Los diseños experimentales son parte de ANOVA en estadística. Son algoritmos predefinidos que nos ayudan a analizar las diferencias entre las medias de los grupos en una unidad experimental. El diseño completamente aleatorio (CRD) es una parte de los tipos de Anova .
Diseño completamente aleatorizado:
Los tres principios básicos para diseñar un experimento son la replicación, el bloqueo y la aleatorización. En este tipo de diseño, el bloqueo no forma parte del algoritmo. Las muestras del experimento son aleatorias con repeticiones asignadas a diferentes unidades experimentales. Consideremos algunos experimentos a continuación e implementemos el experimento en la programación R.
Experimento 1
Agregar más polvo de hornear a los pasteles aumenta la altura del pastel. Veamos con CRD cómo se analizará el experimento.
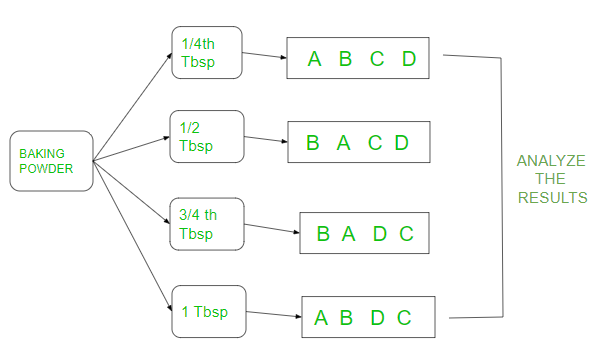
Como se muestra en la figura anterior, el polvo de hornear se divide en 4 cucharadas diferentes (cucharadas) y se hicieron cuatro alturas de pasteles replicadas (respectivamente para A, B, C, D) con cada cucharada en orden aleatorio. Luego se comparan los resultados de las cucharadas para ver si realmente la altura se ve afectada por el polvo de hornear. Las réplicas son solo permutaciones de las diferentes alturas de las tortas respectivamente para A, B, C, D. Veamos el ejemplo anterior en lenguaje R. Las alturas de cada pastel se anotan aleatoriamente para cada cucharada.
tbsp 0.25 0.5 0.75 1
1.4 7.8 7.6 1.6
#(A,B,C,D)
2.0 9.2 7.0 3.4
#(A,B,D,C)
2.3 6.8 7.3 3.0
#(B,A,D,C)
2.5 6.0 5.5 3.9 #(B,A,C,D)
# the randomization is done directly by the program
Las réplicas de los pasteles se realizan con el siguiente código:
R
treat <- rep(c("A", "B", "C", "D"), each = 4)
fac <- factor(rep(c(0.25, 0.5, 0.75, 1), each = 4))
treat
Producción:
[1] A A A A B B B B C C C C D D D D Levels: A B C D
Creando marco de datos:
R
height <- c(1.4, 2.0, 2.3, 2.5, 7.8, 9.2, 6.8, 6.0, 7.6, 7.0, 7.3, 5.5, 1.6, 3.4, 3.0, 3.9) exp <- data.frame(treat, treatment = fac, response = height) mod <- aov(response ~ treatment, data = exp) summary(mod)
Producción:
Df Sum Sq Mean Sq F value Pr(>F) treatment 3 88.46 29.486 29.64 7.85e-06 *** Residuals 12 11.94 0.995 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Explicación:
Para cada experimento, la significación es 0,05 o 0,01, que es dada por la persona que realiza el experimento. Para este ejemplo, consideremos la importancia como 5%, es decir, 0,05. Deberíamos ver el valor de Pr(>F) que es 7.85e-06, es decir, < 0.05. Por lo tanto, rechazar la hipótesis. Si el valor es > 0,05, entonces acepte la hipótesis. Para este ejemplo, como Pr < 0.05, rechace la hipótesis. Consideremos un ejemplo más:
Experimento 2
Agregar rocas al agua aumenta la altura del agua en el recipiente. Veamos este experimento en la figura de la siguiente manera:
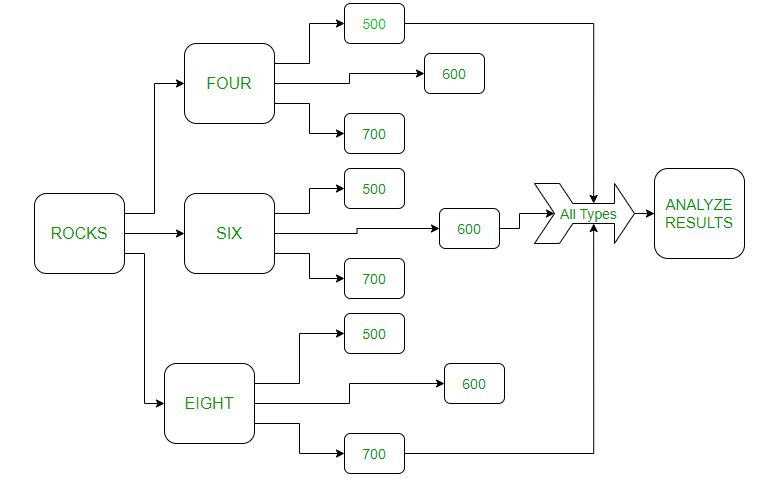
Considere que si agrega cuatro rocas a 500 ml, 600 ml y 700 ml, respectivamente, aumenta la altura del agua correspondientemente. Por ejemplo: agregar 6 rocas a 500 m de agua tiene 7 ms de altura aumentada.
rocks four six eight 5 5.3 6.2 [500 600 700] 5.5 5 5.7 [600 500 700] 4.8 4.3 3.4 [700 600 500]
Vamos a codificar:
R
rocks<- rep(c("four", "six", "eight"), each = 3)
rocks
fac <- factor(rep(c(500, 600, 700), each = 3))
fac
Producción:
[1] "four" "four" "four" "six" "six" "six" "eight" "eight" "eight" [1] 500 500 500 600 600 600 700 700 700 Levels: 500 600 700
Creando marco de datos:
R
height <- c(5, 5.5, 4.8, 5.3, 5, 4.3, 4.8, 4.3, 3.4) exp1 <- data.frame(rocks, treatment = fac, response = height) mod <- aov(response ~ treatment, data = exp1) summary(mod)
Producción:
Df Sum Sq Mean Sq F value Pr(>F) treatment 2 1.416 0.7078 2.368 0.175 Residuals 6 1.793 0.2989
Explicación:
Aquí 0.175>>0.05 por lo que se acepta la hipótesis.
Publicación traducida automáticamente
Artículo escrito por tedious_wings y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA