El enfoque Random Forest es un algoritmo de aprendizaje supervisado . Construye los árboles de decisión múltiple que se conocen como bosque y los une para impulsar una predicción más precisa y estable. El enfoque de bosque aleatorio es similar a la técnica de conjunto denominada embolsado. En este enfoque, se generan múltiples árboles mediante muestras de arranque a partir de datos de entrenamiento y luego simplemente reducimos la correlación entre los árboles. La realización de este enfoque aumenta el rendimiento de los árboles de decisión y ayuda a evitar la invalidación. En este artículo, aprendamos a usar un enfoque de bosque aleatorio para la regresión en la programación R.
Características de Random Forest
- Agrega muchos árboles de decisión: un bosque aleatorio es una colección de árboles de decisión y, por lo tanto, no se basa en una sola característica y combina múltiples predicciones de cada árbol de decisión.
- Evita el sobreajuste: con múltiples árboles de decisión, cada árbol extrae una muestra de datos aleatorios, lo que le da al bosque aleatorio más aleatoriedad para producir una precisión mucho mayor que los árboles de decisión.
Ventajas del bosque aleatorio
- Eficiente: los bosques aleatorios son mucho más eficientes que los árboles de decisión cuando funcionan en grandes bases de datos.
- Alta precisión: los bosques aleatorios son muy precisos, ya que son una colección de árboles de decisión y cada árbol de decisión extrae datos aleatorios de muestra y, como resultado, los bosques aleatorios producen una mayor precisión en la predicción.
- Estimaciones eficientes del error de prueba: hace un uso eficiente de todas las características predictivas y mantiene la precisión incluso si faltan los datos.
Desventajas de Random Forest
- Requiere una cantidad diferente de niveles: al ser una colección de árboles de decisión, el bosque aleatorio requiere una cantidad diferente de niveles para una predicción mucho más precisa y sesgada del modelo de entrenamiento.
- Requiere mucha memoria: entrenar un gran conjunto de árboles puede requerir una mayor memoria o memoria paralelizada.
Implementación del método Random Forest para regresión en R
El paquete randomForest en programación R se emplea para crear bosques aleatorios. El bosque que construye es una colección de árboles de decisión. La función randomForest()se utiliza para crear y analizar bosques aleatorios.
Sintaxis:
randomForest(fórmula, datos)Parámetros:
fórmula: representa la fórmula que describe el modelo que se va a ajustar
datos: representa el marco de datos que contiene las variables del modeloPara conocer más parámetros opcionales, use la ayuda del comando («randomForest»)
Ejemplo:
- Paso 1: Instalación de los paquetes necesarios.
# Install the required package for functioninstall.packages("randomForest") - Paso 2: Cargando el paquete requerido.
# Load the librarylibrary(randomForest) - Paso 3: En este ejemplo, usemos el conjunto de datos de calidad del aire presente en R. Imprima el conjunto de datos.
# Print the datasetprint(head(airquality))Salida :
Ozone Solar.R Wind Temp Month Day 1 41 190 7.4 67 5 1 2 36 118 8.0 72 5 2 3 12 149 12.6 74 5 3 4 18 313 11.5 62 5 4 5 NA NA 14.3 56 5 5 6 28 NA 14.9 66 5 6
- Paso 4: crea un bosque aleatorio para la regresión
# Create random forest for regressionozone.rf <-randomForest(Ozone ~ ., data = airquality, mtry = 3,importance =TRUE, na.action = na.omit) - Paso 5: Imprimir modelos de regresión
# Print regression modelprint(ozone.rf)Salida :
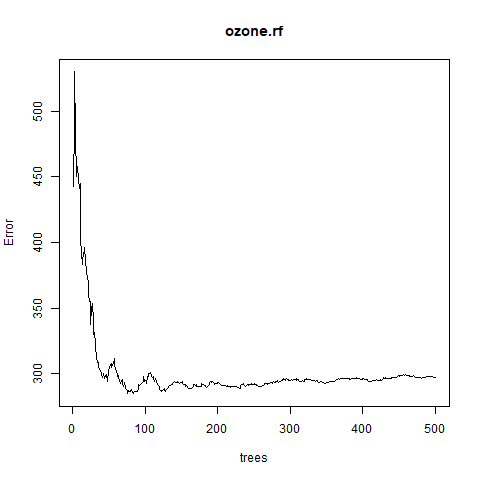
Call: randomForest(formula = Ozone ~ ., data = airquality, mtry = 3, importance = TRUE, na.action = na.omit) Type of random forest: regression Number of trees: 500 No. of variables tried at each split: 3 Mean of squared residuals: 296.4822 % Var explained: 72.98 - Paso 6: Trazar el gráfico entre error y número de árboles
# Output to be present as PNG filepng(file ="randomForestRegression.png")# Plot the error vs the number of trees graphplot(ozone.rf)# Saving the filedev.off()Producción:
Publicación traducida automáticamente
Artículo escrito por utkarsh_kumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA