En este artículo, discutiremos cómo encontrar filas duplicadas en un marco de datos basado en todas las columnas o en una lista. Para esto, usaremos el método Dataframe.duplicated() de Pandas.
Sintaxis: DataFrame.duplicated(subconjunto = Ninguno, mantener = ‘primero’)
Parámetros:
subconjunto: Toma una columna o lista de etiquetas de columna. Su valor predeterminado es Ninguno. Después de pasar columnas, las considerará solo para duplicados.
mantener: esto controla cómo considerar el valor duplicado. Solo tiene tres valores distintos y el valor predeterminado es ‘primero’.
- Si es ‘primero’ , esto considera el primer valor como único y el resto de los mismos valores como duplicados.
- Si es ‘último’ , esto considera el último valor como único y el resto de los mismos valores como duplicados.
- Si es ‘Falso’ , esto considera todos los mismos valores como duplicados.
Devuelve: serie booleana que indica filas duplicadas.
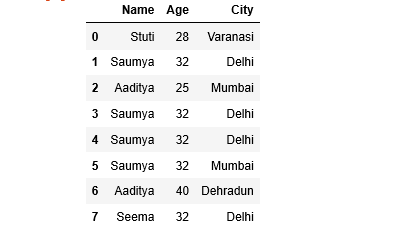
Vamos a crear un marco de datos simple con un diccionario de listas, digamos que los nombres de las columnas son: ‘Nombre’, ‘Edad’ y ‘Ciudad’.
Python3
# Import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Print the Dataframe
df
Producción :
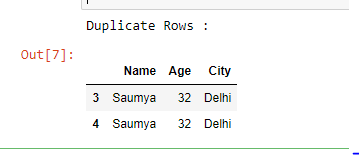
Ejemplo 1: seleccione filas duplicadas en función de todas las columnas.
Aquí, no pasamos ningún argumento, por lo tanto, toma valores predeterminados para ambos argumentos, es decir, subconjunto = Ninguno y mantener = ‘primero’.
Python3
# Import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows except first
# occurrence based on all columns
duplicate = df[df.duplicated()]
print("Duplicate Rows :")
# Print the resultant Dataframe
duplicate
Producción :
Ejemplo 2: seleccione filas duplicadas en función de todas las columnas.
Si desea considerar todos los duplicados excepto el último, pase keep = ‘last’ como argumento.
Python3
# Import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows except last
# occurrence based on all columns.
duplicate = df[df.duplicated(keep = 'last')]
print("Duplicate Rows :")
# Print the resultant Dataframe
duplicate
Producción :

Ejemplo 3: si desea seleccionar filas duplicadas basándose solo en algunas columnas seleccionadas, pase la lista de nombres de columna en el subconjunto como argumento.
Python3
# import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
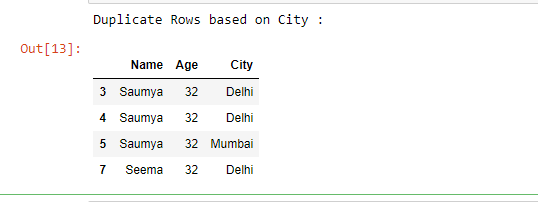
# Selecting duplicate rows based
# on 'City' column
duplicate = df[df.duplicated('City')]
print("Duplicate Rows based on City :")
# Print the resultant Dataframe
duplicate
Producción :
Ejemplo 4: seleccione filas duplicadas en función de más de un nombre de columna.
Python3
# import pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
# Creating a DataFrame object
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
# Selecting duplicate rows based
# on list of column names
duplicate = df[df.duplicated(['Name', 'Age'])]
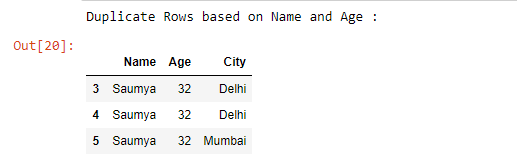
print("Duplicate Rows based on Name and Age :")
# Print the resultant Dataframe
duplicate
Producción :