La raíz del error cuadrático medio (RMSE) es la raíz cuadrada de la media del cuadrado de todo el error. RMSE se considera una excelente métrica de error de propósito general para predicciones numéricas. RMSE es una buena medida de precisión, pero solo para comparar errores de predicción de diferentes modelos o configuraciones de modelos para una variable en particular y no entre variables, ya que depende de la escala. Es la medida de qué tan bien se ajusta una línea de regresión a los puntos de datos. La fórmula para calcular el RMSE es: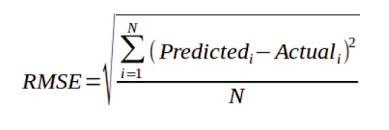
donde,
predicho i = El valor predicho para la i -ésima observación.
real i = El valor observado (real) para la i -ésima observación
N = Número total de observaciones.
Nota: La diferencia entre los valores reales y los valores pronosticados se conoce como residuos.
Implementación de RMSE
La rmse()función disponible en el Metricspaquete en R se usa para calcular el error cuadrático medio entre los valores reales y los valores pronosticados.
Sintaxis:
rmse(real, previsto)Parámetros:
real: El vector numérico de verdad fundamental.
predicho: el vector numérico predicho, donde cada elemento del vector es una predicción para el elemento correspondiente en la realidad.
Ejemplo 1:
definamos dos vectores, un vector real con valores numéricos reales y un vector predicho con valores numéricos predichos, donde cada elemento del vector es una predicción para el elemento correspondiente en la realidad.
# R program to illustrate RMSE # Importing the required package library(Metrics) # Taking two vectors actual = c(1.5, 1.0, 2.0, 7.4, 5.8, 6.6) predicted = c(1.0, 1.1, 2.5, 7.3, 6.0, 6.2) # Calculating RMSE using rmse() result = rmse(actual, predicted) # Printing the value print(result)
Producción:
[1] 0.3464102
Ejemplo 2:
En este ejemplo, tomemos los datos de árboles en la biblioteca de conjuntos de datos que representan los datos de un estudio realizado en cerezos negros.
# Importing required packages library(datasets) library(tidyr) library(dplyr) # Access the data from R’s datasets package data(trees) # Display the data in the trees dataset trees
Producción:
Girth Height Volume
1 8.3 70 10.3
2 8.6 65 10.3
3 8.8 63 10.2
4 10.5 72 16.4
5 10.7 81 18.8
6 10.8 83 19.7
7 11.0 66 15.6
8 11.0 75 18.2
9 11.1 80 22.6
10 11.2 75 19.9
11 11.3 79 24.2
12 11.4 76 21.0
13 11.4 76 21.4
14 11.7 69 21.3
15 12.0 75 19.1
16 12.9 74 22.2
17 12.9 85 33.8
18 13.3 86 27.4
19 13.7 71 25.7
20 13.8 64 24.9
21 14.0 78 34.5
22 14.2 80 31.7
23 14.5 74 36.3
24 16.0 72 38.3
25 16.3 77 42.6
26 17.3 81 55.4
27 17.5 82 55.7
28 17.9 80 58.3
29 18.0 80 51.5
30 18.0 80 51.0
31 20.6 87 77.0
# Look at the structure # Of the variables str(trees)
Producción:
'data.frame': 31 obs. of 3 variables: $ Girth : num 8.3 8.6 8.8 10.5 10.7 10.8 11 11 11.1 11.2 ... $ Height: num 70 65 63 72 81 83 66 75 80 75 ... $ Volume: num 10.3 10.3 10.2 16.4 18.8 19.7 15.6 18.2 22.6 19.9 ...
Este conjunto de datos consta de 31 observaciones de 3 variables numéricas que describen cerezos negros con la circunferencia del tronco, la altura y el volumen como variables. Ahora, intente ajustar un modelo de regresión lineal para predecir el volumen de los troncos sobre la base de la circunferencia del tronco dada. El modelo de regresión lineal simple en R ayudará en este caso. Profundicemos y construyamos un modelo lineal que relacione el volumen del árbol con la circunferencia. R hace esto sencillo con la función base lm(). ¿Qué tan bien funcionará el modelo para predecir el volumen de ese árbol a partir de su circunferencia? Utilice la predict()función, una función R genérica para hacer predicciones de funciones de ajuste de modelos. predict()toma como argumentos, el modelo de regresión lineal y los valores de la variable predictora para la que queremos valores de variable de respuesta.
# Building a linear model # Relating tree volume to girth fit_1 <- lm(Volume ~ Girth, data = trees) trees.Girth = trees %>% select(Girth) # Use predict function to predict volume data.predicted = c(predict(fit_1, data.frame(Girth = trees.Girth))) data.predicted
Producción:
1 2 3 4 5 6 7 8 9
5.103149 6.622906 7.636077 16.248033 17.261205 17.767790 18.780962 18.780962 19.287547
10 11 12 13 14 15 16 17 18
19.794133 20.300718 20.807304 20.807304 22.327061 23.846818 28.406089 28.406089 30.432431
19 20 21 22 23 24 25 26 27
32.458774 32.965360 33.978531 34.991702 36.511459 44.110244 45.630001 50.695857 51.709028
28 29 30 31
53.735371 54.241956 54.241956 67.413183
Ahora tenemos el volumen real de troncos de cerezos y el previsto según los modelos de regresión lineal. Finalmente, use rmse()la función para obtener el error relativo entre los valores reales y predichos.
# Load the Metrics package library(Metrics) # Applying rmse() function rmse(trees$Volume, predict(fit_1, data.frame(Girth = trees.Girth)))
Producción:
[1] 4.11254
Como el valor de error es 4,11254, que es una buena puntuación para un modelo lineal. Pero se puede reducir aún más agregando más predictores (modelo de regresión múltiple). Entonces, en resumen, se puede decir que es muy fácil encontrar el error cuadrático medio usando R. Se puede realizar esta tarea usando rmse()la función en R.
Publicación traducida automáticamente
Artículo escrito por misraaakash1998 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA