El preprocesamiento de datos es una parte importante de la canalización de la ciencia de datos, debe conocer varias irregularidades en los datos, manipular sus funciones, etc. Pandas es una herramienta que usamos con mucha frecuencia para manipular los datos, junto con seaborn y matplotlib para visualización de datos. PandasGUI es una biblioteca que facilita mucho esta tarea al proporcionar una interfaz GUI que se puede usar para hacer
Instalación de PandasGUI
Puede instalar PandasGUI como cualquier otra biblioteca de python usando el comando pip. El comando para el mismo es: –
pip install pandasgui
Abriendo un CSV en PandasGUI
Para abrir un archivo CSV en PandasGUI necesitamos usar la función show() . Comencemos por importarlo junto con pandas. Haga clic aquí para obtener el conjunto de datos .
Python3
from pandasgui import show import pandas as pd
Lo siguiente que hacemos es cargar nuestro CSV como DataFrame usando read_csv() y pasar ese dataframe a show() como argumento.
Python3
df = pd.read_csv('data.csv')
show(df)
Producción:
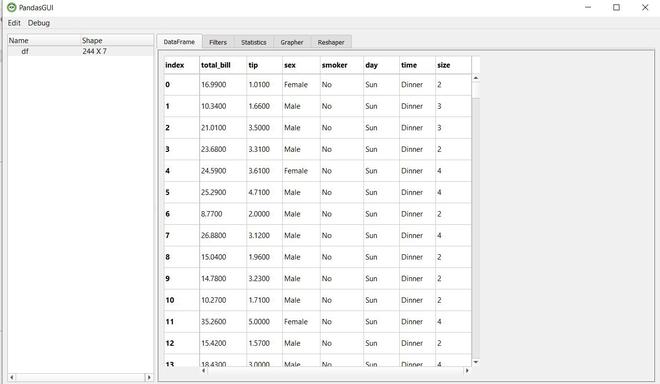
Este es nuestro marco de datos y podemos desplazarnos y obtener una descripción general de los datos. Puede ver celdas vacías que representan valores de NaN. Puede editar los datos haciendo clic en una celda y editando su valor. Puede ordenar el marco de datos en función de una columna en particular simplemente haciendo clic en la columna. En la imagen a continuación, podemos ordenar el marco de datos según la columna Total_bill haciendo clic en él.
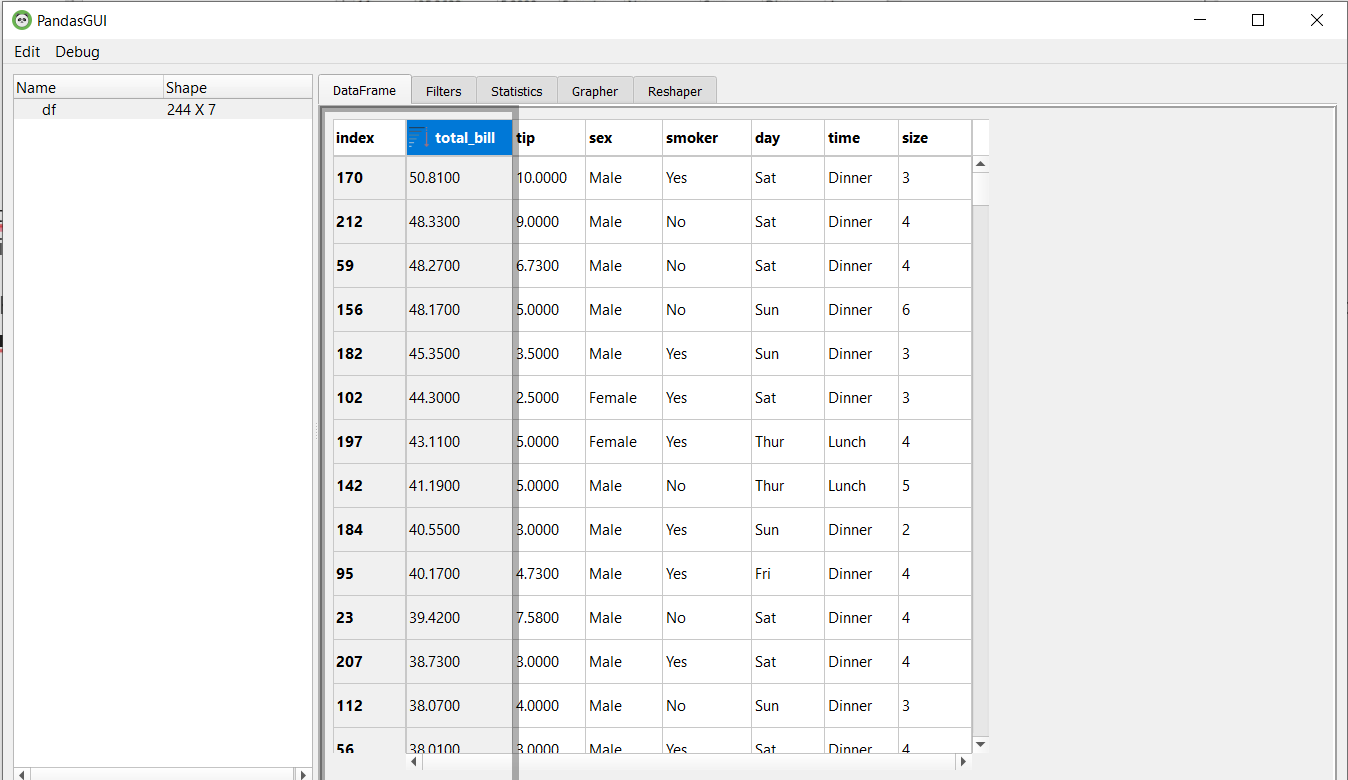
Filtros en PandasGUI
Supongamos que queremos ver las filas donde el valor de MSSubClass es mayor o igual a 120. En pandas, podemos hacerlo usando el siguiente comando:
Python3
df[df['total_bill'] >= 40]
Producción:
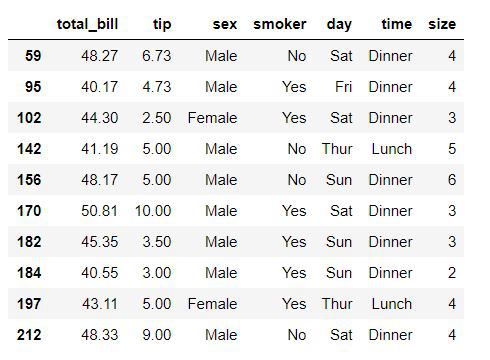
PandasGUI nos proporciona filtros donde puede escribir expresiones de consulta para filtrar los datos. La expresión de consulta para lo anterior será:
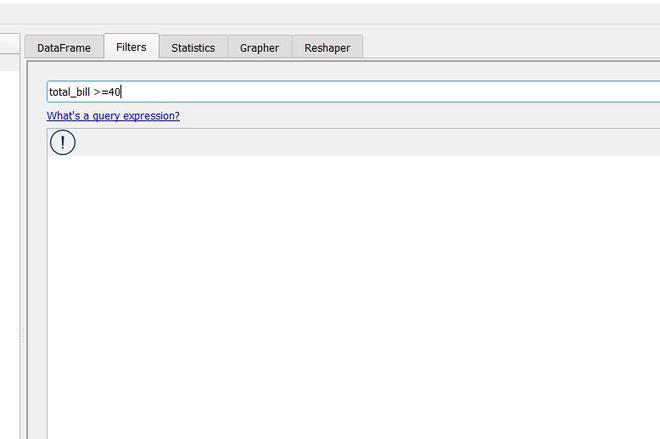
Puede escribir esta expresión de consulta en Filtros y hacer clic en Agregar filtro para aplicarla. Echemos un vistazo a los datos en la imagen de abajo. Como puede ver, los filtros se aplicaron correctamente.
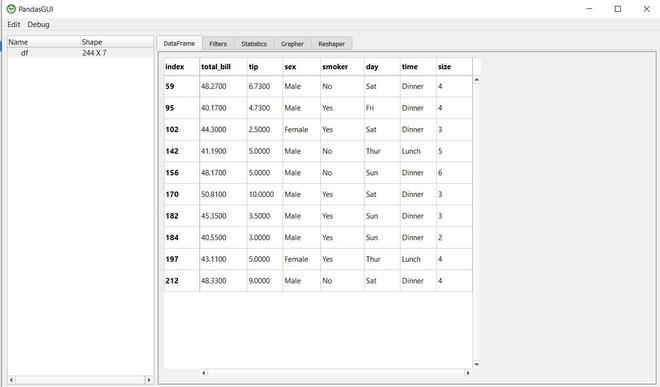
Estadísticas en Pandas GUI
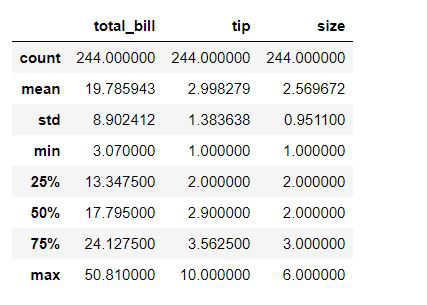
Las estadísticas de resumen le brindan una descripción general de la distribución de datos. En pandas, usamos el método describe() para obtener las estadísticas de los datos.
Python3
df.describe()
Producción:
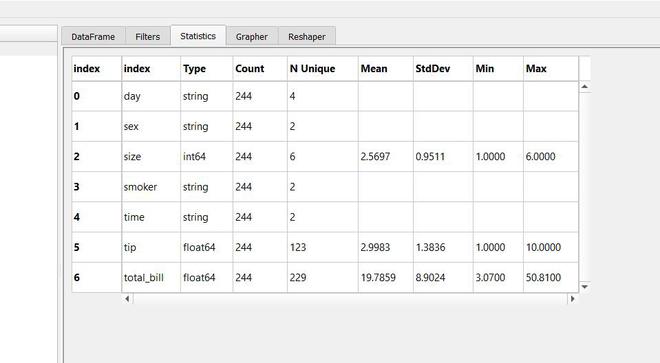
En PandasGUI, puede ir a la sección Estadísticas y obtener las estadísticas de cada columna.
Visualización de datos en PandasGUI
La visualización de datos no es algo para lo que normalmente se usan los pandas, usamos bibliotecas como matplotlib, seaborn, plotly, etc. Pero PandasGUI ofrece gráficos interactivos trazados usando plotly en la sección Grapher.
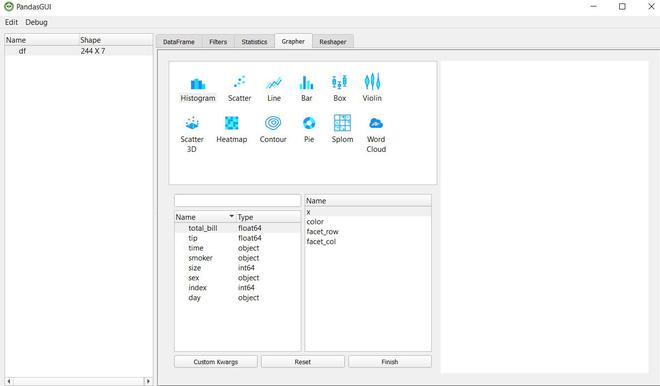
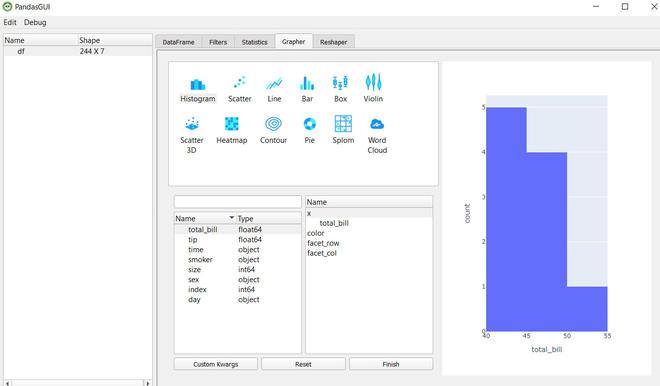
Puede trazar varios tipos de gráficos, vamos a crear un histograma de total_bill arrastrándolo y soltándolo debajo de x .
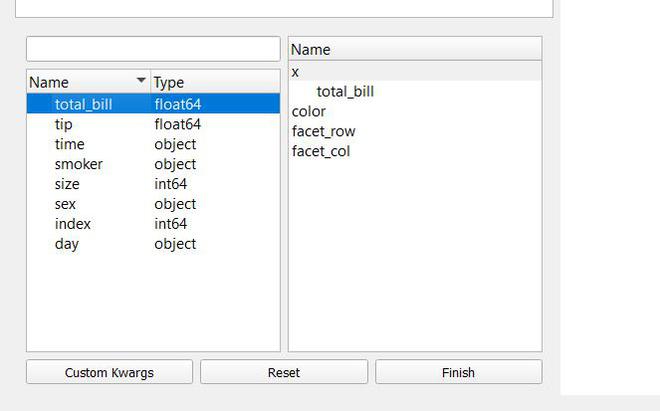
Después de eso, simplemente haga clic en Finalizar y podrá ver su gráfico.
Hagamos un gráfico de barras.
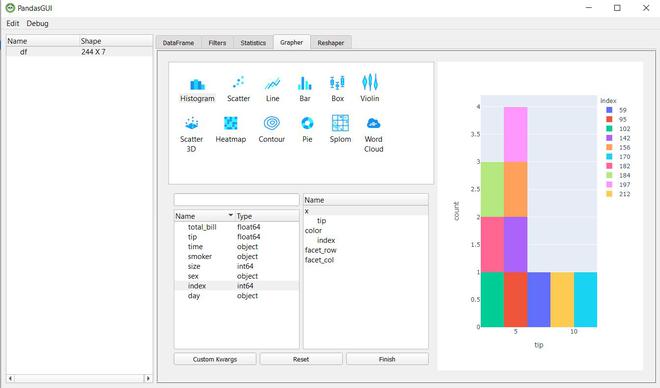
Junto con estos, puede crear un diagrama de caja, un diagrama de dispersión en 3D, un diagrama de líneas, etc. PandasGUI es una gran herramienta si desea obtener una descripción general rápida de sus datos, desde verificar estadísticas de resumen hasta graficar datos, puede hacerlo fácilmente sin la necesidad de código.
Publicación traducida automáticamente
Artículo escrito por herumbshandilya y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA