En un marco de datos R, una fila única significa que ninguno de los elementos de esa fila se replica en todo el marco de datos con la misma combinación. En términos simples, si tenemos un marco de datos llamado df con cuatro columnas y cinco filas, podemos suponer que ninguno de los valores en una fila se replica en todas las demás filas.
Si tenemos muchas filas redundantes en nuestra recopilación de datos, es posible que necesitemos buscar ciertos tipos de filas. Podemos usar la función group_by_all del paquete dplyr para lograr esto. Agrupará todas las filas redundantes y devolverá filas únicas con su recuento.
Ejemplo 1:
R
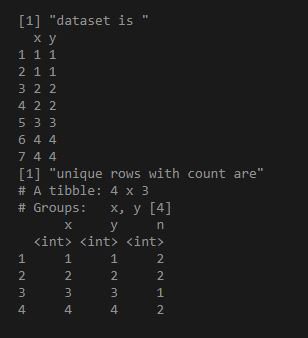
library("dplyr")
df = data.frame(x = as.integer(c(1, 1, 2, 2, 3, 4, 4)),
y = as.integer(c(1, 1, 2, 2, 3, 4, 4)))
print("dataset is ")
print(df)
ans = df%>%group_by_all%>%count
print("unique rows with count are")
print(ans)
Producción:
Ejemplo 2:
R
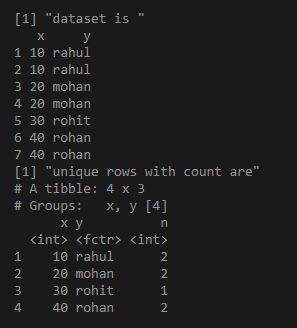
library("dplyr")
df = data.frame(x = as.integer( c(10,10,20,20,30,40,40) ),
y = c("rahul", "rahul", "mohan","mohan", "rohit", "rohan", "rohan"))
print("dataset is ")
print(df)
ans = df%>%group_by_all%>%count
print("unique rows with count are")
print(ans)
Producción:
Publicación traducida automáticamente
Artículo escrito por kapilm180265ca y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA