En este artículo, vamos a ver cómo dividir un marco de datos por varios métodos y en función de varios parámetros usando Python. Para dividir un marco de datos en dos o más marcos de datos separados en función de los valores presentes en la columna, primero creamos un marco de datos.
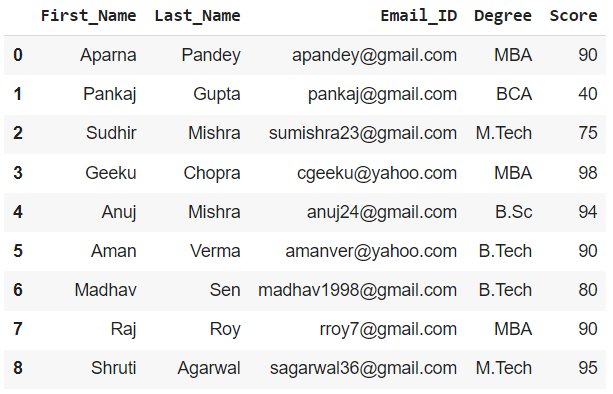
Creando un DataFrame para demostración:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'First_Name': ["Aparna", "Pankaj", "Sudhir",
"Geeku", "Anuj", "Aman",
"Madhav", "Raj", "Shruti"],
'Last_Name': ["Pandey", "Gupta", "Mishra",
"Chopra", "Mishra", "Verma",
"Sen", "Roy", "Agarwal"],
'Email_ID': ["apandey@gmail.com", "pankaj@gmail.com",
"sumishra23@gmail.com", "cgeeku@yahoo.com",
"anuj24@gmail.com", "amanver@yahoo.com",
"madhav1998@gmail.com", "rroy7@gmail.com",
"sagarwal36@gmail.com"],
'Degree': ["MBA", "BCA", "M.Tech", "MBA", "B.Sc",
"B.Tech", "B.Tech", "MBA", "M.Tech"],
'Score': [90, 40, 75, 98, 94, 90, 80, 90, 95]}
# creating dataframe
df = pd.DataFrame(dict)
print(df)
Producción:
Método 1: por indexación booleana
Podemos crear múltiples marcos de datos a partir de un marco de datos determinado en función de un determinado valor de columna utilizando el método de indexación booleano y mencionando los criterios necesarios.
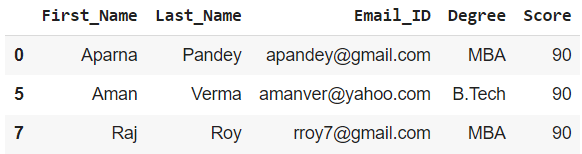
Ejemplo 1: Crear un marco de datos para los estudiantes con Puntaje >= 80
Python3
# creating a new dataframe by applying the required # conditions in [] df1 = df[df['Score'] >= 80] print(df1)
Producción:
Ejemplo 2: Creación de un marco de datos para los estudiantes con Last_Name como Mishra
Python3
# Creating on the basis of Last_Name dfname = df[df['Last_Name'] == 'Mishra'] print(dfname)
Producción:

Podemos hacer lo mismo para otras columnas también poniendo la condición apropiada
Método 2: indexación booleana con variable de máscara
Creamos una variable de máscara para la condición de la columna en el método anterior
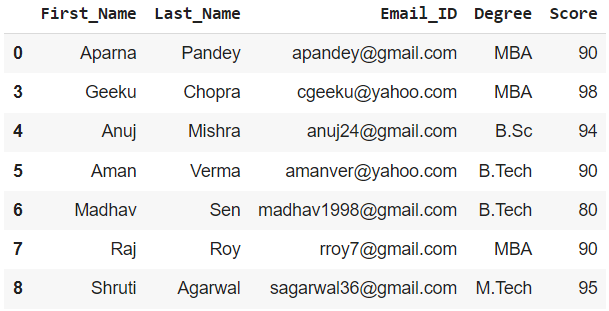
Ejemplo 1: Para obtener un marco de datos de estudiantes con título de MBA
Python3
# creating the mask variable with appropriate # condition mask_var = df['Degree'] =='MBA' # creating a dataframe df1_mask = df[mask_var] print(df1_mask)
Producción :
Ejemplo 2: Para obtener un marco de datos para el resto de los estudiantes
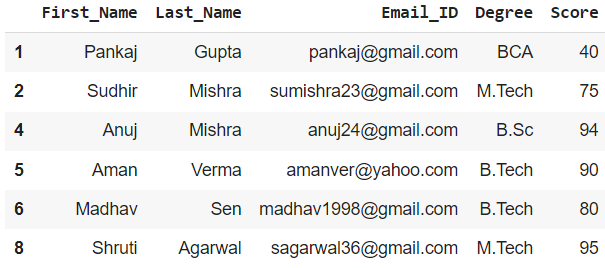
Para obtener el resto de los valores en un marco de datos, simplemente podemos invertir la variable de máscara agregando una ~ (tilde) después de ella.
Python3
# creating dataframe with inverted mask variable df2_mask = df[~mask_var] print(df2_mask)
Producción :
Método 3: Usar la función groupby()
Usando groupby() podemos agrupar las filas usando un valor de columna específico y luego mostrarlo como un marco de datos separado.
Ejemplo 1: agrupar a todos los estudiantes según su título y mostrar según sea necesario
Python3
# Creating an object using groupby
grouped = df.groupby('Degree')
# the return type of the object 'grouped' is
# pandas.core.groupby.generic.DataFrameGroupBy.
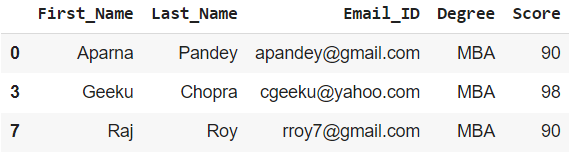
# Creating a dataframe from the object using get_group().
# dataframe of students with Degree as MBA.
df_grouped = grouped.get_group('MBA')
print(df_grouped)
Salida: dataframe de estudiantes con Grado como MBA
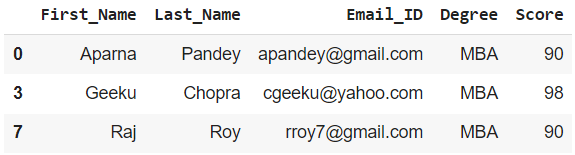
Ejemplo 2: Agrupe a todos los Estudiantes de acuerdo con su Puntaje y muéstrelos según sea necesario
Python3
# Creating another object using groupby
grouped2 = df.groupby('Score')
# the return type of the object 'grouped2' is
# pandas.core.groupby.generic.DataFrameGroupBy.
# Creating a dataframe from the object
# using get_group() dataframe of students
# with Score = 90
df_grouped2 = grouped2.get_group(90)
print(df_grouped2)
Salida: dataframe de estudiantes con Score = 90.