En este artículo, discutiremos cómo dividir un marco de datos R grande en listas de marcos de datos más pequeños. En el lenguaje de programación R tenemos una función llamada split() que se usa para dividir el marco de datos en partes.
Entonces, para hacer esto, primero creamos un ejemplo de un marco de datos que se necesita dividir.
Creando marco de datos:
R
# create the data frame
data <- data.frame(id = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
x1 = 11 : 20,
x2 = 110 : 110)
# print the dataframe
data
Producción:

Para dividir el marco de datos anterior, usamos la función split() . La sintaxis de la función split() es:
Sintaxis: split(x, f, drop = FALSO, …)
Parámetros:
- x significa marco de datos y vector
- f representa la agrupación de vectores o la selección de la columna según la cual dividimos el marco de datos
- drop significa eliminar u omitir la fila especificada
Ejemplo 1: en este ejemplo, intentamos ejecutar la función de división sin ningún argumento, excepto el marco de datos anterior.
Cuando ejecutamos la función de división sin ningún argumento, excepto el marco de datos, notamos que la función de división devuelve la combinación de cada elemento de la columna 1 con las otras columnas. En nuestro caso, hay 3 elementos distintos en la columna 1 y un total de 10 filas en el marco de datos. Entonces, las filas totales como salida son 3 * 10 = 30 filas en nuestra salida.
R
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = 11 : 20,
a3 = 110 : 110)
# split the dataframe using the
# split function
split_data <- split(data, f = data)
# print the splitted data frame
split_data
Producción:

Nota: La captura de pantalla de salida anterior es 1/3 de la salida real, debido a la concisión.
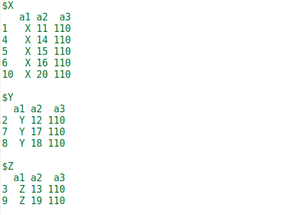
Ejemplo 2: en este ejemplo, dividiremos el Dataframe agrupando con la ayuda de 1 columna.
Para ello utilizaremos el argumento “f” de la función de división y “$” se utiliza para seleccionar la columna según la cual vamos a dividir el Dataframe. En nuestro caso, vamos a dividir el marco de datos según la columna a1.
R
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = 11 : 20,
a3 = 110 : 110)
# split the data frame by grouping using "f" argument
split_data <- split(data, f = data$a1)
# print the split data
split_data
Producción:
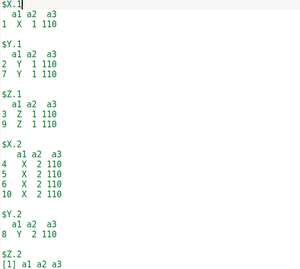
Ejemplo 3: en este ejemplo, dividiremos el Dataframe agrupando con la ayuda de 2 columnas.
Para hacer esto usaremos el argumento “f” de la función de división y “$” se usa para seleccionar las columnas y hacer una lista de las columnas según las cuales vamos a dividir el Dataframe. En nuestro caso, vamos a dividir el marco de datos según las columnas a1 y a2. Entonces, se crea una lista de a1 y a2 y esta lista se da como argumento para la «f».
R
# create the data frame
data <- data.frame(a1 = c("X", "Y", "Z", "X", "X",
"X", "Y", "Y", "Z", "X"),
a2 = c(1, 1, 1, 2, 2, 2,
1, 2, 1, 2),
a3 = 110 : 110)
# split the data frame by grouping using "f" argument
split_data <- split(data, f=list(data$a1, data$a2))
# print the split data
split_data
Producción:
Publicación traducida automáticamente
Artículo escrito por parasharraghav y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA