Pandas es una biblioteca de código abierto que se utiliza para trabajar con datos relacionales o etiquetados de manera fácil e intuitiva. Proporciona varias estructuras de datos y operaciones para manipular datos numéricos y series de tiempo. Ofrece una herramienta para limpiar y procesar sus datos. Es la biblioteca de Python más popular que se utiliza para el análisis de datos. En este artículo, vamos a aprender sobre la estructura de datos de Pandas.
Soporta dos estructuras de datos:
Serie
Pandas es una array etiquetada unidimensional y capaz de contener datos de cualquier tipo (enteros, strings, flotantes, objetos python, etc.)
Sintaxis: pandas.Series( datos=Ninguno , índice=Ninguno , dtype=Ninguno , nombre=Ninguno , copy=False , fastpath=False)
Parámetros:
- data : array- Contiene datos almacenados en Series.
- índice : similar a una array o Índice (1d)
- dtype : str, numpy.dtype o ExtensionDtype, opcional
- nombre : str, opcional
- copiar : bool, por defecto Falso
Ejemplo 1: serie que contiene el tipo de datos char.
Python3
import pandas as pd # a simple char list list = ['g', 'e', 'e', 'k', 's'] # create series form a char list res = pd.Series(list) print(res)
Producción:

Ejemplo 2: Serie que contiene el tipo de datos Int.
Python3
import pandas as pd # a simple int list list = [1,2,3,4,5] # create series form a int list res = pd.Series(list) print(res)
Producción:

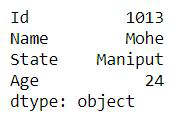
Ejemplo 3: Serie sosteniendo el diccionario.
Python3
import pandas as pd
dic = { 'Id': 1013, 'Name': 'MOhe',
'State': 'Maniput','Age': 24}
res = pd.Series(dic)
print(res)
Producción:
Marco de datos
Pandas DataFrame es una estructura de datos tabulares potencialmente heterogénea, de tamaño mutable, bidimensional con ejes etiquetados (filas y columnas). Un marco de datos es una estructura de datos bidimensional, es decir, los datos se alinean de forma tabular en filas y columnas como una hoja de cálculo o una tabla SQL, o un dictado de objetos de serie. . Pandas DataFrame consta de tres componentes principales, los datos , las filas y las columnas .
Creación de un marco de datos de pandas
En el mundo real, se creará un marco de datos de Pandas cargando los conjuntos de datos del almacenamiento existente, el almacenamiento puede ser una base de datos SQL, un archivo CSV y un archivo de Excel. Pandas DataFrame se puede crear a partir de las listas, el diccionario y una lista de diccionarios, etc. El marco de datos se puede crear de diferentes maneras. Aquí hay algunas formas en que creamos un marco de datos:
Ejemplo 1: DataFrame se puede crear usando una sola lista o una lista de listas.
Python3
# import pandas as pd import pandas as pd # list of strings lst = ['Geeks', 'For', 'Geeks', 'is', 'portal', 'for', 'Geeks'] # Calling DataFrame constructor on list df = pd.DataFrame(lst) display(df)
Producción:

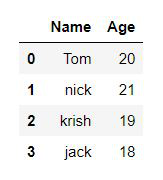
Ejemplo 2: Creación de DataFrame a partir de dict of ndarray/lists.
Para crear DataFrame a partir del dictado de narray/list, todo el narray debe tener la misma longitud. Si se pasa el índice, el índice de longitud debe ser igual a la longitud de las arrays. Si no se pasa ningún índice, de forma predeterminada, el índice será rango (n), donde n es la longitud de la array.
Python3
# Python code demonstrate creating
# DataFrame from dict narray / lists
# By default addresses.
import pandas as pd
# initialise data of lists.
data = {'Name':['Tom', 'nick', 'krish', 'jack'],
'Age':[20, 21, 19, 18]}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
display(df)
Producción:
Tratar con una columna y una fila en DataFrame
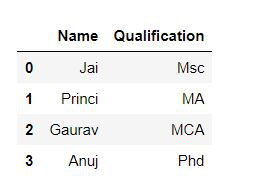
Selección de columna: para seleccionar una columna en Pandas DataFrame, podemos acceder a las columnas llamándolas por su nombre de columna.
Python3
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# select two columns
print(df[['Name', 'Qualification']])
Producción:
¿Cómo seleccionar filas y columnas de Pandas DataFrame?
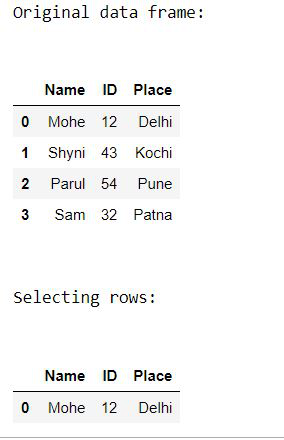
Ejemplo 1: Selección de filas.
pandas.DataFrame.loc es una función que se utiliza para seleccionar filas de Pandas DataFrame según la condición proporcionada.
Sintaxis: df.loc[df[‘cname’] ‘condición’]
Parámetros:
- df: representa el marco de datos
- cname: representa el nombre de la columna
- condición: representa la condición en la que se deben seleccionar las filas
Python3
# Importing pandas as pd
from pandas import DataFrame
# Creating a data frame
Data = {'Name': ['Mohe', 'Shyni', 'Parul', 'Sam'],
'ID': [12, 43, 54, 32],
'Place': ['Delhi', 'Kochi', 'Pune', 'Patna']
}
df = DataFrame(Data, columns = ['Name', 'ID', 'Place'])
# Print original data frame
print("Original data frame:\n")
display(df)
# Selecting the product of Electronic Type
select_prod = df.loc[df['Name'] == 'Mohe']
print("\n")
# Print selected rows based on the condition
print("Selecting rows:\n")
display (select_prod)
Producción:
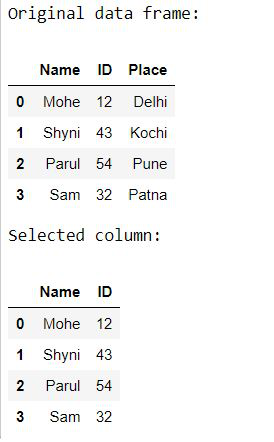
Ejemplo 2: Selección de columna.
Python3
# Importing pandas as pd
from pandas import DataFrame
# Creating a data frame
Data = {'Name': ['Mohe', 'Shyni', 'Parul', 'Sam'],
'ID': [12, 43, 54, 32],
'Place': ['Delhi', 'Kochi', 'Pune', 'Patna']
}
df = DataFrame(Data, columns = ['Name', 'ID', 'Place'])
# Print original data frame
print("Original data frame:")
display(df)
print("Selected column: ")
display(df[['Name', 'ID']] )
Producción:
Publicación traducida automáticamente
Artículo escrito por kumar_satyam y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA