Cada vez que trabajamos en ciencia de datos y aprendizaje automático, nuestro enfoque de manejar los datos y encontrar algo útil se basa en la distribución de los datos.
Distribución significa cómo los datos pueden estar presentes en diferentes formas posibles, el porcentaje de datos específicos, identificando los valores atípicos. Entonces, la distribución de datos es la forma de usar métodos gráficos para organizar y mostrar información útil.
Términos relacionados con la Exploración de la Distribución de Datos
-> Boxplot -> Frequency Table -> Histogram -> Density Plot
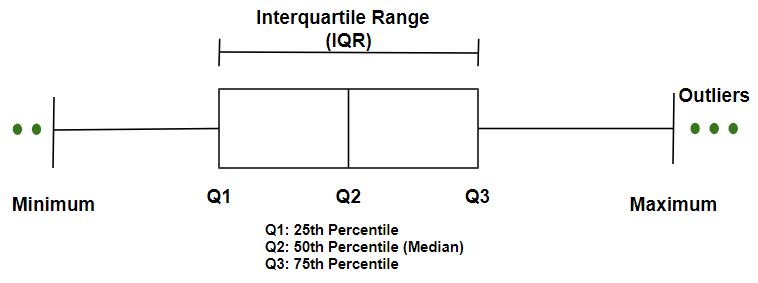
- Diagrama de caja: se basa en los percentiles de los datos como se muestra en la figura a continuación. La parte superior e inferior de la gráfica de caja son los percentiles 75 y 25 de los datos. Las líneas extendidas se conocen como bigotes que incluyen el rango del resto de los datos.
Para obtener el enlace al
csvarchivo utilizado, haga clic aquí .Código #1: Cargando Bibliotecas
importnumpy as npimportpandas as pdimportseaborn as snsimportmatplotlib.pyplot as pltCódigo #2: Cargando Datos
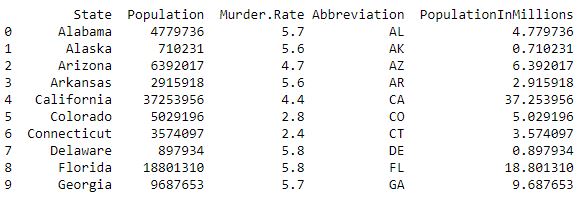
data=pd.read_csv("../data/state.csv")# Adding a new column with derived datadata['PopulationInMillions']=data['Population']/1000000print(data.head(10))Producción :
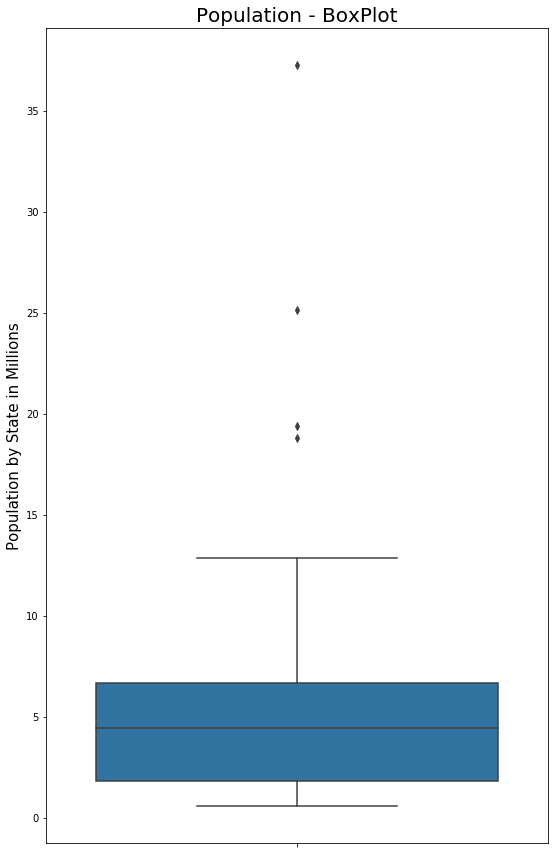
Código #3: diagrama de caja
# BoxPlot Population In Millionsfig, ax1=plt.subplots()fig.set_size_inches(9,15)ax1=sns.boxplot(x=data.PopulationInMillions, orient="v")ax1.set_ylabel("Population by State in Millions", fontsize=15)ax1.set_title("Population - BoxPlot", fontsize=20)Producción :
- Tabla de frecuencia: es una herramienta para distribuir los datos en rangos, segmentos igualmente espaciados y nos dice cuántos valores caen en cada segmento.
Código n.° 1: agregar una columna para realizar la función de tabulación cruzada y agrupación.
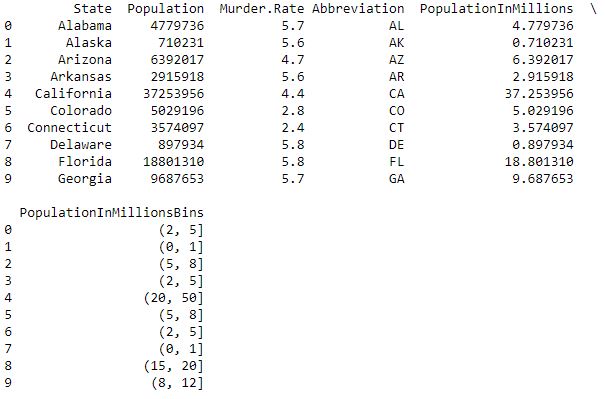
# Perform the binning action, the bins have been# chosen to accentuate the output for the Frequency Tabledata['PopulationInMillionsBins']=pd.cut(data.PopulationInMillions, bins=[0,1,2,5,8,12,15,20,50])print(data.head(10))Producción :
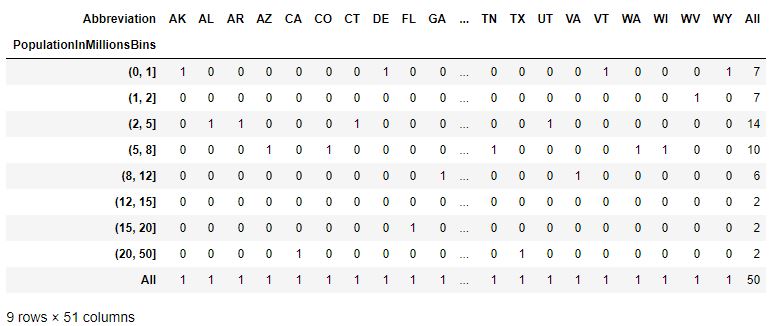
Código n.º 2: tabulación cruzada: un tipo de tabla de frecuencias
# Cross Tab - a type of Frequency Tablepd.crosstab(data.PopulationInMillionsBins, data.Abbreviation, margins=True)Producción :
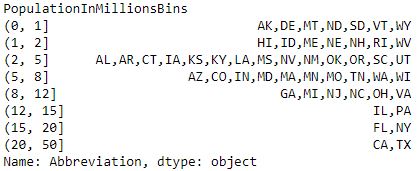
Código n.º 3: GroupBy: un tipo de tabla de frecuencias
# Groupby - a type of Frequency Tabledata.groupby(data.PopulationInMillionsBins)['Abbreviation'].apply(', '.join)Producción :
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA