecto a alguna tarea (T). Así, la medida de desempeño (P) es el desempeño en la tarea T, que se mide por P, y mejora con la experiencia E”.
Ejemplo: en la detección de correo electrónico no deseado,
- Tarea, T: Clasificar los correos en Spam o No Spam.
- Medida de rendimiento, P: Porcentaje total de correos electrónicos que se clasifican correctamente como «Spam» o «No Spam».
- Experiencia, E: Conjunto de Correos con etiqueta “Spam”
Los pasos para diseñar un sistema de aprendizaje son:
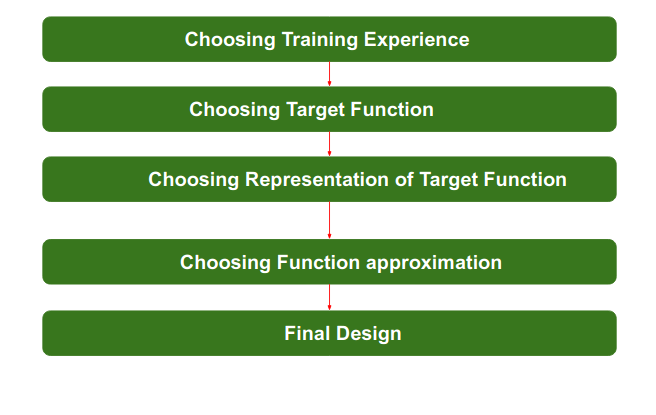
Paso 1) Elegir la experiencia de entrenamiento: la primera y muy importante tarea es elegir los datos de entrenamiento o la experiencia de entrenamiento que se alimentarán al algoritmo de aprendizaje automático. Es importante tener en cuenta que los datos o la experiencia que alimentamos al algoritmo deben tener un impacto significativo en el éxito o fracaso del modelo. Por lo tanto, los datos de entrenamiento o la experiencia deben elegirse sabiamente.
A continuación se muestran los atributos que afectarán el éxito y el fracaso de los datos:
- La experiencia de capacitación podrá proporcionar retroalimentación directa o indirecta con respecto a las opciones. Por ejemplo: mientras se juega al ajedrez, los datos de entrenamiento se retroalimentarán a sí mismos como en lugar de este movimiento, si se elige este, las posibilidades de éxito aumentan.
- El segundo atributo importante es el grado en que el alumno controlará las secuencias de ejemplos de entrenamiento. Por ejemplo: cuando los datos de entrenamiento se alimentan a la máquina, en ese momento la precisión es muy inferior, pero cuando gana experiencia mientras juega una y otra vez consigo misma o con el oponente, el algoritmo de la máquina obtendrá retroalimentación y controlará el juego de ajedrez en consecuencia.
- El tercer atributo importante es cómo representará la distribución de ejemplos sobre los cuales se medirá el desempeño. Por ejemplo, un algoritmo de aprendizaje automático obtendrá experiencia al pasar por una serie de casos diferentes y ejemplos diferentes. Por lo tanto, el algoritmo de aprendizaje automático obtendrá más y más experiencia al pasar por más y más ejemplos y, por lo tanto, aumentará su rendimiento.
Paso 2- Elegir la función objetivo: El siguiente paso importante es elegir la función objetivo. Significa que, de acuerdo con el conocimiento que se alimenta al algoritmo, el aprendizaje automático elegirá la función NextMove, que describirá qué tipo de movimientos legales se deben realizar. Por ejemplo: mientras juega al ajedrez con el oponente, cuando el oponente jugará, el algoritmo de aprendizaje automático decidirá cuál será la cantidad de movimientos legales posibles para tener éxito.
Paso 3: elegir la representación para la función objetivo: cuando el algoritmo de la máquina conozca todos los movimientos legales posibles, el siguiente paso es elegir el movimiento optimizado usando cualquier representación, es decir, usando ecuaciones lineales, representación gráfica jerárquica, forma tabular, etc. La función NextMove se moverá el objetivo se mueve como uno de estos movimientos, lo que proporcionará una mayor tasa de éxito. Por ejemplo: mientras juega al ajedrez, la máquina tiene 4 movimientos posibles, por lo que la máquina elegirá ese movimiento optimizado que le proporcionará éxito.
Paso 4: elección del algoritmo de aproximación de funciones: no se puede elegir un movimiento optimizado solo con los datos de entrenamiento. Los datos de entrenamiento tuvieron que pasar con un conjunto de ejemplos y, a través de estos ejemplos, los datos de entrenamiento se aproximarán a qué pasos se eligieron y luego la máquina proporcionará retroalimentación al respecto. Por ejemplo: cuando los datos de entrenamiento de jugar al ajedrez se alimentan al algoritmo, por lo que en ese momento no es una máquina, el algoritmo fallará o tendrá éxito y, nuevamente, a partir de ese fracaso o éxito, medirá en el próximo movimiento qué paso se debe elegir y cuál es su tasa de éxito.
Paso 5: diseño final: el diseño final se crea finalmente cuando el sistema pasa de una cantidad de ejemplos, fallas y éxitos, decisiones correctas e incorrectas y cuál será el siguiente paso, etc. Ejemplo: DeepBlue es una computadora inteligente que está basada en ML ganó una partida de ajedrez contra el experto en ajedrez Garry Kasparov, y se convirtió en la primera computadora que venció a un experto en ajedrez humano.
Publicación traducida automáticamente
Artículo escrito por jagroopofficial y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA