Como sabemos, el documento XML se utiliza para almacenar y transportar datos. Entonces, para acceder a los datos de XML, necesitamos algo que pueda acceder a cada Node y a los datos de los atributos respectivos. Entonces la solución es XPath. XPath se puede utilizar para recorrer documentos XML, seleccionar Nodes/elementos y datos de atributos. Es una recomendación del W3C y una forma flexible de acceder a diferentes partes de un documento XML. Escribir XPath es similar a escribir una expresión de ruta en su sistema informático para atravesar una ubicación específica como (C:/School/Homework/assignment.docx).
Considere el siguiente documento XML
XML
<?xml version="1.0" encoding="UTF-8"?> <students> <student branch="CSE"> <name>Divyank Singh Sikarwar</name> <age>18</age> <city>Agra</city> </student> <student branch="CSE"> <name>Aniket Chauhan</name> <age>20</age> <city>Shahjahanpur</city> </student> <student branch="CSE"> <name>Simran Agarwal</name> <age>23</age> <city>Buland Shar</city> </student> <student branch="CSE"> <name>Abhay Chauhan</name> <age>17</age> <city>Shahjahanpur</city> </student> <student branch="IT"> <name>Himanshu Bhatia</name> <age>25</age> <city>Indore</city> </student> <student branch="IT"> <name>Anuj Modi</name> <age>22</age> <city>Ahemdabad</city> </student> <student branch="ECE"> <name>Manoj Yadav</name> <age>23</age> <city>Kota</city> </student> </students>
Símbolos XPath que se utilizan para acceder a diferentes partes de un documento XML:
|
Símbolo |
Descripción |
Ejemplo |
Resultado |
|---|---|---|---|
| nombre | Selecciona todas las etiquetas de XML que tienen el nombre ‘nombre’ | /estudiantes/estudiante/nombre | Muestra todos los nombres |
| / | Esto representa la raíz del documento. | /estudiantes/estudiante/ciudad | Mostrar la ciudad de cada estudiante |
| // | Selecciona el Node independientemente de dónde se encuentre. | //años | Selecciona y muestra todas las edades. |
| @ | Para acceder al valor del atributo de las etiquetas XML | /estudiantes/estudiante/@sucursal | Mostrar la rama de cada alumno |
| [ ] | Se utiliza para seleccionar Nodes específicos. | /estudiantes/estudiante[2]/nombre | Expositores Aniket Chauhan |
Practiquemos XPath
Considere el documento XML mencionado anteriormente:
Seleccionar segundo estudiante
/estudiantes/estudiante[2]/nombre
Seleccione todos los estudiantes con rama TI
/estudiantes/estudiante[@branch = /”IT/”]/nombre
Seleccionar todos los alumnos cuya edad sea menor que igual a 20
/estudiantes/estudiante[edad <= 20]/nombre
Primeros 4 estudiantes
/estudiantes/estudiante[posición() <= 4]/nombre
Código Java para evaluar la expresión XPath
Java
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
public class XPathDemo {
public static void main(String[] args) throws Exception
{
File xmlFile = new File("student.xml");
// Get DOM
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document xml = db.parse(xmlFile);
xml.getDocumentElement().normalize();
// Get XPath
XPathFactory xpf = XPathFactory.newInstance();
XPath xpath = xpf.newXPath();
// Find 2nd Student's name
String name = (String)xpath.evaluate(
"/students/student[2]/name", xml,
XPathConstants.STRING);
System.out.println("2nd Student Name: " + name);
// find specific students name whose branch is IT
NodeList nodes = (NodeList)xpath.evaluate(
"/students/student[@branch = \"IT\"]/name", xml,
XPathConstants.NODESET);
System.out.println("\nStudents with branch IT:");
printNodes(nodes);
// find specific students
// name whose age is less
// than equal to 20
nodes = (NodeList)xpath.evaluate(
"/students/student[age <= 20]/name", xml,
XPathConstants.NODESET);
System.out.println(
"\nStudents of age less than equal to 20:");
printNodes(nodes);
// First 4 students from XML document
nodes = (NodeList)xpath.evaluate(
"/students/student[position() < 5]/name", xml,
XPathConstants.NODESET);
System.out.println("\nFirst Four Students: ");
printNodes(nodes);
}
// prints nodes
public static void printNodes(NodeList nodes)
{
for (int i = 0; i < nodes.getLength(); i++) {
System.out.println(
(i + 1) + ". "
+ nodes.item(i).getTextContent());
}
}
}
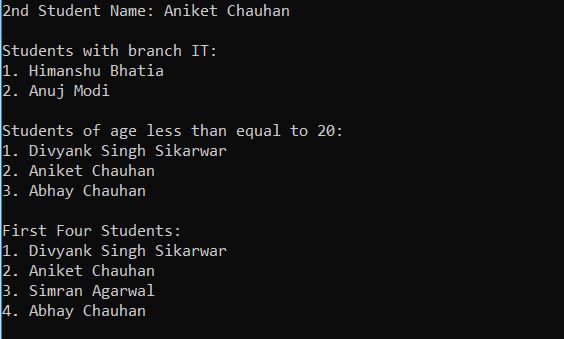
Producción:
Explicación de clases y métodos utilizados en el código anterior:
- La clase javax.xml.Parsers.DocumentBuilder define la API para obtener instancias DOM de un documento XML.
- El método parse() analiza el contenido del archivo dado como un documento XML y devuelve un nuevo objeto DOM.
- El método normalize() normaliza el contenido del archivo dado como un documento XML.
- La instancia de la clase javax.xml.xpath.XPathFactory se puede usar para crear objetos XPath que contienen el método de evaluación() para evaluar nuestro xpath escrito y devolver string/Node/Conjunto de Nodes, cualquiera, de acuerdo con el parámetro pasado (consulte el método de evaluación() dentro código).
- position() es una función XPath que devuelve la posición de la etiqueta especificada actualmente. (En el código anterior, la etiqueta especificada es ‘estudiante’). Del mismo modo, XPath proporciona una lista de funciones útiles, puede explorarla.
Publicación traducida automáticamente
Artículo escrito por prakhargupta24 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA