El enfoque de bosque aleatorio es una clasificación no lineal supervisada y un algoritmo de regresión. La clasificación es un proceso de clasificación de un grupo de conjuntos de datos en categorías o clases. Como enfoque de bosque aleatorio, se pueden utilizar técnicas de clasificación o regresión según el usuario y el objetivo o las categorías necesarias. Un bosque aleatorio es una colección de árboles de decisión que especifica las categorías con una probabilidad mucho mayor. El enfoque de bosque aleatorio se usa sobre el enfoque de árboles de decisión, ya que los árboles de decisión carecen de precisión y los árboles de decisión también muestran poca precisión durante la fase de prueba debido al proceso llamado sobreajuste. En programación R , randomForest()función derandomForestEl paquete se utiliza para crear y analizar el bosque aleatorio. En este artículo, analicemos el bosque aleatorio, aprendamos la sintaxis y la implementación de un enfoque de bosque aleatorio para la clasificación en la programación R, y se trazará un gráfico adicional para la inferencia.
Bosque aleatorio
Random forest es un algoritmo de aprendizaje automático que utiliza una colección de árboles de decisión que proporciona más flexibilidad, precisión y facilidad de acceso en la salida. Este algoritmo domina sobre el algoritmo de árboles de decisión, ya que los árboles de decisión proporcionan poca precisión en comparación con el algoritmo de bosque aleatorio. En palabras simples, el enfoque de bosque aleatorio aumenta el rendimiento de los árboles de decisión. Es uno de los mejores algoritmos ya que puede usar técnicas de clasificación y regresión . Al ser un algoritmo de aprendizaje supervisado, el bosque aleatorio utiliza el método de embolsado en los árboles de decisión y, como resultado, aumenta la precisión del modelo de aprendizaje.
El bosque aleatorio busca la mejor característica de un subconjunto aleatorio de características que proporciona más aleatoriedad al modelo y da como resultado un modelo mejor y más preciso. Aprendamos sobre el enfoque de bosque aleatorio con un ejemplo. Supongamos que un hombre llamado Bob quiere comprar una camiseta en una tienda. El vendedor le pregunta primero por su color favorito. Esto constituye un árbol de decisión basado en la característica de color. Además, el vendedor pregunta más sobre la camiseta, como el tamaño, el tipo de tela, el tipo de cuello y muchos más. Más criterios para seleccionar una camiseta harán más árboles de decisión en el aprendizaje automático. Juntos, todos los árboles de decisión constituirán un enfoque de bosque aleatorio para seleccionar una camiseta en función de muchas características que a Bob le gustaría comprar en la tienda.
Clasificación
La clasificación es un enfoque de aprendizaje supervisado en el que los datos se clasifican en función de las características proporcionadas. Como en el ejemplo anterior, los datos se clasifican en diferentes parámetros utilizando un bosque aleatorio. Ayuda a crear más observaciones o clasificaciones significativas. En palabras simples, la clasificación es una forma de categorizar los datos estructurados o no estructurados en algunas categorías o clases. Hay 8 algoritmos de clasificación principales:
- Regresión logística
- bayesiana ingenua
- K-vecinos más cercanos
- Árboles de decisión
- Bosque aleatorio
- Redes neuronales artificiales
- Máquinas de vectores soporte
- Descenso de gradiente estocástico
Algunos ejemplos de clasificación del mundo real son: un correo puede especificarse como spam o no spam, los desechos pueden especificarse como desechos de papel, desechos plásticos, desechos orgánicos o desechos electrónicos, una enfermedad puede determinarse en función de muchos síntomas, análisis de sentimientos, determinación del género mediante expresiones faciales, etc
Implementación del enfoque de bosque aleatorio para la clasificación
Sintaxis:
randomForest(fórmula, datos)Parámetros:
fórmula: representa la fórmula que describe el modelo que se va a ajustar
datos: representa el marco de datos que contiene las variables del modelo
Ejemplo:
en este ejemplo, usemos el aprendizaje supervisado en el conjunto de datos de iris para clasificar las especies de plantas de iris en función de los parámetros pasados en la función.
Paso 1: Instalación de la biblioteca necesaria
# Install the required
# Package for function
install.packages("randomForest")
Paso 2: Cargar la biblioteca requerida
# Load the library library(randomForest)
Paso 3: Uso del conjunto de datos de iris en randomForest()función
# Create random forest # For classification iris.rf <- randomForest(Species ~ ., data = iris, importance = TRUE, proximity = TRUE)
Paso 4: imprima el modelo de clasificación integrado en el paso anterior
# Print classification model print(iris.rf)
Producción:
Call:
randomForest(formula = Species ~ ., data = iris, importance = TRUE, proximity = TRUE)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 2
OOB estimate of error rate: 5.33%
Confusion matrix:
setosa versicolor virginica class.error
setosa 50 0 0 0.00
versicolor 0 47 3 0.06
virginica 0 5 45 0.10
Paso 5: Trazar el gráfico entre el error y el número de árboles
# Output to be present # As PNG file png(file = "randomForestClassification.png") # Plot the error vs # The number of trees graph plot(iris.rf) # Saving the file dev.off()
Salida: 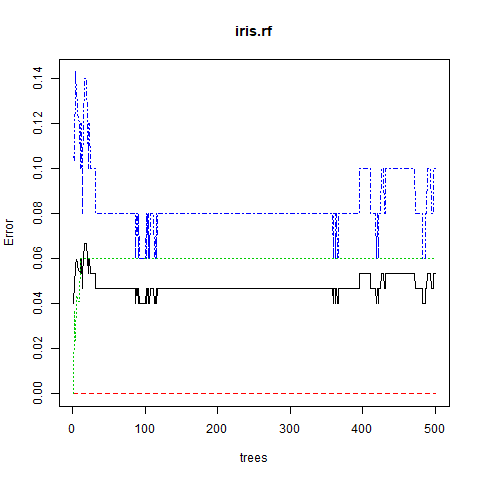
Explicación:
Después de ejecutar el código anterior, se produce la salida que muestra la cantidad de árboles de decisión desarrollados utilizando el modelo de clasificación para algoritmos de bosque aleatorio, es decir, 500 árboles de decisión. La array de confusión también se conoce como la array de error que muestra la visualización del rendimiento del modelo de clasificación.
Publicación traducida automáticamente
Artículo escrito por utkarsh_kumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA