Dados algunos datos mixtos que contienen múltiples valores como una string, veamos cómo podemos dividir las strings usando expresiones regulares y crear varias columnas en Pandas DataFrame.
Método #1 :
En este método usaremos re.search(pattern, string, flags=0). Aquí patrón se refiere al patrón que queremos buscar. Toma una string con los siguientes valores:
- \w coincide con caracteres alfanuméricos
- \d coincide con dígitos, lo que significa 0-9
- \s coincide con los caracteres de espacio en blanco
- \S coincide con caracteres que no son espacios en blanco
- . coincide con cualquier carácter excepto el carácter de nueva línea \n
- * coincide con 0 o más instancias de un patrón
# import the regex library
import pandas as pd
import re
# Create a list with all the strings
movie_data = ["Name: The_Godfather Year: 1972 Rating: 9.2",
"Name: Bird_Box Year: 2018 Rating: 6.8",
"Name: Fight_Club Year: 1999 Rating: 8.8"]
# Create a dictionary with the required columns
# Used later to convert to DataFrame
movies = {"Name":[], "Year":[], "Rating":[]}
for item in movie_data:
# For Name field
name_field = re.search("Name: .*",item)
if name_field is not None:
name = re.search('\w*\s\w*',name_field.group())
else:
name = None
movies["Name"].append(name.group())
# For Year field
year_field = re.search("Year: .*",item)
if year_field is not None:
year = re.search('\s\d\d\d\d',year_field.group())
else:
year = None
movies["Year"].append(year.group().strip())
# For rating field
rating_field = re.search("Rating: .*",item)
if rating_field is not None:
rating = re.search('\s\d.\d',rating_field.group())
else:
rating - None
movies["Rating"].append(rating.group().strip())
# Creating DataFrame
df = pd.DataFrame(movies)
print(df)
Producción: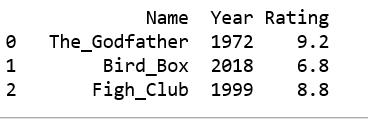
Explicación:
- En el código anterior, usamos un ciclo for para iterar a través de los datos de la película para que podamos trabajar con cada película a la vez. Creamos un diccionario, películas, que contendrá todos los detalles de cada detalle, como la calificación y el nombre.
- Luego encontramos todo el campo Nombre usando la
re.search()función. el . significa cualquier carácter excepto \n, y * lo extiende hasta el final de la línea. Asigne esto a la variable name_field . - Pero, los datos no siempre son sencillos. Puede contener sorpresas. Por ejemplo, ¿qué sucede si no hay un campo Nombre:? El script lanzaría un error y se rompería. Nos adelantamos a los errores de este escenario y buscamos un caso que no sea Ninguno .
- Nuevamente usamos la función re.search() para extraer la string requerida final del campo nombre. Para el nombre usamos \w* para representar la primera palabra, \s para representar el espacio entre ellas y \w* para la segunda palabra.
- Haga lo mismo para el año y la calificación y obtenga el diccionario final requerido.
Método #2:
Para dividir la string usaremos Series.str.extract(pat, flags=0, expand=True)la función. Aquí pat se refiere al patrón que queremos buscar.
import pandas as pd
dict = {'movie_data':['The Godfather 1972 9.2',
'Bird Box 2018 6.8',
'Fight Club 1999 8.8'] }
# Convert the dictionary to a dataframe
df = pd.DataFrame(dict)
# Extract name from the string
df['Name'] = df['movie_data'].str.extract('(\w*\s\w*)', expand=True)
# Extract year from the string
df['Year'] = df['movie_data'].str.extract('(\d\d\d\d)', expand=True)
# Extract rating from the string
df['Rating'] = df['movie_data'].str.extract('(\d\.\d)', expand=True)
print(df)
Producción:
Publicación traducida automáticamente
Artículo escrito por rohitmidha23 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA