Veamos cómo dividir una columna de texto en dos columnas en Pandas DataFrame.
Método #1: Uso de Series.str.split()funciones.
Divida la columna Nombre en dos columnas diferentes. Por defecto, la división se realiza sobre la base de un solo espacio por str.split()función.
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John Larter', 'Robert Junior', 'Jonny Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
# bydefault splitting is done on the basis of single space.
print("\nSplitting 'Name' column into two different columns :\n",
df.Name.str.split(expand=True))
Salida: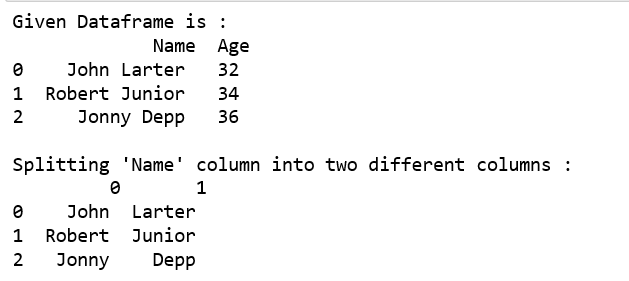
Divida la columna Nombre en la columna «Primera» y «Última» respectivamente y agréguela al marco de datos existente.
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John Larter', 'Robert Junior', 'Jonny Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
# Adding two new columns to the existing dataframe.
# bydefault splitting is done on the basis of single space.
df[['First','Last']] = df.Name.str.split(expand=True)
print("\n After adding two new columns : \n", df)
Producción: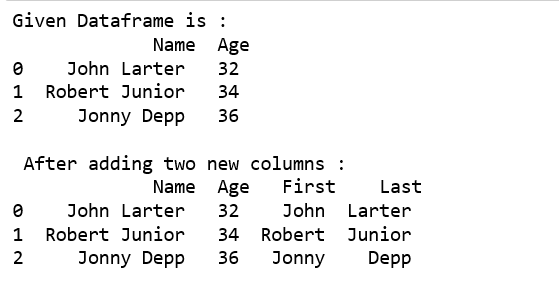
Utilice el guión bajo como delimitador para dividir la columna en dos columnas.
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John_Larter', 'Robert_Junior', 'Jonny_Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
# Adding two new columns to the existing dataframe.
# splitting is done on the basis of underscore.
df[['First','Last']] = df.Name.str.split("_",expand=True)
print("\n After adding two new columns : \n",df)
Salida: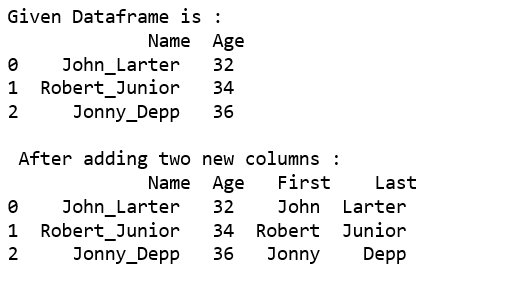
Uso str.split(), tolist()funcionan juntos.
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John_Larter', 'Robert_Junior', 'Jonny_Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
print("\nSplitting Name column into two different columns :")
print(pd.DataFrame(df.Name.str.split('_',1).tolist(),
columns = ['first','Last']))
Salida: 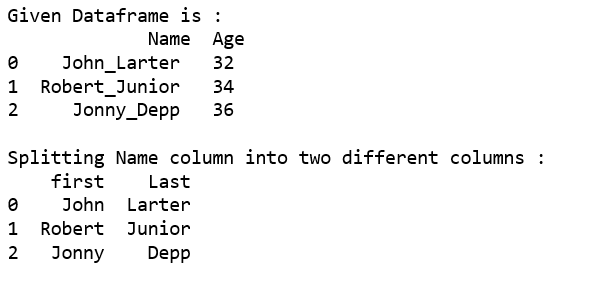
Método #2: Uso de apply()la función.
Divida la columna Nombre en dos columnas diferentes.
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John_Larter', 'Robert_Junior', 'Jonny_Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
print("\nSplitting Name column into two different columns :")
print(df.Name.apply(lambda x: pd.Series(str(x).split("_"))))
Producción :
Divida la columna Nombre en dos columnas diferentes nombradas como «Primero» y «Último» respectivamente y luego agréguela al marco de datos existente.
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John_Larter', 'Robert_Junior', 'Jonny_Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
print("\nSplitting Name column into two different columns :")
# splitting 'Name' column into Two columns
# i.e. 'First' and 'Last'respectively and
# Adding these columns to the existing dataframe.
df[['First','Last']] = df.Name.apply(
lambda x: pd.Series(str(x).split("_")))
print(df)
Producción :