Un árbol de sintaxis es un árbol en el que cada Node hoja representa un operando, mientras que cada Node interior representa un operador. El árbol de análisis se abrevia como el árbol de sintaxis. El árbol de sintaxis generalmente se usa cuando se representa un programa en una estructura de árbol.
Reglas para construir un árbol de sintaxis
Todos los Nodes de un árbol de sintaxis se pueden realizar como datos con numerosos campos. Un elemento del Node para un operador identifica al operador, mientras que el campo restante contiene un puntero a los Nodes de operandos. El operador también se conoce como la etiqueta del Node. Los Nodes del árbol sintáctico para expresiones con operadores binarios se crean utilizando las siguientes funciones. Cada función devuelve una referencia al Node que se creó más recientemente.
1. mknode (op, izquierda, derecha): Crea un Node operador con el nombre op y dos campos, que contienen punteros izquierdo y derecho.
2. mkleaf (id, entrada): Crea un Node identificador con la etiqueta id y el campo de entrada, que es una referencia a la entrada de la tabla de símbolos del identificador.
3. mkleaf (num, val): Crea un Node de número con el nombre num y un campo que contiene el valor del número, val. Haz un árbol de sintaxis para la expresión a 4 + c, por ejemplo. p1, p2,…, p5 son punteros a las entradas de la tabla de símbolos para los identificadores ‘a’ y ‘c’, respectivamente, en esta secuencia.
Ejemplo 1: el árbol de sintaxis para la string a – b ∗ c + d es:
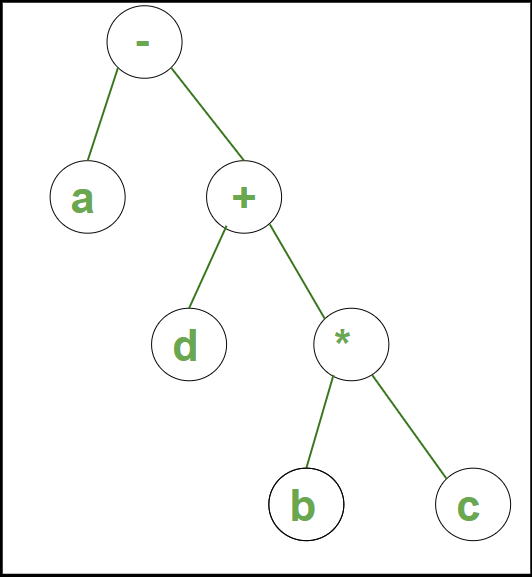
Árbol de sintaxis para el ejemplo 1
Ejemplo 2: el árbol de sintaxis para la string a * (b + c) – d /2 es:
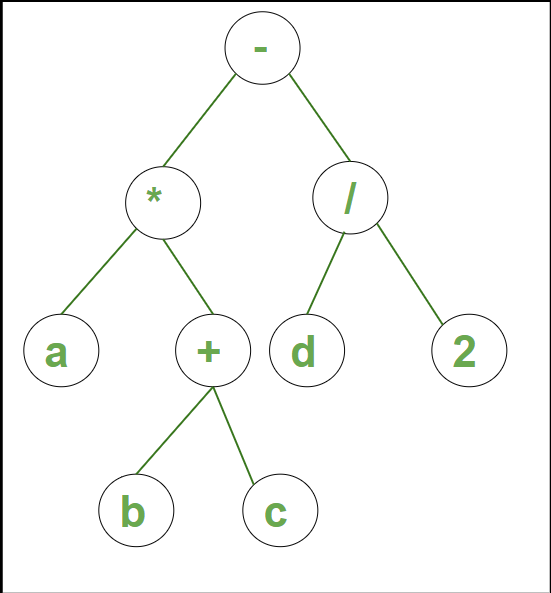
Árbol de sintaxis para el ejemplo 2
Variantes del árbol de sintaxis:
Un árbol de sintaxis tiene básicamente dos variantes que se describen a continuación:
- Gráficos acíclicos dirigidos para expresiones (DAG)
- El método de número de valor para construir DAG
Gráficos acíclicos dirigidos para expresiones (DAG)
Un DAG, como el árbol sintáctico de una expresión, incluye hojas que corresponden a operandos atómicos y códigos internos que corresponden a operadores. Si N denota una subexpresión común, un Node N en un DAG tiene muchos padres; en un árbol de sintaxis, el árbol de la subexpresión común se duplicaría tantas veces como aparezca la subexpresión en la expresión original. Como resultado, un DAG no solo codifica expresiones de manera más concisa, sino que también proporciona información esencial al compilador sobre cómo generar código eficiente para evaluar las expresiones.
El gráfico acíclico dirigido (DAG) es una herramienta que muestra la estructura de los bloques fundamentales, le permite examinar el flujo de valores entre ellos y también le permite optimizarlos. DAG permite transformaciones simples de piezas fundamentales.
Las propiedades de DAG son:
- Los Nodes hoja representan identificadores, nombres o constantes.
- Los Nodes interiores representan operadores.
- Los Nodes interiores también representan los resultados de expresiones o los identificadores/nombre donde se almacenarán o asignarán los valores.
Ejemplos:
T0 = a+b --- Expression 1 T1 = T0 +c --- Expression 2
Expresión 1: T 0 = a+b
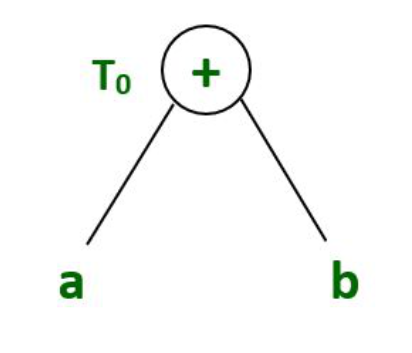
Árbol de sintaxis para la expresión 1
Expresión 2: T 1 = T 0 +c
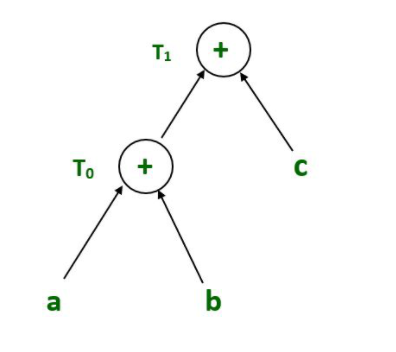
Árbol de sintaxis para la expresión 2
El método de número de valor para construir DAG:
Se utiliza una array de registros para contener los Nodes de un árbol de sintaxis o DAG. Cada fila de la array corresponde a un solo registro y, por lo tanto, a un solo Node. El primer campo de cada registro es un código de operación, que indica la etiqueta del Node. En la siguiente figura, los Nodes interiores contienen dos campos más que indican los elementos secundarios izquierdo y derecho, mientras que las hojas tienen un campo adicional que almacena el valor léxico (ya sea un puntero de tabla de símbolos o una constante en este caso).
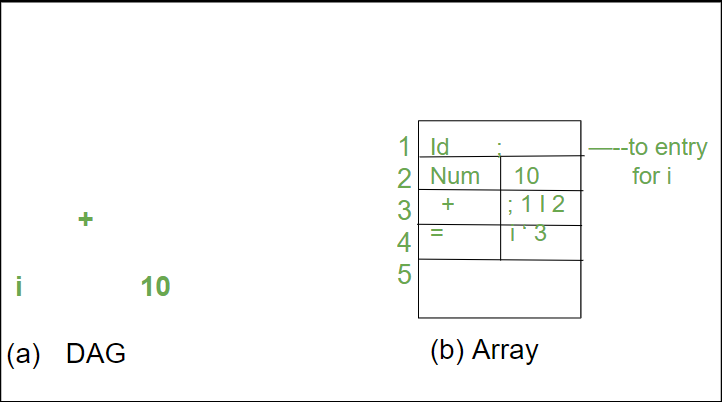
Nodes de un DAG para i = i + 10 asignados en una array
El índice entero del registro de ese Node dentro de la array se utiliza para hacer referencia a los Nodes de esta array. Este entero ha sido referido como el número de valor del Node o la expresión representada por el Node en el pasado. El valor del Node etiquetado -I- es 3, mientras que los valores de sus hijos izquierdo y derecho son 1 y 2, respectivamente. En lugar de índices enteros, podemos usar punteros a registros o referencias a objetos en la práctica, pero la referencia a un Node aún se denominaría su «número de valor». Los números de valor pueden ayudarnos a construir expresiones si se almacenan en el formato de datos correcto.
- Algoritmo: el método de número de valor para construir los Nodes de un gráfico acíclico dirigido.
- ENTRADA: etiqueta op, Node / y Node r.
- SALIDA: el número de valor de un Node en la array con firma (op, l, r).
- MÉTODO: busque en la array el Node M con la etiqueta op, el hijo izquierdo I y el hijo derecho r. Si existe tal Node, devuelva el número de valor de M. De lo contrario, cree en la array un nuevo Node N con la etiqueta op, el hijo izquierdo I y el hijo derecho r, y devuelva su número de valor.
Si bien Algorithm produce el resultado deseado, examinar la array completa cada vez que se solicita un Node lleva mucho tiempo, especialmente si la array contiene expresiones de un programa completo. Una tabla hash, en la que los Nodes se dividen en «cubos», cada uno de los cuales generalmente contiene solo unos pocos Nodes, es un método más eficiente. La tabla hash es una de las numerosas estructuras de datos que pueden admitir efectivamente diccionarios. 1 Un diccionario es un tipo de datos que nos permite agregar y eliminar elementos de un conjunto, así como detectar si un elemento en particular está presente en el conjunto. Una buena estructura de datos de diccionario, como una tabla hash, ejecuta cada una de estas operaciones en una cantidad de tiempo constante o casi constante, independientemente del tamaño del conjunto.
Para construir una tabla hash para los Nodes de un DAG, necesitamos una función hash h que calcule el índice del depósito para una firma (op, I, r) de tal manera que las firmas se distribuyan entre los depósitos y ningún depósito obtenga más que una buena parte de los Nodes. El índice de cubeta h(op, I, r) se calcula de forma determinista a partir de op, I y r, lo que nos permite repetir el cálculo y llegar siempre al mismo índice de cubeta por Node (op, I, r).
Los cubos se pueden implementar como listas enlazadas, como en la figura dada. Los encabezados de los cubos se almacenan en una array indexada por el valor hash, cada uno de los cuales corresponde a la primera celda de una lista. Cada columna en la lista vinculada de un depósito contiene el número de valor de uno de los Nodes que generan hash en ese depósito. Es decir, el Node (op, l, r) puede estar ubicado en la lista de la array cuyo encabezado está en el índice h (op, l, r).

Estructura de datos para buscar cubos
Calculamos el índice de depósito h(op,l,r) y buscamos en la lista de celdas de este depósito el Node de entrada especificado, dados los Nodes de entrada op, I y r. Por lo general, hay suficientes cubos para que ninguna lista tenga más de unas pocas celdas. Sin embargo, es posible que debamos examinar todas las celdas en un depósito, y para cada número de valor v descubierto en una celda, debemos verificar que la firma del Node de entrada (op, l, r) coincida con el Node con el número de valor v en el lista de celdas (como en la figura anterior). Si se encuentra una coincidencia, devolvemos v. Creamos una nueva celda, la agregamos a la lista de celdas para el índice de depósito h(op, l,r) y devolvemos el número de valor en esa nueva celda si no encontramos ninguna coincidencia.