En las estadísticas descriptivas, describimos nuestros datos con la ayuda de varios métodos representativos, como el uso de cuadros, gráficos, tablas, archivos de Excel, etc. En las estadísticas descriptivas, describimos nuestros datos de alguna manera y los presentamos de manera significativa para que puede entenderse fácilmente. La mayoría de las veces se realiza en conjuntos de datos pequeños y este análisis nos ayuda mucho a predecir algunas tendencias futuras en función de los hallazgos actuales. Algunas medidas que se utilizan para describir un conjunto de datos son medidas de tendencia central y medidas de variabilidad o dispersión.
Tipos de estadística descriptiva:
- Medida de tendencia central
- Medida de variabilidad
Medida de tendencia central:
Representa todo el conjunto de datos por un solo valor. Nos da la ubicación de los puntos centrales. Hay tres medidas principales de tendencia central:
- Significar
- Modo
- Mediana
- Significar:
Es la suma de la observación dividida por el número total de observaciones. También se define como promedio, que es la suma dividida por la cuenta.
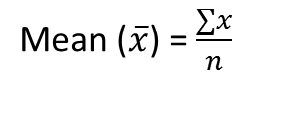
donde, n = número de términos
Código de Python para encontrar la media en pythonimportnumpy as np# Sample Dataarr=[5,6,11]# Meanmean=np.mean(arr)print("Mean = ", mean)Producción :
Mean = 7.333333333333333
- Moda:
Es el valor que tiene la frecuencia más alta en el conjunto de datos dado. El conjunto de datos puede no tener moda si la frecuencia de todos los puntos de datos es la misma. Además, podemos tener más de un modo si encontramos dos o más puntos de datos que tienen la misma frecuencia.Código para encontrar el modo en python
fromscipyimportstats# sample Dataarr=[1,2,2,3]# Modemode=stats.mode(arr)print("Mode = ", mode)Producción:
Mode = ModeResult(mode=array([2]), count=array([2]))
- Mediana:
Es el valor medio del conjunto de datos. Divide los datos en dos mitades. Si el número de elementos en el conjunto de datos es impar, entonces el elemento central es la mediana y si es par, la mediana sería el promedio de dos elementos centrales.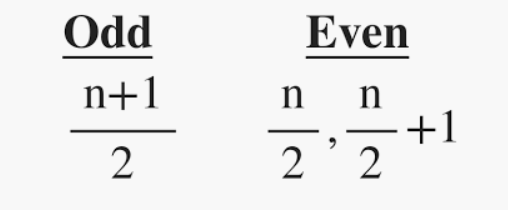
donde, n=número de términos del
código Python para encontrar la medianaimportnumpy as np# sample Dataarr=[1,2,3,4]# Medianmedian=np.median(arr)print("Median = ", median)Producción:
Median = 2.5
Medida de variabilidad:
la medida de variabilidad se conoce como la dispersión de datos o qué tan bien se distribuyen nuestros datos. Las medidas de variabilidad más comunes son:
- Rango
- Diferencia
- Desviación Estándar

- Rango:
El rango describe la diferencia entre el punto de datos más grande y más pequeño en nuestro conjunto de datos. Cuanto mayor sea el rango, mayor será la difusión de los datos y viceversa.
Rango = valor de datos más grande – valor de datos más pequeño
Código de Python para encontrar el rango
importnumpy as np# Sample Dataarr=[1,2,3,4,5]#Finding MaxMaximum=max(arr)# Finding MinMinimum=min(arr)# Difference Of Max and MinRange=Maximum-Minimumprint("Maximum = {}, Minimum = {} and Range = {}".format(Maximum, Minimum,Range))Producción:
Maximum = 5, Minimum = 1 and Range = 4
- Varianza:
Se define como la desviación media al cuadrado de la media. Se calcula encontrando la diferencia entre cada punto de datos y el promedio, que también se conoce como la media, elevándolos al cuadrado, sumándolos todos y luego dividiendo por la cantidad de puntos de datos presentes en nuestro conjunto de datos.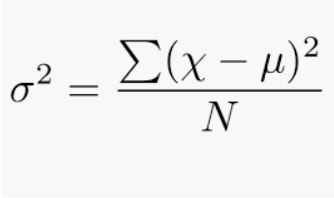
donde N = número de términos
u =
código medio de Python para encontrar la varianzaimportstatistics# sample dataarr=[1,2,3,4,5]# varianceprint("Var = ", (statistics.variance(arr)))Producción:
Var = 2.5
- Desviación Estándar:
Se define como la raíz cuadrada de la varianza. Se calcula encontrando la media, luego restando cada número de la media, que también se conoce como promedio, y elevando al cuadrado el resultado. Sumando todos los valores y luego dividiendo por el número de términos seguido de la raíz cuadrada.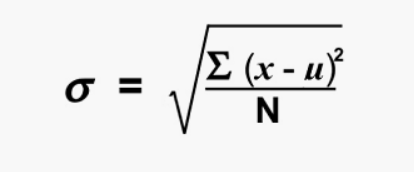
donde N = número de términos
u =
código medio de Python para realizar la desviación estándar:importstatistics# sample dataarr=[1,2,3,4,5]# Standard Deviationprint("Std = ", (statistics.stdev(arr)))Producción:
Std = 1.5811388300841898
Referencias: Fórmulas
de Wikipedia de Big Data
Publicación traducida automáticamente
Artículo escrito por niharikasurange9 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA