A veces, para analizar el marco de datos con mayor precisión, necesitamos dividirlo en 2 o más partes. Los pandas proporcionan la función para dividir Dataframe según el índice de columna, el índice de fila y los valores de columna, etc.
¿Veamos cómo dividir el marco de datos de Pandas por valor de columna en Python?
Ahora, vamos a crear un marco de datos:
villanos
Python3
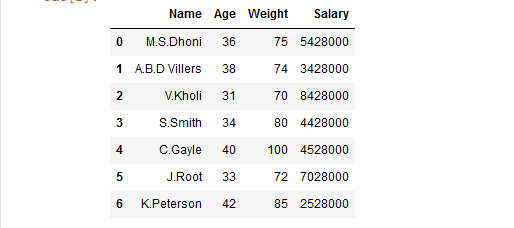
# importing pandas library import pandas as pd # Initializing the nested list with Data-set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villiers', 38, 74, 3428000], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', 40, 100, 4528000], ['J.Root', 33, 72, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns = ['Name', 'Age', 'Weight', 'Salary']) # show the dataframe df
Producción:
Método 1: Usar el enfoque de enmascaramiento booleano .
Este método se utiliza para imprimir solo la parte del marco de datos en la que pasamos un valor booleano True.
Ejemplo 1:
Python3
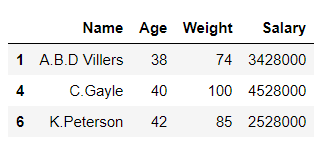
# importing pandas library import pandas as pd # Initializing the nested list with Data-set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villiers', 38, 74, 3428000], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', 40, 100, 4528000], ['J.Root', 33, 72, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns = ['Name', 'Age', 'Weight', 'Salary']) # splitting the dataframe into 2 parts # on basis of 'Age' column values # using Relational operator df1 = df[df['Age'] >= 37] # printing df1 df1
Producción:
Python3
df2 = df[df['Age'] < 37] # printing df2 df2
Producción:
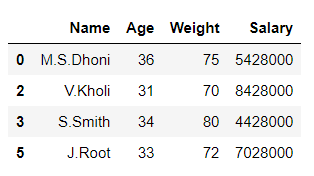
En el ejemplo anterior, el marco de datos ‘df’ se divide en 2 partes ‘df1’ y ‘df2’ en función de los valores de la columna ‘ Edad ‘.
Ejemplo 2:
Python3
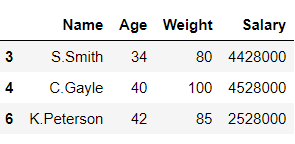
# importing pandas library import pandas as pd # Initializing the nested list with Data-set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villiers', 38, 74, 3428000], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', 40, 100, 4528000], ['J.Root', 33, 72, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns = ['Name', 'Age', 'Weight', 'Salary']) # splitting the dataframe into 2 parts # on basis of 'Weight' column values mask = df['Weight'] >= 80 df1 = df[mask] # invert the boolean values df2 = df[~mask] # printing df1 df1
Producción:
Python3
# printing df2 df2
Producción:
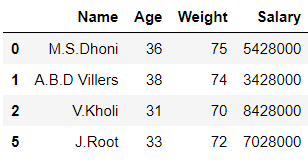
En el ejemplo anterior, el marco de datos ‘df’ se divide en 2 partes ‘df1’ y ‘df2’ en función de los valores de la columna ‘ Peso ‘.
Método 2: Usar Dataframe.groupby() .
Este método se utiliza para dividir los datos en grupos según algunos criterios.
Ejemplo:
Python3
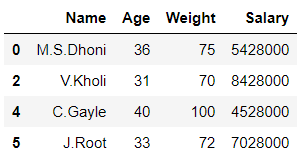
# importing pandas library import pandas as pd # Initializing the nested list with Data-set player_list = [['M.S.Dhoni', 36, 75, 5428000], ['A.B.D Villiers', 38, 74, 3428000], ['V.Kholi', 31, 70, 8428000], ['S.Smith', 34, 80, 4428000], ['C.Gayle', 40, 100, 4528000], ['J.Root', 33, 72, 7028000], ['K.Peterson', 42, 85, 2528000]] # creating a pandas dataframe df = pd.DataFrame(player_list, columns = ['Name', 'Age', 'Weight', 'Salary']) # splitting the dataframe into 2 parts # on basis of 'Salary' column values # using dataframe.groupby() function df1, df2 = [x for _, x in df.groupby(df['Salary'] < 4528000)] # printing df1 df1
Producción:
Python3
# printing df2 df2
Producción:
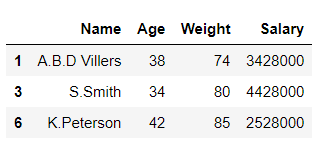
En el ejemplo anterior, el marco de datos ‘df’ se divide en 2 partes ‘df1’ y ‘df2’ en función de los valores de la columna ‘ Salario ‘.
Publicación traducida automáticamente
Artículo escrito por vanshgaur14866 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA