Prácticamente durante cualquier encuesta para la recolección de datos, no es posible obtener toda la información de todas las unidades, ya que a veces obtenemos información parcial ya veces nada. Por lo tanto, es posible que algunas filas de nuestros datos estén completamente en blanco y algunas puedan tener datos parciales. Las filas en blanco se pueden eliminar y los otros valores vacíos se pueden llenar con métodos que ayuden a lidiar con la información faltante.
Además, leer el archivo de Excel con algunas celdas vacías también puede producir errores a veces, lo que finalmente afecta la precisión del modelo. Por lo tanto, la eliminación de celdas vacías es un proceso importante.
Para eliminar filas con celdas vacías contamos con una sintaxis en lenguaje R, con la cual es mucho más fácil para el usuario eliminar la mayor cantidad de filas vacías en el archivo de Excel.
Pasos –
- Datos de importacion
- Seleccionar filas con celdas vacías
- Eliminar tales filas
- Copiar al marco de datos original
Sintaxis:
datos <- datos[!aplicar(datos == “”, 1, todos),]
Ejemplo 1:
Archivo utilizado:

R
gfg_data=read.csv('input_gfg.csv')
gfg_data <- gfg_data[!apply(is.na(gfg_data) | gfg_data == "", 1, all),]
print(gfg_data)
Producción:

Ejemplo 2:
Archivo en uso:
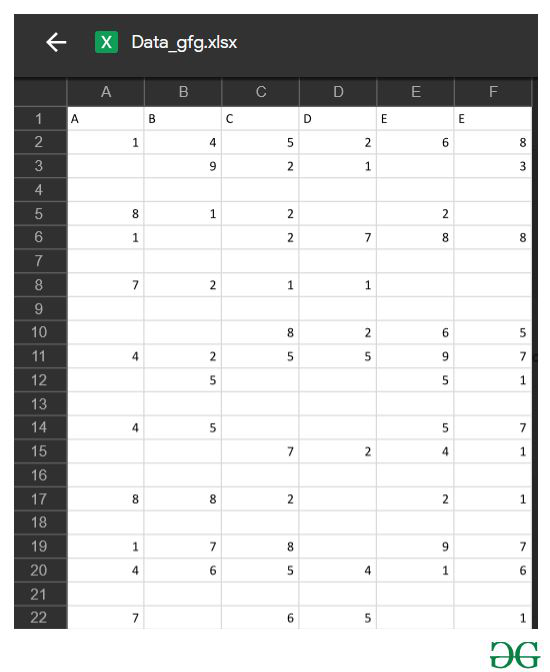
R
library(readxl)
gfg_data <- read_excel("Data_gfg.xlsx")
print("original dataset:-")
print(gfg_data)
gfg_data <- gfg_data[!apply(is.na(gfg_data) | gfg_data == "", 1, all),]
print("Modified dataset:-")
print(gfg_data)
Producción:
