En este artículo, eliminaremos las filas duplicadas en función de una columna específica del marco de datos usando pyspark en Python. Datos duplicados significa los mismos datos basados en alguna condición (valores de columna). Para esto, estamos usando el método dropDuplicates():
Sintaxis : dataframe.dropDuplicates([‘columna 1′,’columna 2′,’columna n’]).show()
dónde,
- el marco de datos es el marco de datos de entrada y el nombre de la columna es la columna específica
- El método show() se usa para mostrar el marco de datos
Vamos a crear el marco de datos.
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql
# module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of students data
data = [["1", "sravan", "vignan"], ["2", "ojaswi", "vvit"],
["3", "rohith", "vvit"], ["4", "sridevi", "vignan"],
["1", "sravan", "vignan"], ["5", "gnanesh", "iit"]]
# specify column names
columns = ['student ID', 'student NAME', 'college']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
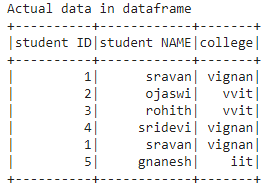
print('Actual data in dataframe')
dataframe.show()
Producción:
Descartar basado en una columna
Python3
# remove duplicate rows based on college # column dataframe.dropDuplicates(['college']).show()
Producción:

Descartar basado en múltiples columnas
Python3
# remove duplicate rows based on college # and ID column dataframe.dropDuplicates(['college', 'student ID']).show()
Producción:

Publicación traducida automáticamente
Artículo escrito por gottumukkalabobby y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA