En este artículo, aprenderemos sobre la división de marcos de datos grandes en una lista de marcos de datos más pequeños. Esto se puede hacer principalmente de dos maneras diferentes:
- Al dividir cada fila
- Usando el concepto de groupby
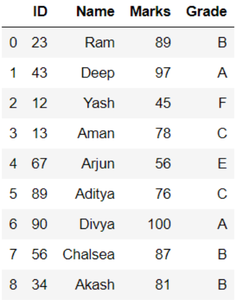
Aquí usamos un marco de datos pequeño para comprender el concepto fácilmente y esto también se puede implementar de una manera fácil. El marco de datos consiste en la identificación del estudiante, el nombre, las marcas y las calificaciones. Vamos a crear el marco de datos.
Python3
# importing packages
import pandas as pd
# dictionary of data
dct = {'ID': {0: 23, 1: 43, 2: 12,
3: 13, 4: 67, 5: 89,
6: 90, 7: 56, 8: 34},
'Name': {0: 'Ram', 1: 'Deep',
2: 'Yash', 3: 'Aman',
4: 'Arjun', 5: 'Aditya',
6: 'Divya', 7: 'Chalsea',
8: 'Akash'},
'Marks': {0: 89, 1: 97, 2: 45, 3: 78,
4: 56, 5: 76, 6: 100, 7: 87,
8: 81},
'Grade': {0: 'B', 1: 'A', 2: 'F', 3: 'C',
4: 'E', 5: 'C', 6: 'A', 7: 'B',
8: 'B'}
}
# create dataframe
df = pd.DataFrame(dct)
# view dataframe
df
Producción:
A continuación se muestra la implementación de los conceptos anteriores con algunos ejemplos:
Ejemplo 1: dividiendo cada fila
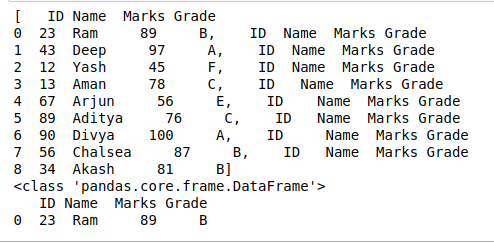
Aquí, usamos el bucle de iteración para cada fila. Se accede a cada fila mediante DataFrame.loc[] y se almacena en una lista. Esta lista es la salida requerida que consta de pequeños marcos de datos. En este ejemplo, el conjunto de datos (consta de 9 filas de datos) se divide en marcos de datos más pequeños dividiendo cada fila para que la lista se cree de 9 marcos de datos más pequeños como se muestra a continuación en la salida.
Python3
# split dataframe by row splits = [df.loc[[i]] for i in df.index] # view splitted dataframe print(splits) # check datatype of smaller dataframe print(type(splits[0])) # view smaller dataframe print(splits[0])
Producción:
Ejemplo 2: uso de Groupby
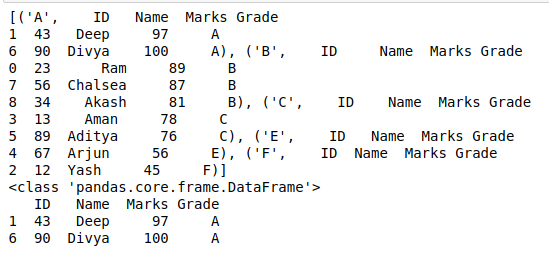
Aquí, usamos el método DataFrame.groupby() para dividir el conjunto de datos por filas. Las mismas filas agrupadas se toman como un solo elemento y se almacenan en una lista. Esta lista es la salida requerida que consta de pequeños marcos de datos. En este ejemplo, el conjunto de datos (que consta de 9 filas de datos) se divide en marcos de datos más pequeños utilizando el método groupby en la columna «Calificación». Aquí, el número total de calificaciones distintas es 5, por lo que la lista se crea con 5 marcos de datos más pequeños, como se muestra a continuación en la salida.
Python3
# split dataframe using gropuby
splits = list(df.groupby("Grade"))
# view splitted dataframe
print(splits)
# check datatype of smaller dataframe
print(type(splits[0][1]))
# view smaller dataframe
print(splits[0][1])
Producción:
Publicación traducida automáticamente
Artículo escrito por deepanshu_rustagi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA