Podemos probar diferentes enfoques para dividir Dataframe para obtener los resultados deseados. Tomemos un ejemplo de un conjunto de datos de diamantes.
Python3
# importing libraries
import seaborn as sns
import pandas as pd
import numpy as np
# data needs not to be downloaded separately
df = sns.load_dataset('diamonds')
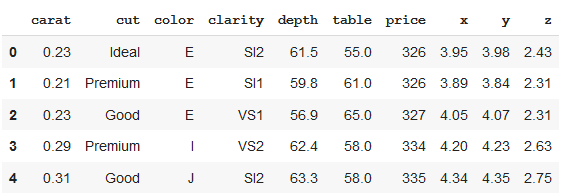
df.head()
Producción:
Método 1: dividir el marco de datos de Pandas por índice de fila
En el siguiente código, el marco de datos se divide en dos partes, las primeras 1000 filas y las filas restantes. Podemos ver la forma de los marcos de datos recién formados como la salida del código dado.
Python3
# splitting dataframe by row index
df_1 = df.iloc[:1000,:]
df_2 = df.iloc[1000:,:]
print("Shape of new dataframes - {} , {}".format(df_1.shape, df_2.shape))
Producción:
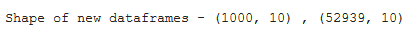
Método 2: dividir el marco de datos de Pandas por grupos formados a partir de valores de columna únicos
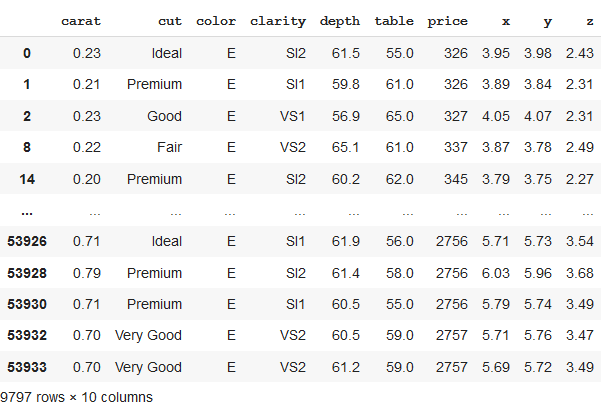
Aquí, primero agruparemos los datos por valor de columna «color». El marco de datos recién formado consta de datos agrupados con color = «E».
Python3
# splitting dataframe by groups
# grouping by particular dataframe column
grouped = df.groupby(df.color)
df_new = grouped.get_group("E")
df_new
Producción:
Método 3: dividir el marco de datos de Pandas en fragmentos de tamaño predeterminado
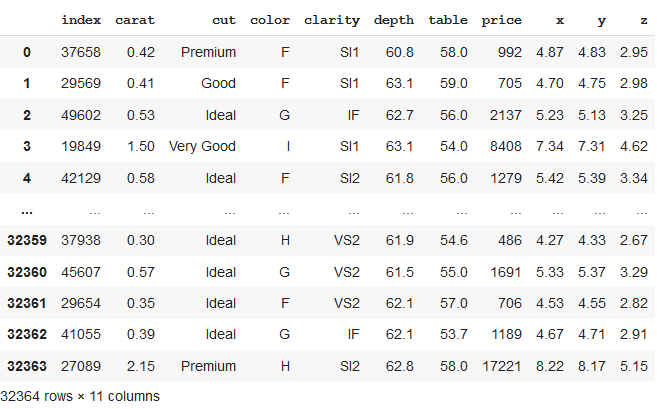
En el código anterior, podemos ver que hemos formado un nuevo conjunto de datos de un tamaño de 0,6, es decir, el 60 % del total de filas (o la longitud del conjunto de datos), que ahora consta de 32364 filas . Estas filas se seleccionan al azar.
Python3
# splitting dataframe in a particular size df_split = df.sample(frac=0.6,random_state=200) df_split.reset_index()
Producción:
Publicación traducida automáticamente
Artículo escrito por devanshigupta1304 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA