Prerrequisito: Introducción a los autómatas finitos
En este artículo, veremos algunos diseños de autómatas finitos no deterministas (NFA).
Problema-1: Construcción de un NFA mínimo que acepta un conjunto de strings sobre {a, b} en el que cada string del lenguaje contiene ‘a’ como substring.
Explicación: El idioma deseado será como:
L1 = {ab, abba, abaa, ...........}
Aquí, como podemos ver, cada string del lenguaje anterior contiene ‘a’ como substring. Pero el lenguaje a continuación no es aceptado por esta NFA porque parte de la string del lenguaje a continuación no contiene ‘a’ como substring.
L2 = {bb, b, bbbb, .............}
El diagrama de transición de estado del idioma deseado será el siguiente: 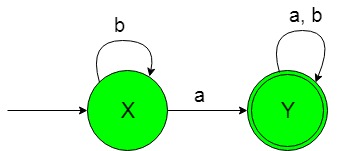
En el NFA anterior, el estado inicial ‘X’ al obtener ‘a’ como entrada, transita a un estado final ‘Y’ y al obtener ‘b’ como entrada permanece en el estado de sí mismo. El estado final ‘Y’ al obtener ‘a’ o ‘b’ como entrada, permanece en el estado de sí mismo. Consulte para DFA de NFA anterior .
Tabla de transición:
En esta tabla, el estado inicial se representa con —> y el estado final se representa con *.
| ESTADOS | ENTRADA (a) | ENTRADA (b) |
| —>X | Y* | X |
| Y* | Y* | Y* |
Implementación de Python:
def stateX(n):
#if length of n become 0
#then print not accepted
if(len(n)==0):
print("string not accepted")
else:
#if at zero index
#'a' found then call
#stateY function
if (n[0]=='a'):
stateY(n[1:])
#if at zero index
#'b' then call
#stateX function
elif (n[0]=='b'):
stateX(n[1:])
def stateY(n):
#if length of n become 0
#then print accepted
if(len(n)==0):
print("string accepted")
else:
#if at zero index
#'a' found call
#stateY function
if (n[0]=='a'):
stateY(n[1:])
#if at zero index
#'b' found call
#stateY function
elif (n[0]=='b'):
stateY(n[1:])
#take input
n=input()
#call stateA function
#to check the input
stateX(n)
Problema 2: construcción de un NFA mínimo que acepta un conjunto de strings sobre {a, b} en el que cada string del idioma no contiene ‘a’ como substring.
Explicación: El idioma deseado será como:
L1 = {b, bb, bbbb, ...........}
Aquí, como podemos ver, cada string del lenguaje anterior no contiene ‘a’ como substring. Pero el lenguaje a continuación no es aceptado por este NFA porque parte de la string del lenguaje a continuación contiene ‘a’ como substring.
L2 = {ab, aba, ababaab..............}
El diagrama de transición de estado del idioma deseado será el siguiente: 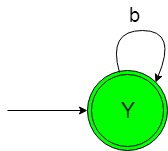
En el NFA anterior, el estado inicial y final ‘Y’ al obtener ‘b’ como entrada, permanece en el mismo estado.
Tabla de transición:
En esta tabla, el estado inicial se representa con —> y el estado final se representa con *.
| ESTADOS | ENTRADA (a) | ENTRADA (b) |
| —> Y* | Y* | Y* |
Implementación de Python:
def stateY(n):
#if length of n become 0
#then print accepted
if(len(n)==0):
print("string accepted")
else:
#if at zero index
#'a' found then
#print not accepted
if (n[0]=='a'):
print("String not accepted")
#if at zero index
#'b' found call
#stateY function
elif (n[0]=='b'):
stateY(n[1:])
#take input
n=input()
#call stateY function
#to check the input
stateY(n)
Publicación traducida automáticamente
Artículo escrito por Kanchan_Ray y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA