En SQL, algunas filas contienen entradas duplicadas en varias columnas (>1). Para eliminar tales filas, necesitamos usar la palabra clave DELETE junto con la autounión de la tabla consigo misma. Lo mismo se ilustra a continuación. Para este artículo, utilizaremos Microsoft SQL Server como nuestra base de datos.
Paso 1: crear una base de datos. Para esto, use el siguiente comando para crear una base de datos llamada GeeksForGeeks.
Consulta:
CREATE DATABASE GeeksForGeeks
Producción:

Paso 2: use la base de datos GeeksForGeeks. Para esto, use el siguiente comando.
Consulta:
USE GeeksForGeeks
Producción:

Paso 3: Cree una tabla RESULTADO dentro de la base de datos GeeksForGeeks. Esta tabla tiene 5 columnas, a saber, STUDENT_ID, PHYSICS_MARKS, CHEMISTRY_MARKS, MATHS_MARKS y TOTAL_MARKS que contienen la identificación del estudiante, sus calificaciones en física, química y matemáticas y, finalmente, sus calificaciones totales.
Consulta:
CREATE TABLE RESULT( STUDENT_ID INT, PHYSICS_MARKS INT, CHEMISTRY_MARKS INT, MATHS_MARKS INT, TOTAL_MARKS INT);
Producción:

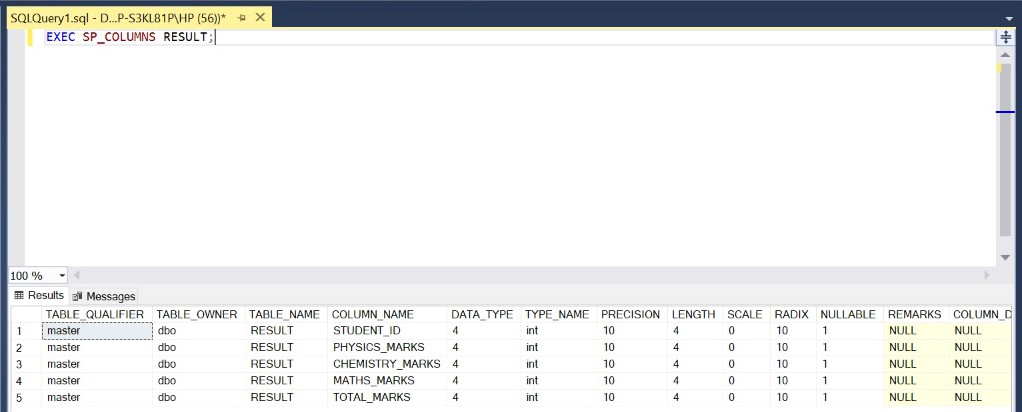
Paso 4: Describa la estructura de la tabla RESULTADO.
Consulta:
EXEC SP_COLUMNS RESULT;
Producción:
Paso 5: Inserte 10 filas en la tabla RESULTADO.
Consulta:
INSERT INTO RESULT VALUES(1,90,88,75,253); INSERT INTO RESULT VALUES(2,99,88,75,262); INSERT INTO RESULT VALUES(3,96,88,75,256); INSERT INTO RESULT VALUES(4,97,87,76,260); INSERT INTO RESULT VALUES(5,91,86,77,254); INSERT INTO RESULT VALUES(6,92,85,78,255); INSERT INTO RESULT VALUES(7,93,84,79,256); INSERT INTO RESULT VALUES(8,80,83,87,250); INSERT INTO RESULT VALUES(9,80,82,88,250); INSERT INTO RESULT VALUES(10,80,81,89,250);
Producción:
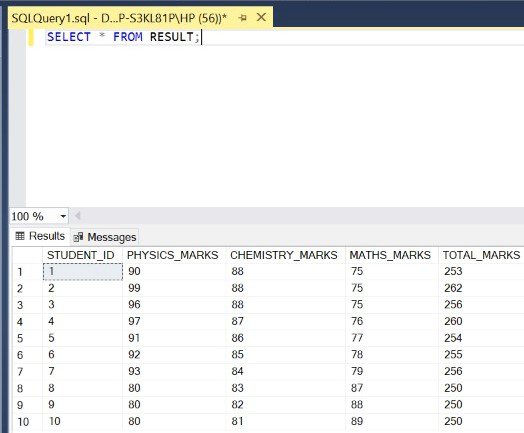
Paso 6: Muestre todas las filas de la tabla de RESULTADOS.
Consulta:
SELECT * FROM RESULT;
Producción:
Paso 7: elimine las filas de la tabla RESULTADO que tienen entradas duplicadas en las columnas CHEMISTRY_MARKS y MATHS_MARKS . Para lograr esto, usamos la función DELETE uniéndonos automáticamente (use la función JOIN en 2 alias de la tabla, es decir, R1 y R2 ) la tabla consigo misma y comparando las entradas de las columnas CHEMISTRY_MARKS y MATHS_MARKS para diferentes entradas de la columna STUDENT_ID porque ID es único para cada estudiante.
Sintaxis:
DELETE T1 FROM TABLE_NAME T1 JOIN TABLE_NAME T2 ON T1.COLUMN_NAME2 = T2.COLUMN_NAME2 AND T1.COLUMN_NAME3 = T2.COLUMN_NAME3 AND ....... AND T2.COLUMN_NAME1 < T1.COLUMN_NAME1;
Consulta:
DELETE R1 FROM RESULT R1 JOIN RESULT R2 ON R1.CHEMISTRY_MARKS = R2.CHEMISTRY_MARKS AND R1.MATHS_MARKS = R2.MATHS_MARKS AND R2.STUDENT_ID < R1.STUDENT_ID;
Producción:

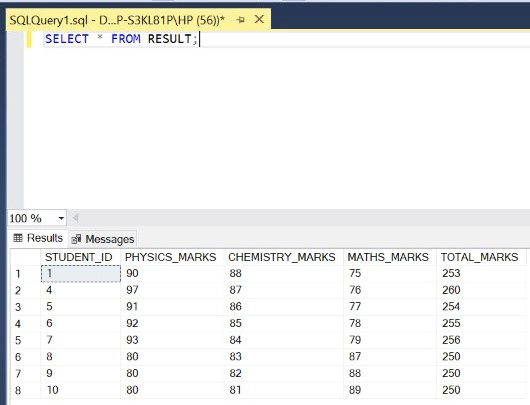
Paso 8: Muestre todas las filas de la tabla de RESULTADOS actualizada.
Consulta:
SELECT * FROM RESULT;
Nota: ninguna fila tiene entradas duplicadas en las columnas CHEMISTRY_MARKS y MATHS_MARKS .
Producción:
Paso 9: elimine las filas de la tabla RESULTADO que tienen entradas duplicadas en las columnas TOTAL_MARKS y PHYSICS_MARKS .
Consulta:
DELETE R1 FROM RESULT R1 JOIN RESULT R2 ON R1.TOTAL_MARKS = R2.TOTAL_MARKS AND R1.PHYSICS_MARKS = R2.PHYSICS_MARKS AND R2.STUDENT_ID < R1.STUDENT_ID;
Producción:

Paso 10: Muestre todas las filas de la tabla de RESULTADOS actualizada.
Consulta:
SELECT * FROM RESULT;
Nota : ninguna fila tiene entradas duplicadas en las columnas TOTAL_MARKS y PHYSICS_MARKS .
Producción:

Publicación traducida automáticamente
Artículo escrito por abhisri459 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA