Pandas en python se usa ampliamente para fines de análisis de datos y consta de algunas estructuras de datos finas como Dataframe y Series . Hay varias funciones en pandas que demuestran ser de gran ayuda para un programador, una de ellas es una función agregada. Esta función devuelve un valor único de varios valores tomados como entrada que se agrupan según ciertos criterios. Algunas de las funciones agregadas son promedio, conteo, máximo, entre otras.
Sintaxis: DataFrame.agg(func=Ninguno, eje=0, *args, **kwargs)
Parámetros:
- eje: {0 o ‘índice’, 1 o ‘columnas’} = 0 o ‘índice’ significa que la función se aplica a cada columna y 1 o ‘columnas’ significa que la función se aplica a cada fila.
- func: function, str, list o dict = Describe la función que se utilizará para la agregación. Las combinaciones aceptadas son: función, nombre de función de string (str), lista de funciones (lista/dict).
- *args: Especifica los argumentos posicionales a pasar a la función.
- **kwargs: Especifica los argumentos de la palabra clave para pasar a la función.
Retorno: esta función puede devolver escalar, serie o marco de datos. El retorno es escalar cuando se llama a Series.agg con una sola función, es Series cuando se llama a Dataframe.agg con una sola función, será Dataframe cuando se llama a Dataframe.agg con varias funciones.
Vamos a crear un marco de datos:
Python3
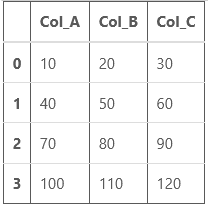
# import pandas library import pandas as pd # create a Dataframe df = pd.DataFrame([[10, 20, 30], [40, 50, 60], [70, 80, 90], [100,110,120]], columns=['Col_A', 'Col_B', 'Col_C']) # show the dataframe df
Producción:
Ahora, vamos a realizar algunas operaciones:
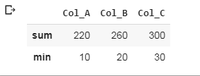
1. Realización de agregación sobre las filas: esto realiza funciones de agregación sobre las filas del marco de datos. Como puede ver en los ejemplos a continuación, el ejemplo 1 tiene dos palabras clave dentro de la función agregada, sum y min. La suma suma el primer (10,40,70,100), segundo (20,50,80,110) y tercer (30,60,90,120) elemento de cada fila por separado y lo imprime, el min encuentra el número mínimo entre los elementos de filas e imprimirlo. Un proceso similar es con el segundo ejemplo.
Ejemplo 1:
Python3
df.agg(['sum', 'min'])
Producción:
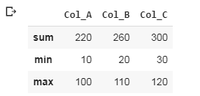
Ejemplo 2:
Python3
df.agg(['sum', 'min', 'max'])
Producción:
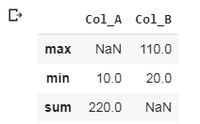
2. Realización de agregación por columna: Esto realiza la función de agregación en las columnas, las columnas se seleccionan particularmente como se muestra en los ejemplos. En el primer ejemplo, se seleccionan dos columnas, ‘Col_A’ y ‘Col_B’ y se van a realizar operaciones sobre ellas. Para Col_A se calcula el valor mínimo y el valor sumado y para Col_B se calcula el valor mínimo y máximo. Un proceso similar es con el ejemplo 2.
Ejemplo 1:
Python3
df.agg({'Col_A' : ['sum', 'min'],
'Col_B' : ['min', 'max']})
Producción:
Ejemplo 2:
Python3
df.agg({'Col_A' : ['sum', 'min'],
'Col_B' : ['min', 'max'],
'Col_C' : ['sum', 'mean']})
Producción:
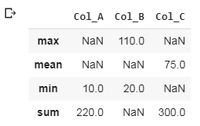
Nota: Imprimirá NaN si no se realiza una agregación en particular en una columna en particular.
3. Realización de agregación sobre las columnas: Esto realiza la función de agregación sobre las columnas. Como se muestra en el ejemplo 1, la media de los elementos primero (10,20,30), segundo (40,50,60), tercero (70,80,90) y cuarto (100,110,120) de cada columna se calcula por separado y se imprime.
Ejemplo:
Python3
df.agg("mean", axis = "columns")
Producción:

4 . Función agregada personalizada: a veces se convierte en una necesidad crear nuestra propia función agregada.
Ejemplo: considere un marco de datos que consiste en la identificación del estudiante (stu_id), el código de la materia (sub_code) y las calificaciones (marcas).
Python3
# import pandas library
import pandas as pd
# Creating DataFrame
df = pd.DataFrame(
{'stud_id' : [101, 102, 103, 104,
101, 102, 103, 104],
'sub_code' : ['CSE6001', 'CSE6001', 'CSE6001',
'CSE6001', 'CSE6002', 'CSE6002',
'CSE6002', 'CSE6002'],
'marks' : [77, 86, 55, 90,
65, 90, 80, 67]}
)
# Printing DataFrame
df
Producción:
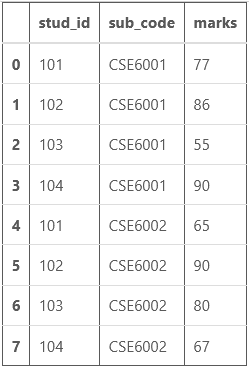
Ahora si necesita calcular las notas totales (notas de dos materias) de cada estudiante (stu_id único). Este proceso se puede realizar mediante la función agregada personalizada. Aquí mi función agregada personalizada es ‘total’.
Python3
# Importing reduce for
# rolling computations
from functools import reduce
# define a Custom aggregation
# function for finding total
def total(series):
return reduce(lambda x, y: x + y, series)
# Grouping the output according to
# student id and printing the corresponding
# total marks and to check whether the
# output is correct or not, sum function
# is also used to print the sum.
df.groupby('stud_id').agg({'marks': ['sum', total]})
Producción:
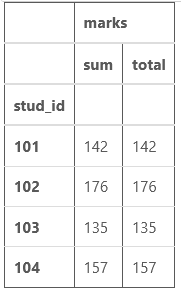
Como puede ver, ambas columnas tienen los mismos valores de calificaciones totales, por lo que nuestra función agregada calcula correctamente las calificaciones totales en este caso.