En este artículo, discutiremos la distribución de datos en Cassandra y cómo los datos se distribuyen en el clúster. Entonces, echemos un vistazo.
En Cassandra, la distribución y la replicación de datos van juntas. En Cassandra, la distribución y la replicación dependen de las tres cosas, como la clave de partición, el valor de la clave y el rango del token.
Cassandra Table:
en esta tabla hay dos filas en las que una fila contiene cuatro columnas y sus valores. La segunda fila contiene dos columnas (columna 1 y columna 3) y sus valores. En esta columna de la tabla 1 que tiene la clave principal.

Ahora, tomemos un ejemplo de cómo los datos del usuario se distribuyen en el clúster.
| E_id | nombre_e | E_sal |
|---|---|---|
| 101 | Cenizo | 90000 |
| 102 | aayush | 95000 |
| 103 | Raúl | 70000 |
| 104 | Abí | 60000 |
A continuación, la arquitectura de anillo dada de cuatro Nodes dados tiene un rango de token y cada fila tiene su propia identificación de token, por lo que, con la ayuda del particionador, generaremos valores de token y los asignaremos y distribuiremos en el clúster en consecuencia.
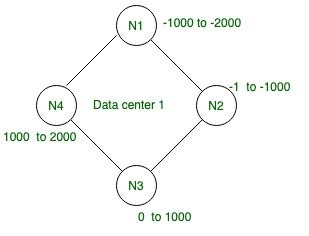
Token: los tokens son valores hash y el algoritmo hash Murmur3 se usa para el hash en Cassandra que los particionadores usan para determinar dónde almacenar filas en cada Node en el anillo.
por ejemplo: tomemos un valor hash aleatorio para cada fila para los datos dados en la tabla anterior.
| clave de partición | Valor de hash de Murmur3 |
|---|---|
| Cenizo | 1500 |
| aayush | -800 |
| Raúl | -1500 |
| Abí | 700 |
Echemos un vistazo para una mejor comprensión.
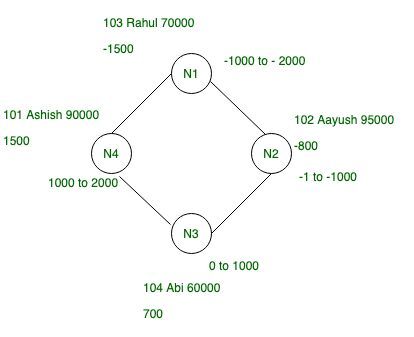
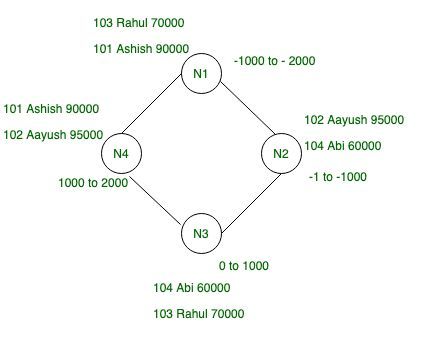
Factor de replicación: en Cassandra, el factor de replicación es muy importante, ya que indica el número total de réplicas en el clúster.
Tomemos RF = 2, lo que simplemente significa que hay dos copias de cada fila. No hay una réplica principal o principal en Cassandra.
Publicación traducida automáticamente
Artículo escrito por Ashish_rana y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA