PROPÓSITO DEL SISTEMA DE SERVICIO DE REDES SOCIALES DE MEDIOS
Este sistema permitirá a los usuarios compartir fotos y videos con otros usuarios. Además, los usuarios pueden seguir a otros usuarios según la solicitud de seguimiento y pueden ver las fotos y videos de otros usuarios. En este sistema, puede buscar usuarios y ver su perfil si su cuenta es pública. De lo contrario, debe enviar una solicitud de seguimiento.
Antes de comenzar a diseñar cualquier sistema como un sistema de servicio de redes sociales para compartir fotos y videos, se recomienda pensar en los límites y requisitos del sistema en detalle y tratar de comprender cuáles serán las capacidades del sistema en el futuro (como 5 o 10 años) Esto es muy crítico ya que en algún momento si el conteo de usuarios del sistema aumenta exponencialmente, la capacidad del sistema no será suficiente para dar una respuesta rápida. Detrás del diseño arquitectónico hay que pensar en unos pilares. Estos son;
– Disponibilidad
– Confiabilidad
– Resiliencia
– Durabilidad
– Costo Rendimiento
Estos son los pilares que debemos considerar juntos ya que están acoplados entre sí. En resumen, disponibilidad significa que el sistema debe estar siempre disponible. Confiabilidad significa que el sistema debe funcionar como se espera. Resiliencia significa cómo y cuándo el sistema se recuperará si hay algún problema. La durabilidad es el único pilar en el que cada parte del sistema debe existir hasta que lo eliminemos. El desempeño de costos también es un tema importante que básicamente se relacionará con el uso de servicios bajo la eficiencia de costos. Se puede ilustrar como si el sistema se construyera en AWS y fuera suficiente usar instancias t2 micro EC2, no habrá ninguna razón para usar instancias EC2 más grandes y pagar dinero extra.
REQUISITOS Y LÍMITES DEL SISTEMA
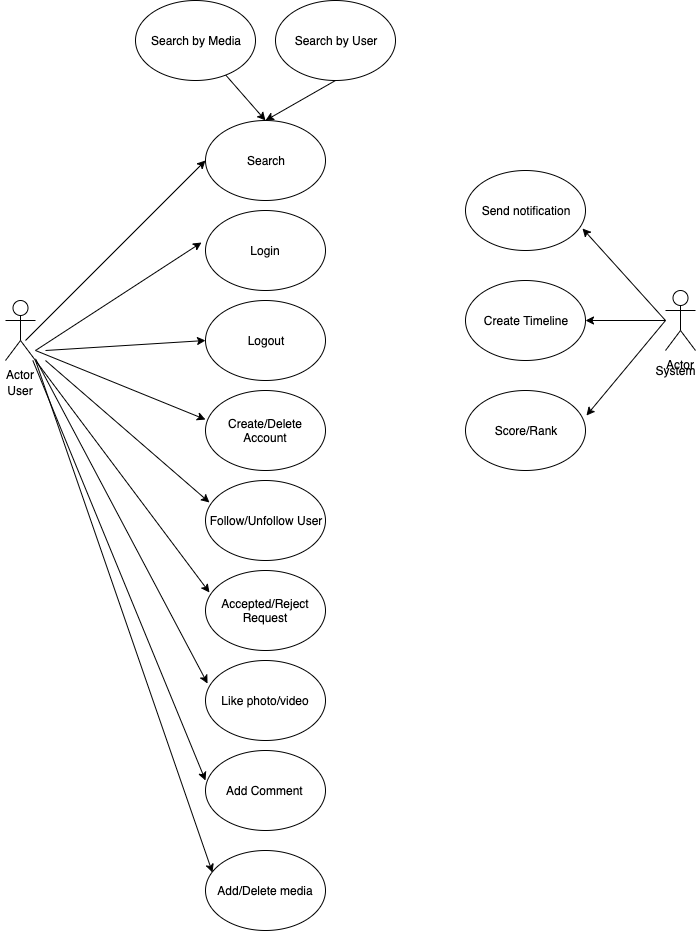
Si desea diseñar un sistema, primero debe definir los requisitos y los límites del sistema. Probablemente tendrá documentos de diseño de servicios y definirá requisitos, límites, decisiones arquitectónicas y otros en estos documentos de diseño de servicios. Pero básicamente, el sistema de redes sociales para compartir fotos y videos será un servicio en el que el usuario puede compartir imágenes y videos con otros usuarios. Los usuarios pueden tener una cuenta pública o privada, lo que significa que si tiene una cuenta pública, sus imágenes/videos serán visibles para otros usuarios (sin importar si tiene una relación o no). Pero si tiene una cuenta privada, sus imágenes/videos solo serán visibles para sus amigos. Por lo tanto, su sistema admitirá estas funciones;
– Los usuarios deben poder crear una cuenta.
– Cada usuario registrado debe tener su propia página de cuenta personal.
– Los usuarios deben poder iniciar sesión en el sistema y cerrar sesión en el sistema.
– Los usuarios deben poder ver las fotos y videos de otros usuarios en su línea de tiempo.
– Los usuarios deben poder cargar fotos y videos si inician sesión.
– Los usuarios deben poder eliminar sus fotos y videos si inician sesión.
– Los usuarios deben poder buscar usuarios.
– El sistema debe ser capaz de admitir cuentas públicas y privadas.
– Los usuarios deben poder enviar una solicitud de seguimiento a otros usuarios.
– Los usuarios deben poder aceptar o denegar requests de seguimiento.
– Los usuarios deben poder eliminar su cuenta cuando lo deseen.
– Los usuarios deben poder dar me gusta a las fotos y videos de otros usuarios.
– El sistema debe tener alta disponibilidad
– El sistema debe ser altamente confiable
– El sistema debe ser duradero
– El sistema debe ser resistente
– El sistema debe ser altamente rentable y eficiente en rendimiento
Cuando se definen los límites del sistema y los requisitos funcionales, es necesario pensar en la nube o en opciones de promesa. Su sistema puede ser;
– %100 on-promise (su propio centro de datos/servidor)
– %100 cloud (AWS, Google Cloud, Azure)
– Combinación de on-promise y nube (puede tener ambos durante el proceso de migración)
Actualmente, los servicios en la nube tienen una gran popularidad gracias a las ventajas del mecanismo de la nube. Estas ventajas;
– Rentabilidad
– Alta velocidad
– Seguridad
– Soluciones de copia de seguridad
– Capacidad de almacenamiento ilimitada
– Muchas opciones de servicio diferentes. No necesita crear un mundo desde cero
– Confiabilidad
– Durabilidad
– Resiliencia
– Monitoreo para casi todos los servicios
– Fácil integración de software con otros servicios
– Mantenimiento de proveedores de la nube y más…
Pensemos en los límites del diseño;
– El servicio será tanto de escritura como de lectura.
– El servicio se mantendrá consistente y confiable, lo que significa que no debería haber ninguna pérdida de datos. – El servicio será duradero, lo que significa que todas las partes del sistema deben existir hasta que se eliminen manualmente.
Antes de definir la consideración de capacidad, debe definir cuál es el propósito del servicio. Incluso si es más esencial para los servicios bajo promesa, es esencial tanto para los servicios bajo promesa como en la nube, ya que puede seleccionar los servicios correctos según el propósito, ubicarlos según las regiones disponibles y definir las capacidades. Tales ejemplos son;
– Crear más servicios de lectura que de escritura.
– Seleccionar el tipo de servidor según el tipo de operación.
– Defina estrategias de almacenamiento en caché en función de su estimación de capacidad.
– Seleccione el tipo de base de datos (SQL, NoSQL) según sus requisitos.
– Defina soluciones de respaldo basadas en sus estimaciones de capacidad.
– Defina estrategias de fragmentación de datos en función de sus requisitos, etc.
Supongamos que tiene 100 millones de usuarios en total. En su sistema, supondremos que la descarga de datos es más pesada que la carga de datos y supongamos que la proporción de lectura y escritura es de 10:3.
Asumiremos que el tamaño promedio de la foto es de 200 KB y el tamaño promedio del video es de 25 MB, por lo que el sistema tendrá;
Fotos capacidad en 5 años;
– 5 * 100M * 10 * 200 KB = 1 PB. (Suponiendo que cada usuario suba 10 fotos cada año).
– 12 PB para replicación y respaldo.
Entonces esa capacidad total de fotos llegará a 3 PB en 5 años.
Capacidad de videos en 5 años;
– 5 * 100M * 1 * 25 MB = 12 PB. (Suponiendo que cada usuario suba 1 videos cada año).
– 36 PB para replicación y respaldo.
Este cálculo es solo un breve ejemplo de cómo definir la capacidad del sistema y no calcularemos la capacidad de carga/descarga diaria ni las capacidades de metadatos, pero debe considerar este cálculo (y la estimación de la capacidad de lectura/escritura diaria) para escalar servicios/bases de datos.
DISEÑO DE API
Podemos usar REST o SOAP para servir nuestras API. Básicamente, habrá tres API importantes del sistema de servicio para compartir fotos y videos.
1- PostMedia (api_dev_key, media_type, media_data, title, description, tags[], media_details)
PostMedia será responsable de cargar la foto o la imagen. api_dev_key es la clave de desarrollador de API de una cuenta registrada. Podemos eliminar ataques de hackers con api_dev_key. Esta API devuelve una respuesta HTTP. (202 aceptado si tiene éxito)
2- GetMedia (api_dev_key, media_type, search_query, user_location, page, maximum_video_count = 20)
Devuelve JSON que contiene información sobre la lista de fotos y videos. Cada recurso de medios tendrá un título, fecha de creación, como recuento, recuento total de vistas, propietario y otra metainformación.
3- DeleteMedia (api_dev_key, ID, type)
Compruebe si el usuario tiene permiso para eliminar medios. Devolverá la respuesta HTTP 200 (OK), 202 (Aceptado) si la acción se ha puesto en cola o 204 (Sin contenido) según su respuesta.
**Hay más API para diseñar servicios para compartir fotos y videos, sin embargo, estas tres API son más importantes que las demás. Otras API serán como Media, búsqueda, recomendación, etc.
ESQUEMA DE LA BASE DE DATOS
Puede pensar en la parte de la base de datos en dos partes. La primera parte estará relacionada con cómo mantener las imágenes/videos de forma segura y la segunda parte estará relacionada con cómo mantener los metadatos de las imágenes/videos y la información del usuario/datos de relaciones con el usuario en la base de datos. Los videos y las imágenes son datos estáticos para que pueda mantener imágenes/videos en el almacenamiento de imágenes. Puede utilizar servicios de terceros como Chromecast o, si utiliza AWS, puede almacenar archivos multimedia reales en S3. S3 ofrecerá diferentes tipos de almacenamiento en función de su estrategia. Para ilustrar esto, S3 ofrecerá S3 estándar, s3 con acceso infrecuente, S3 Glacier, etc. Si pensamos en Instagram, podemos comenzar a usar el estándar S3 para guardar imágenes/videos si se cargan este año y después del primer año podemos moverlos. a S3 acceden con poca frecuencia y después de 10 años podemos moverlos a S3 Glacier. Esto hace que el sistema sea rentable, ya que aunque el estándar S3 es uno de los servicios más económicos de AWS, el acceso poco frecuente a S3 es más económico que el estándar S3. Además, S3 Standard y S3 con acceso poco frecuente mantienen automáticamente los datos en diferentes zonas de disponibilidad (como el centro de datos) para que no se preocupe por la confiabilidad. Pero sería bueno mantener los datos reflejados (replicación) en diferentes regiones para aumentar la redundancia de datos. Además, será bueno usar Cloudfront como una capa de almacenamiento en caché de distribución para disminuir el tiempo de lectura/acceso. Cloudfront es un servicio de almacenamiento en caché de AWS distribuido que se encuentra en diferentes ubicaciones de borde. Puede usar las opciones de lectura y escritura de Cloudfront. Además, S3 Standard y S3 con acceso poco frecuente mantienen automáticamente los datos en diferentes zonas de disponibilidad (como el centro de datos) para que no se preocupe por la confiabilidad. Pero sería bueno mantener los datos reflejados (replicación) en diferentes regiones para aumentar la redundancia de datos. Además, será bueno usar Cloudfront como una capa de almacenamiento en caché de distribución para disminuir el tiempo de lectura/acceso. Cloudfront es un servicio de almacenamiento en caché de AWS distribuido que se encuentra en diferentes ubicaciones de borde. Puede usar las opciones de lectura y escritura de Cloudfront. Además, S3 Standard y S3 con acceso poco frecuente mantienen automáticamente los datos en diferentes zonas de disponibilidad (como el centro de datos) para que no se preocupe por la confiabilidad. Pero sería bueno mantener los datos reflejados (replicación) en diferentes regiones para aumentar la redundancia de datos. Además, será bueno usar Cloudfront como una capa de almacenamiento en caché de distribución para disminuir el tiempo de lectura/acceso. Cloudfront es un servicio de almacenamiento en caché de AWS distribuido que se encuentra en diferentes ubicaciones de borde. Puede usar las opciones de lectura y escritura de Cloudfront. Cloudfront es un servicio de almacenamiento en caché de AWS distribuido que se encuentra en diferentes ubicaciones de borde. Puede usar las opciones de lectura y escritura de Cloudfront. Cloudfront es un servicio de almacenamiento en caché de AWS distribuido que se encuentra en diferentes ubicaciones de borde. Puede usar las opciones de lectura y escritura de Cloudfront.
Para Usuario, puede usar RDBMS o NoSQL. Podemos usar la base de datos de gráficos para que haya una relación sólida entre los usuarios. AWS Neptune o Neo4j pueden ser bases de datos adecuadas para este propósito. Diseño en MySQL o PostgreSQL;
Usuario:
USERID: INT
NICKNAME: NVARCHAR(50)
CONTRASEÑA: VARCHAR(255) con función Hash
EMAIL: NVARCHAR(50)
BIRTHDATE: DATETIME
REGISTERDATE: DATETIME
LASTLOGINDATE: DATETIME
Clave principal: USERID
UserRelations
ID: INT FOLLOWERID:
INT FOLLOWINGID
: INT
Primary Clave: ID
Clave externa: FOLLOWERID, FOLLOWINGID con tabla de usuario
Para publicar metadatos, puede usar RDBMS como MySQL o PostgreSQL.
ID de la publicación
: INT
USERID: INT
MEDIA_TYPE_ID: INT
PATH: NVARCHAR(100)
DESCRIPCIÓN: TEXT
VISIBILITY: BOOLEAN
ADDEDDATE: DATETIME
VIEWS_COUNT: INT
Clave principal: ID
Clave externa: USERID con tabla de usuario
Clave externa: MEDIA_TYPE_ID con tabla Media_Type
Clave principal: (ID, TYPE)
Clave foránea: MEDIAID con ID de usuario de tabla de
medios : INT MEDIAID: INT
ID DE USUARIO: INT Clave principal: ID Clave externa: ID DE USUARIO con tabla de usuario Clave externa: MEDIAID con ID de comentario de tabla de medios : INT MEDIAID: INT ID DE USUARIO: INT COMMENT: NVARCHAR(256 ) Clave principal: ID
Clave foránea: USERID con tabla de usuario
Clave foránea: MEDIAID con tabla de medios
Por supuesto, tendremos más tablas de base de datos y estas son solo una muestra. Será bueno seguir las reglas de normalización para el proceso de diseño de bases de datos.
** Almacenaremos fotos/videos en AWS S3. También podemos usar las reglas del ciclo de vida de S3 para la rentabilidad.
** Podemos usar Cassandra, almacenamiento de datos basado en columnas, para guardar el seguimiento de los usuarios.
Nota: Muchas bases de datos NoSQL admiten la replicación.
Nota: Podemos crear un índice secundario en la tabla de medios: campo ADDEDDATE porque necesitamos obtener los archivos de medios más recientes.
CONSIDERACIÓN DE DISEÑO DEL SISTEMA
: el sistema tendrá un mecanismo de almacenamiento en caché para una respuesta rápida al descargar archivos multimedia.
– El sistema eventualmente será consistente pero tendremos políticas de desalojo de caché para limpiar el caché.
– El sistema tendrá un mecanismo de notificación push para enviar información a los usuarios (como si a los usuarios les gusta la foto/video).
– El sistema tendrá Cloudfront como CDN. Cloudfront está ubicado en ubicaciones EDGE para que el tiempo de respuesta sea rápido. Podemos usar Cloudfront tanto para descargar como para cargar.
– El sistema usará NGinx como balanceador de carga e implementaremos un algoritmo de enrutamiento inteligente para enviar requests solo a servicios saludables.
– El sistema tendrá un servicio pregenerado para crear una línea de tiempo para los usuarios.
– El sistema mantendrá datos y archivos más de uno. (Replicación, respaldo)
– El sistema tendrá un mecanismo de monitoreo. El sistema enviará una alerta si los componentes del sistema fallan según la consideración de la alerta
: el sistema admitirá el mecanismo de canalización de código. Podemos usar AWS Codecommit, Codebuild, CodeDeploy y CodePipeline.
DISEÑO DE SISTEMAS DE ALTO NIVEL
Si estamos diseñando un sistema, los conceptos básicos que necesitamos son;
– Cliente
– Servicios
– Servidor web
– Servidor de aplicaciones
– Almacenamiento de archivos de medios
– Base de datos
– Almacenamiento en caché
– Replicación
– Redundancia
– Equilibrio de carga
– Fragmentación
Hay dos servicios separados en este sistema, que son medios de carga/descarga. El almacenamiento multimedia se utiliza para mantener contenido multimedia estático. Se utiliza una base de datos para guardar todos los metadatos sobre los usuarios y los contenidos multimedia. Cuando llega una solicitud al sistema, llegará primero a los servidores web. Los servidores web redirigen una solicitud entrante a los servidores de aplicaciones.
La replicación y el respaldo son dos conceptos importantes para proporcionar los pilares que mencionamos anteriormente. La replicación es un concepto muy importante para manejar una falla de servicios o servidores. La replicación se puede aplicar a servidores de bases de datos, servidores web, servidores de aplicaciones, almacenamiento de medios, etc. En realidad, podemos replicar todas las partes del sistema. (Algunos de los servicios de AWS, como Route53, son altamente disponibles en sí mismos, por lo que no es necesario que se ocupe de la replicación de Route53, el balanceador de carga, etc.) Tenga en cuenta que la replicación también ayuda al sistema a reducir el tiempo de respuesta. Imagínese, si dividimos las requests entrantes en más recursos en lugar de un recurso, el sistema puede satisfacer fácilmente todas las requests entrantes. Además, el número óptimo de una réplica para cada recurso es 3 o más.
Para las estrategias de almacenamiento en caché, podemos usar un mecanismo de almacenamiento en caché global mediante el uso de servidores de caché. Podemos usar Redis o Memcache, pero la parte más importante de la estrategia de almacenamiento en caché es cómo proporcionar el desalojo de caché. Si usamos servidores de caché global, garantizaremos que cada usuario verá los mismos datos en el caché, pero habrá tiempo de latencia si usamos servidores de caché global. Como estrategias de almacenamiento en caché, podemos usar el algoritmo LRU (Usado menos recientemente).
Para el almacenamiento en caché de archivos multimedia, como mencionamos antes, usaremos CDN. CDN está ubicado en diferentes ubicaciones de borde, por lo que el tiempo de respuesta será menor que obtener contenido multimedia directamente desde AWS S3.
Fragmentar las ID en este tipo de servicios siempre es difícil, ya que habrá una gran cantidad de datos, pero puede verificar;
a href=”https://instagram-engineering.com/sharding-ids-at-instagram-1cf5a71e5a5c/”>
El balanceador de carga permite redirigir las requests entrantes a los recursos según ciertos criterios. Podemos usar el balanceador de carga en cada capa del sistema. Si queremos utilizar el servicio de equilibrador de carga de AWS, AWS admitirá tres tipos diferentes de equilibrador de carga que son;
– Equilibrador de carga de red
– Equilibrador de carga clásico (obsoleto)
– Equilibrador de carga de aplicaciones
Para este servicio, el equilibrador de carga de aplicaciones se adaptará a nuestro servicio y también manejará la distribución AZ en sí mismo. De lo contrario, puede usar NGinx, pero debe implementar el algoritmo y debe proporcionar mantenimiento si queremos usar NGinx.
Podemos usar el balanceador de carga;
– Entre requests y servidores web.
– Entre servidores web y servidores de aplicaciones.
– Entre servidores de aplicaciones y bases de datos
– Entre servidores de aplicaciones y almacenamientos de imágenes.
– Entre servidores de aplicaciones y bases de datos de caché.
– Podemos usar el método Round Robin para el balanceador de carga. El método Round Robin evita que las requests vayan a servidores inactivos, pero el método Round Robin no se ocupa de la situación en la que cualquier servidor tiene mucho tráfico. Podemos modificar el método Round Robin para que sea un método más inteligente para manejar este problema.
MUESTRA DE CODIFICACIÓN BÁSICA
Java
// Java Program to explain the design
public enum InvitationStatus{
PENDING,
ACCEPTED,
REJECTED,
CANCELLED
}
public enum AccountStatus{
PUBLIC,
PRIVATE,
CLOSED
}
public enum MediaStatus {
PUBLIC,
PRIVATE
}
public enum MediaType {
PHOTO,
VIDEO
}
public class AddressDetails {
private String streetAddress;
private String city;
private String country;
...
}
public class AccountDetails {
private Date createdTime;
private AccountStatus status;
private boolean updateAccountStatus(AccountStatus accountStatus);
...
}
public class Invitation {
private Integer userID;
private InvitationStatus status;
private Date sentDate;
public boolean updateInvitation(InvitationStatus status);
...
}
public class PendingInvitation extends Invitation{
public boolean acceptConnection();
public boolean rejectConnection();
...
}
public class UserRelations {
private HashSet<Integer> userFollower;
private HashSet<Integer> userFollowing;
private HashSet<ConnectionInvitation> connectionInvitations;
...
}
public class Comment {
private Integer id;
private User addedBy;
private Date addedDate;
private String comment;
public boolean updateComment(String comment);
...
}
public class Media {
private Integer id;
private User createdBy;
private MediaType mediaType;
private String path;
private MediaStatus mediaStatus;
private int viewsCount;
private HashSet<Integer> userLikes;
private HashSet<Integer> userComments;
...
}
public class User {
private int id;
private String password;
private String nickname;
private String email;
private AddressDetails addressDetails;
private AccountDetails accountDetails;
private UserRelations userRelations;
private HashSet<ConnectionInvitation> invitationsByMe;
private HashSet<ConnectionInvitation> invitationsToMe;
public boolean updatePassword();
public boolean createMedia(Media media);
public boolean updateMedia(int mediaId, MediaStatus mediaStatus);
public boolean sendInvitation(ConnectionInvitation invitation);
public List<User> searchUser(string term);
public List<Media> searchMedia(string term);
...
}
Referencia: https://tinyurl.com/yhyv6yxl
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.