En este artículo, discutiremos cómo encontrar etiquetas por CSS usando BeautifulSoup. Nos dan un documento HTML, necesitamos encontrar y extraer etiquetas del documento usando la clase CSS.
Ejemplos:
HTML Document:
<html>
<head>
<title> Geeksforgeeks </title>
</head>
<body>
<div class="ext" >Extract this tag</div>
</body>
</html>
Output:
<div class="ext" >Extract this tag</div>
Módulos Requeridos:
- bs4: es una biblioteca de python utilizada para extraer datos de HTML, XML y otros lenguajes de marcado.
Asegúrese de tener pip instalado en su sistema.
Ejecute el siguiente comando en la terminal para instalar esta biblioteca:
pip install bs4 or pip install beautifulsoup4
Acercarse:
- Importar biblioteca bs4
- Crear un documento HTML
- Analizar el contenido en un objeto BeautifulSoup
- Búsqueda por clase CSS: el nombre del atributo CSS, «clase» , es una palabra reservada en Python. El compilador da un error de sintaxis si la clase se usa como argumento de palabra clave. Podemos buscar clases CSS usando el argumento de palabra clave class_
Podemos pasar class_ una string, una expresión regular, una función o True. - find_all() con el argumento de palabra clave class_ se usa para encontrar todas las etiquetas con la clase CSS dada.
Si necesitamos encontrar solo una etiqueta, se usa find() - Imprime las etiquetas extraídas.
Ejemplo 1: Encuentra la etiqueta usando el método find()
Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
<html>
<head>
<title> Geeksforgeeks </title>
</head>
<body>
<div class="ext" >Extract this tag</div>
</body>
</html>
"""
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class
div = soup.find("div", class_= "ext")
# Print the extracted tag
print(div)
# Function Call
find_tags_from_class(HTML_DOC)
Producción:

Ejemplo 2: Encuentra todas las etiquetas usando el método find_all()
Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
<html>
<head>
<title> Table Data </title>
</head>
<body>
<table>
<tr>
<td class = "table-row"> This is row 1 </td>
<td class = "table-row"> This is row 2 </td>
<td class = "table-row"> This is row 3 </td>
<td class = "table-row"> This is row 4 </td>
<td class = "table-row"> This is row 5 </td>
</tr>
</table>
</body>
</html>
"""
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class
rows = soup.find_all("td", class_= "table-row")
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)
Producción:

Ejemplo 3: Encontrar etiquetas por clase CSS usando expresiones regulares.
Python3
# Import Module
from bs4 import BeautifulSoup
import re
# HTML Document
HTML_DOC = """
<html>
<head>
<title> Table Data </title>
</head>
<body>
<table>
<tr>
<td class = "table"> This is row 1 </td>
<td class = "table-row"> This is row 2 </td>
<td class = "table"> This is row 3 </td>
<td class = "table-row"> This is row 4 </td>
<td class = "table"> This is row 5 </td>
</tr>
</table>
</body>
</html>
"""
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class using regular expressions
# $ is used to match pattern ending with
# Here we are finding class that ends with "row"
rows = soup.find_all("td", class_= re.compile("row$"))
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)
Producción:

Explicación:
<td class="table-row"> This is row 2 </td> <td class="table-row"> This is row 4 </td>
Por encima de las dos etiquetas, el nombre de la clase termina en «fila». Por lo tanto, se extraen. El nombre de la clase de otras etiquetas no termina con «fila». Por lo tanto, no se extraen.
Ejemplo 4: Encontrar etiquetas por clase CSS utilizando la función definida por el usuario.
Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
<html>
<head>
<title> Table Data </title>
</head>
<body>
<table>
<tr>
<td class = "table"> This is invalid because len(table) != 3 </td>
<td class = "row"> This is valid because len(row) == 3 </td>
<td class = "data"> This is invalid because len(data) != 3 </td>
<td class = "hii"> This is valid because len(hii) == 3 </td>
<td> This is invalid because class is None </td>
</tr>
</table>
</body>
</html>
"""
# Returns true if the css_class is not None
# and length of css_class is equal to 3
# else returns false
def has_three_characters(css_class):
return css_class is not None and len(css_class) == 3
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
# find tags by CSS class using user-defined function
rows = soup.find_all("td", class_= has_three_characters)
# Print the extracted tag
for row in rows:
print(row)
# Function Call
find_tags_from_class(HTML_DOC)
Producción:

Ejemplo 5: Encontrar etiquetas por clase CSS de un sitio web
Python3
# Import Module
from bs4 import BeautifulSoup
import requests
# Assign website
import requests
URL = "https://www.geeksforgeeks.org/"
HTML_DOC = requests.get(URL)
# Function to find tags
def find_tags_from_class(html):
# parse html content
soup = BeautifulSoup(html.content, "html5lib")
# find tags by CSS class
div = soup.find("div", class_= "article--container_content")
# Print the extracted tag
print(div)
# Function Call
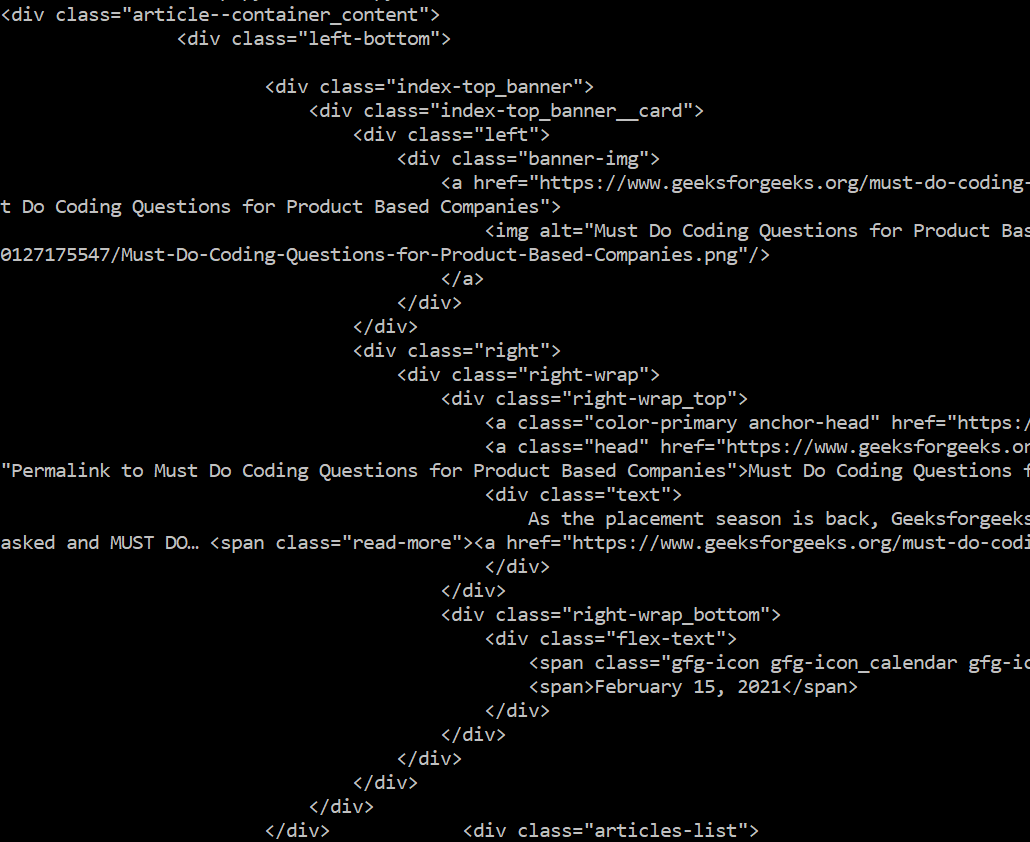
find_tags_from_class(HTML_DOC)
Producción:
Publicación traducida automáticamente
Artículo escrito por yuvraj_chandra y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA