Pandas proporciona una rica colección de funciones para realizar análisis de datos en Python. Al realizar el análisis de datos, a menudo necesitamos filtrar los datos para eliminar filas o columnas innecesarias.
Ya hemos discutido anteriormente cómo colocar filas o columnas en función de sus etiquetas . Sin embargo, en esta publicación vamos a discutir varios enfoques sobre cómo eliminar filas del marco de datos en función de ciertas condiciones aplicadas en una columna. Conserve todas aquellas filas para las que la condición aplicada en la columna dada se evalúe como True.
Para descargar el CSV utilizado en el código, haga clic aquí .
Se le proporciona el conjunto de datos «nba.csv». Elimina a todos los jugadores del conjunto de datos cuya edad sea inferior a 25 años.
Solución n.º 1: utilizaremos la vectorización para filtrar las filas del conjunto de datos que satisfagan la condición aplicada.
# importing pandas as pd
import pandas as pd
# Read the csv file and construct the
# dataframe
df = pd.read_csv('nba.csv')
# Visualize the dataframe
print(df.head(15)
# Print the shape of the dataframe
print(df.shape)
Producción :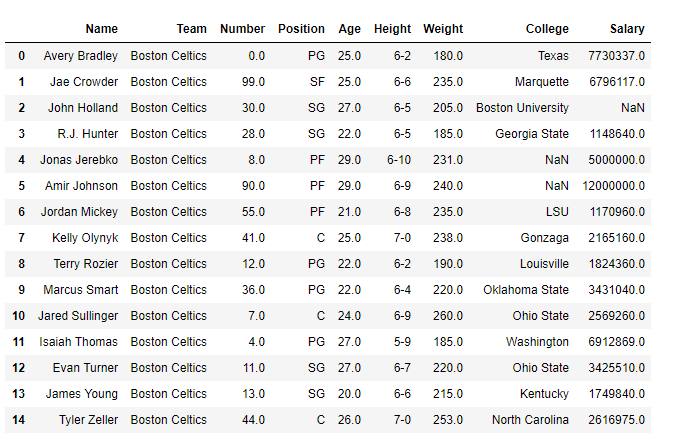
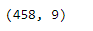
En este marco de datos, actualmente, tenemos 458 filas y 9 columnas. Usemos la operación de vectorización para filtrar todas aquellas filas que satisfagan la condición dada.
# Filter all rows for which the player's # age is greater than or equal to 25 df_filtered = df[df['Age'] >= 25] # Print the new dataframe print(df_filtered.head(15) # Print the shape of the dataframe print(df_filtered.shape)
Salida: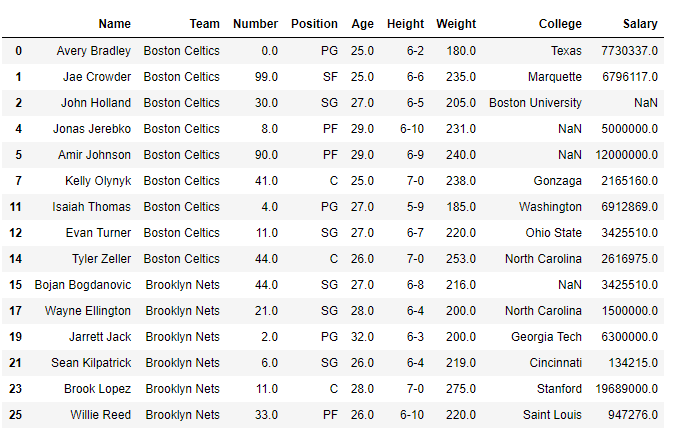
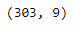
como podemos ver en la salida, el marco de datos devuelto solo contiene aquellos jugadores cuya edad es mayor o igual a 25 años.
Solución n.º 2: podemos usar la DataFrame.drop()función para descartar filas que no cumplan la condición dada.
# importing pandas as pd
import pandas as pd
# Read the csv file and construct the
# dataframe
df = pd.read_csv('nba.csv')
# First filter out those rows which
# does not contain any data
df = df.dropna(how = 'all')
# Filter all rows for which the player's
# age is greater than or equal to 25
df.drop(df[df['Age'] < 25].index, inplace = True)
# Print the modified dataframe
print(df.head(15))
# Print the shape of the dataframe
print(df.shape)
Salida:
como podemos ver en la salida, eliminamos con éxito todas aquellas filas que no cumplen con la condición dada aplicada a la columna ‘Edad’.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA