Convencionalmente, en una prueba de cola superior, la hipótesis nula establece que la verdadera media de la población (μo) es menor que el valor medio hipotético (μ). No podemos rechazar la hipótesis nula si el estadístico de prueba es menor que el valor crítico en el nivel de significancia elegido. En este artículo, analicemos el porcentaje de probabilidad del error tipo II para una prueba de cola superior de la media poblacional con varianza conocida.
El error de tipo II es un error que ocurre si la prueba de hipótesis basada en una muestra aleatoria no puede rechazar la hipótesis nula incluso cuando la verdadera media poblacional μo es mayor que el valor medio hipotético μ.
Aquí la suposición es que la varianza de la población σ2 es desconocida. Sea s2 la varianza muestral. Para n más grande (generalmente >30), la población de las siguientes estadísticas de todas las muestras posibles de tamaño n es aproximadamente una distribución t de Student con n – 1 grado de libertad (DOF).
El rango de medias muestrales para una distribución t de Student se calcula de la siguiente manera
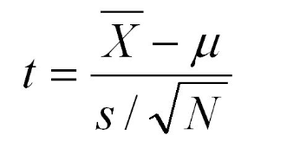
Estadística de prueba
La formulación anterior nos ayuda a calcular el rango de medias muestrales para las que no se rechazará la hipótesis nula y, por lo tanto, calcular la probabilidad de error de tipo II.
Tratemos de comprender el error de tipo II considerando un estudio de caso.
Suponga que la empresa de etiquetado de datos afirma que hay menos de 2 errores en las etiquetas marcadas en una sola página. Suponga que la cantidad media real de error por página 2.12 y la desviación estándar de la muestra es 0.2. Con un nivel de significancia de .05, ¿cuál es la probabilidad de tener un error tipo II para una muestra de 40 páginas?
Ejemplo:
Comencemos por calcular el error estándar de la media como se muestra
R
n = 40 # sample size s = 0.2 # sample standard deviation SE = s/sqrt(n); # standard error estimate SE
Producción:
0.0316227766016838
Luego calcule el límite superior de las medias muestrales para las cuales no se rechazaría la hipótesis nula μo ≤ 2.
R
alpha = .05 # significance level mu0 = 2 # hypothetical upper bound q = mu0 + qt(alpha, df=n-1, lower.tail=FALSE) * SE; q
Producción:
2.05328042957561
El valor del límite superior indica que, siempre que la media de la muestra sea inferior a 2,05328 en una prueba de hipótesis, no se rechazará la hipótesis nula. Intentemos calcular la probabilidad de que la media de la muestra esté por debajo de 2,05328 porque hemos supuesto que la media de la población real es 2,12. Esta probabilidad se puede utilizar además para calcular la probabilidad de error de tipo II.
R
mu = 2.12 # assumed actual mean pt((q - mu)/SE, df=n-1)
Producción:
0.0206695278070304
Si el tamaño de la muestra es 40, la cantidad media real de errores por página es 2,12 y la desviación estándar de la muestra es 0,2, entonces la probabilidad de error tipo II para probar la hipótesis nula μ ≤ 2 a un nivel de significancia de 0,05 es 2,06 %. y la potencia de la prueba de hipótesis es del 97,93%.
Publicación traducida automáticamente
Artículo escrito por jssuriyakumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA