Las columnas de DataFrame en lenguaje de programación R pueden tener valores vacíos representados por NA . En este artículo, vamos a ver cómo eliminar filas con NA en una columna. Veremos varios enfoques para eliminar filas con valores NA.
Datos en uso:
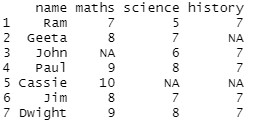
Acercarse
- Crear un marco de datos
- Seleccione la columna sobre la base de qué filas se eliminarán
- Atraviesa la columna buscando valores de na
- Seleccionar filas
- Eliminar tales filas usando un método específico
Método 1: Usar drop_na()
drop_na() Suelta filas que tienen valores iguales a NA. Para usar este enfoque, necesitamos usar la biblioteca «tidyr», que se puede instalar.
install.packages(“tidyverse”)
Sintaxis:
drop_na(nombre_de_la_columna)
Ejemplo:
R
# Creating dataframe
student=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Jim","Dwight")
,maths=c(7,8,NA,9,10,8,9)
,science=c(5,7,6,8,NA,7,8)
,history=c(7,NA,7,7,NA,7,7))
print(student)
library(tidyr)
student %>% drop_na(maths)
Producción:
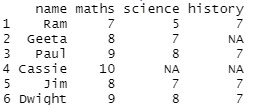
Método 2: Usar is.na()
La función is.na() primero busca valores na en una columna y luego descarta esas filas.
Sintaxis:
is.na(nombre de la columna)
Ejemplo:
R
# Creating dataframe
student=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Jim","Dwight")
,maths=c(7,8,NA,9,10,8,9)
,science=c(5,7,6,8,NA,7,8)
,history=c(7,NA,7,7,NA,7,7))
print(student)
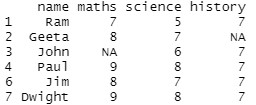
student[!is.na(student$science),]
Producción:
Método 3: Usar complete.cases()
Esta función funciona de manera similar a los dos métodos anteriores.
Sintaxis:
complete.cases(nombre de la columna)
Ejemplo:
R
# Creating dataframe
student=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Jim","Dwight")
,maths=c(7,8,NA,9,10,8,9)
,science=c(5,7,6,8,NA,7,8)
,history=c(7,NA,7,7,NA,7,7))
print(student)
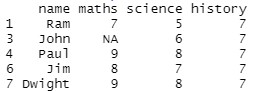
student[complete.cases(student$history),]
Producción:
Publicación traducida automáticamente
Artículo escrito por devangj9689 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA