Requisitos previos: LCE (Conjunto 1) , LCE (Conjunto 2) , Array de sufijos (n Log Log n) , algoritmo de Kasai y árbol de segmentos
El problema de la extensión común más larga (LCE) considera una string s y calcula, para cada par (L , R), la substring más larga de s que comienza tanto en L como en R. En LCE, en cada una de las consultas que tenemos que responder la longitud del prefijo común más largo que comienza en los índices L y R.
Ejemplo:
String : “abbababba”
Consultas: LCE(1, 2), LCE(1, 6) y LCE(0, 5)
Encuentre la longitud del prefijo común más largo que comienza en el índice dado como (1, 2), (1, 6) y (0, 5) .
La string resaltada es el prefijo común más largo que comienza en el índice L y R de las consultas respectivas. Tenemos que encontrar la longitud del prefijo común más largo que comienza en index- (1, 2), (1, 6) y (0, 5) .

En este conjunto, discutiremos sobre el enfoque del árbol de segmentos para resolver el problema LCE.
En el Conjunto 2 , vimos que un problema LCE se puede convertir en un problema RMQ.
Para procesar la RMQ de manera eficiente, construimos un árbol de segmentos en la array lcp y luego respondemos de manera eficiente las consultas de LCE.
Para encontrar bajo y alto, primero debemos calcular la array de sufijos y luego, a partir de la array de sufijos, calculamos la array de sufijos inversa.
También necesitamos la array lcp, por lo que usamos el algoritmo de Kasai para encontrar la array lcp a partir de la array de sufijos .
Una vez que se hacen las cosas anteriores, simplemente encontramos el valor mínimo en la array lcp desde el índice de menor a mayor (como se demostró anteriormente) para cada consulta.
Sin probar usaremos el resultado directo (deducido después de pruebas matemáticas)-
LCE (L, R) = RMQ lcp (invSuff[R], invSuff[L]-1)
El subíndice lcp significa que tenemos que realizar RMQ en la array lcp y, por lo tanto, construiremos un árbol de segmentos en la array lcp.
// A C++ Program to find the length of longest common
// extension using Segment Tree
#include<bits/stdc++.h>
using namespace std;
// Structure to represent a query of form (L,R)
struct Query
{
int L, R;
};
// Structure to store information of a suffix
struct suffix
{
int index; // To store original index
int rank[2]; // To store ranks and next rank pair
};
// A utility function to get minimum of two numbers
int minVal(int x, int y)
{
return (x < y)? x: y;
}
// A utility function to get the middle index from
// corner indexes.
int getMid(int s, int e)
{
return s + (e -s)/2;
}
/* A recursive function to get the minimum value
in a given range of array indexes. The following
are parameters for this function.
st --> Pointer to segment tree
index --> Index of current node in the segment
tree. Initially 0 is passed as root
is always at index 0
ss & se --> Starting and ending indexes of the
segment represented by current
node, i.e., st[index]
qs & qe --> Starting and ending indexes of query
range */
int RMQUtil(int *st, int ss, int se, int qs, int qe,
int index)
{
// If segment of this node is a part of given range,
// then return the min of the segment
if (qs <= ss && qe >= se)
return st[index];
// If segment of this node is outside the given range
if (se < qs || ss > qe)
return INT_MAX;
// If a part of this segment overlaps with the given
// range
int mid = getMid(ss, se);
return minVal(RMQUtil(st, ss, mid, qs, qe, 2*index+1),
RMQUtil(st, mid+1, se, qs, qe, 2*index+2));
}
// Return minimum of elements in range from index qs
// (query start) to qe (query end). It mainly uses RMQUtil()
int RMQ(int *st, int n, int qs, int qe)
{
// Check for erroneous input values
if (qs < 0 || qe > n-1 || qs > qe)
{
printf("Invalid Input");
return -1;
}
return RMQUtil(st, 0, n-1, qs, qe, 0);
}
// A recursive function that constructs Segment Tree
// for array[ss..se]. si is index of current node in
// segment tree st
int constructSTUtil(int arr[], int ss, int se, int *st,
int si)
{
// If there is one element in array, store it in
// current node of segment tree and return
if (ss == se)
{
st[si] = arr[ss];
return arr[ss];
}
// If there are more than one elements, then recur
// for left and right subtrees and store the minimum
// of two values in this node
int mid = getMid(ss, se);
st[si] = minVal(constructSTUtil(arr, ss, mid, st, si*2+1),
constructSTUtil(arr, mid+1, se, st, si*2+2));
return st[si];
}
/* Function to construct segment tree from given array.
This function allocates memory for segment tree and
calls constructSTUtil() to fill the allocated memory */
int *constructST(int arr[], int n)
{
// Allocate memory for segment tree
//Height of segment tree
int x = (int)(ceil(log2(n)));
// Maximum size of segment tree
int max_size = 2*(int)pow(2, x) - 1;
int *st = new int[max_size];
// Fill the allocated memory st
constructSTUtil(arr, 0, n-1, st, 0);
// Return the constructed segment tree
return st;
}
// A comparison function used by sort() to compare
// two suffixes Compares two pairs, returns 1 if
// first pair is smaller
int cmp(struct suffix a, struct suffix b)
{
return (a.rank[0] == b.rank[0])?
(a.rank[1] < b.rank[1] ?1: 0):
(a.rank[0] < b.rank[0] ?1: 0);
}
// This is the main function that takes a string
// 'txt' of size n as an argument, builds and return
// the suffix array for the given string
vector<int> buildSuffixArray(string txt, int n)
{
// A structure to store suffixes and their indexes
struct suffix suffixes[n];
// Store suffixes and their indexes in an array
// of structures. The structure is needed to sort
// the suffixes alphabetically and maintain their
// old indexes while sorting
for (int i = 0; i < n; i++)
{
suffixes[i].index = i;
suffixes[i].rank[0] = txt[i] - 'a';
suffixes[i].rank[1] = ((i+1) < n)?
(txt[i + 1] - 'a'): -1;
}
// Sort the suffixes using the comparison function
// defined above.
sort(suffixes, suffixes+n, cmp);
// At his point, all suffixes are sorted according to first
// 2 characters. Let us sort suffixes according to first 4
// characters, then first 8 and so on
int ind[n]; // This array is needed to get the index
// in suffixes[]
// from original index. This mapping is needed to get
// next suffix.
for (int k = 4; k < 2*n; k = k*2)
{
// Assigning rank and index values to first suffix
int rank = 0;
int prev_rank = suffixes[0].rank[0];
suffixes[0].rank[0] = rank;
ind[suffixes[0].index] = 0;
// Assigning rank to suffixes
for (int i = 1; i < n; i++)
{
// If first rank and next ranks are same as
// that of previous suffix in array, assign
// the same new rank to this suffix
if (suffixes[i].rank[0] == prev_rank &&
suffixes[i].rank[1] == suffixes[i-1].rank[1])
{
prev_rank = suffixes[i].rank[0];
suffixes[i].rank[0] = rank;
}
else // Otherwise increment rank and assign
{
prev_rank = suffixes[i].rank[0];
suffixes[i].rank[0] = ++rank;
}
ind[suffixes[i].index] = i;
}
// Assign next rank to every suffix
for (int i = 0; i < n; i++)
{
int nextindex = suffixes[i].index + k/2;
suffixes[i].rank[1] = (nextindex < n)?
suffixes[ind[nextindex]].rank[0]: -1;
}
// Sort the suffixes according to first k characters
sort(suffixes, suffixes+n, cmp);
}
// Store indexes of all sorted suffixes in the suffix array
vector<int>suffixArr;
for (int i = 0; i < n; i++)
suffixArr.push_back(suffixes[i].index);
// Return the suffix array
return suffixArr;
}
/* To construct and return LCP */
vector<int> kasai(string txt, vector<int> suffixArr,
vector<int> &invSuff)
{
int n = suffixArr.size();
// To store LCP array
vector<int> lcp(n, 0);
// Fill values in invSuff[]
for (int i=0; i < n; i++)
invSuff[suffixArr[i]] = i;
// Initialize length of previous LCP
int k = 0;
// Process all suffixes one by one starting from
// first suffix in txt[]
for (int i=0; i<n; i++)
{
/* If the current suffix is at n-1, then we don?t
have next substring to consider. So lcp is not
defined for this substring, we put zero. */
if (invSuff[i] == n-1)
{
k = 0;
continue;
}
/* j contains index of the next substring to
be considered to compare with the present
substring, i.e., next string in suffix array */
int j = suffixArr[invSuff[i]+1];
// Directly start matching from k'th index as
// at-least k-1 characters will match
while (i+k<n && j+k<n && txt[i+k]==txt[j+k])
k++;
lcp[invSuff[i]] = k; // lcp for the present suffix.
// Deleting the starting character from the string.
if (k>0)
k--;
}
// return the constructed lcp array
return lcp;
}
// A utility function to find longest common extension
// from index - L and index - R
int LCE(int *st, vector<int>lcp, vector<int>invSuff,
int n, int L, int R)
{
// Handle the corner case
if (L == R)
return (n-L);
// Use the formula -
// LCE (L, R) = RMQ lcp (invSuff[R], invSuff[L]-1)
return (RMQ(st, n, invSuff[R], invSuff[L]-1));
}
// A function to answer queries of longest common extension
void LCEQueries(string str, int n, Query q[],
int m)
{
// Build a suffix array
vector<int>suffixArr = buildSuffixArray(str, str.length());
// An auxiliary array to store inverse of suffix array
// elements. For example if suffixArr[0] is 5, the
// invSuff[5] would store 0. This is used to get next
// suffix string from suffix array.
vector<int> invSuff(n, 0);
// Build a lcp vector
vector<int>lcp = kasai(str, suffixArr, invSuff);
int lcpArr[n];
// Convert to lcp array
for (int i=0; i<n; i++)
lcpArr[i] = lcp[i];
// Build segment tree from lcp array
int *st = constructST(lcpArr, n);
for (int i=0; i<m; i++)
{
int L = q[i].L;
int R = q[i].R;
printf("LCE (%d, %d) = %d\n", L, R,
LCE(st, lcp, invSuff, n, L, R));
}
return;
}
// Driver Program to test above functions
int main()
{
string str = "abbababba";
int n = str.length();
// LCA Queries to answer
Query q[] = {{1, 2}, {1, 6}, {0, 5}};
int m = sizeof(q)/sizeof(q[0]);
LCEQueries(str, n, q, m);
return (0);
}
Producción:
LCE (1, 2) = 1 LCE (1, 6) = 3 LCE (0, 5) = 4
Complejidad de tiempo: para construir el lcp y la array de sufijos se necesita un tiempo de O(N.logN). Para responder a cada consulta se necesita O(log N). Por lo tanto, la complejidad temporal total es O(N.logN + Q.logN)). Aunque podemos construir la array lcp y la array de sufijos en tiempo O (N) usando otros algoritmos.
donde,
Q = Número de Consultas LCE.
N = Longitud de la string de entrada.
Espacio auxiliar:
Usamos el espacio auxiliar O(N) para almacenar lcp, sufijos y arrays de sufijos inversos y el árbol de segmentos.
Comparación de actuaciones: hemos visto tres algoritmos para calcular la longitud de la LCE.
Conjunto 1: método ingenuo [O(NQ)]
Conjunto 2: método mínimo directo de RMQ [O(N.logN + Q. (|invSuff[R] – invSuff[L]|))]
Conjunto 3: método de árbol de segmentos [ O(N.logN + Q.logN))]
invSuff[] = array de sufijos inversa de la string de entrada.
A partir de la complejidad del tiempo asintótico, parece que el método del árbol de segmentos es el más eficiente y los otros dos son muy ineficientes.
Pero cuando se trata del mundo práctico, este no es el caso. Si trazamos un gráfico entre el tiempo y el registro ((|invSuff[R] – invSuff[L]|) para archivos típicos que tienen strings aleatorias para varias ejecuciones, el resultado es el que se muestra a continuación.
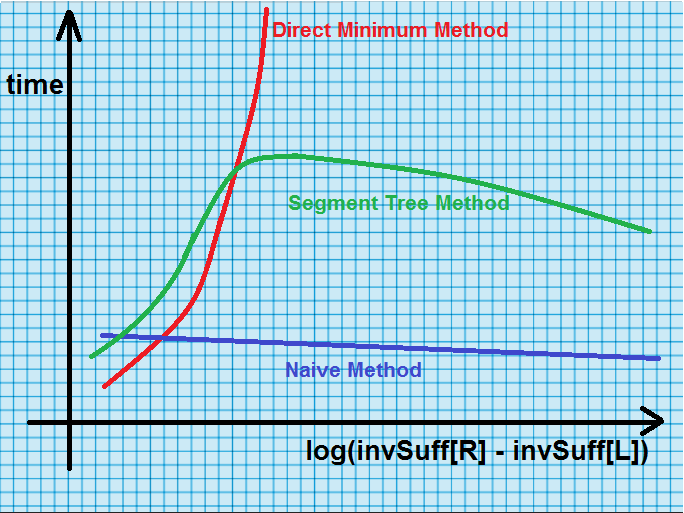
El gráfico anterior está tomado de esta referencia. Las pruebas se realizaron en 25 archivos que tenían strings aleatorias que oscilaban entre 0,7 MB y 2 GB. No se conocen los tamaños exactos de la string, pero obviamente un archivo de 2 GB tiene muchos caracteres. Esto se debe a que 1 carácter = 1 byte. Entonces, alrededor de 1000 caracteres equivalen a 1 kilobyte. Si una página tiene 2000 caracteres (un promedio razonable para una página a doble espacio), ocupará 2K (2 kilobytes). Eso significa que se necesitarán alrededor de 500 páginas de texto para igualar un megabyte. ¡Por lo tanto, 2 gigabytes = 2000 megabytes = 2000*500 = 10,00,000 páginas de texto!
A partir del gráfico anterior, está claro que el Método Naive (discutido en el Conjunto 1) funciona mejor (mejor que el Método del Árbol de Segmentos).
Esto es sorprendente ya que la complejidad temporal asintótica del método del árbol de segmentos es mucho menor que la del método ingenuo.
De hecho, el método ingenuo es generalmente de 5 a 6 veces más rápido que el método del árbol de segmentos en archivos típicos que tienen strings aleatorias. Tampoco hay que olvidar que el Método Naive es un algoritmo en el lugar, lo que lo convierte en el algoritmo más deseable para calcular LCE.
La conclusión es que el método ingenuo es la opción más óptima para responder a las consultas de LCE cuando se trata del rendimiento de casos promedio.
Este tipo de pensamientos rara vez sucede en Ciencias de la Computación cuando un algoritmo que parece más rápido es superado por uno menos eficiente en las pruebas prácticas.
Lo que aprendemos es que, aunque el análisis asintótico es una de las formas más efectivas de comparar dos algoritmos en papel, pero en los usos prácticos, a veces las cosas pueden suceder al revés.
Referencias:
http://www.sciencedirect.com/science/article/pii/S1570866710000377
Este artículo es una contribución de Rachit Belwariar . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA