Al trabajar con HTML, existen varios requisitos para extraer datos de etiquetas HTML sin formato de manera ordenada en forma de contenedores de datos de Python, como listas, dictados, números enteros, etc. Este artículo trata sobre una biblioteca que ayuda a lograr esto usando una regla. enfoque basado en
Características de Python – minero de texto:
- Extrae datos en forma de lista, diccionario y textos de HTML.
- Sistema basado en reglas usado en formato YAML.
- Admite la extracción de URL en forma de raspado.
Instalación:
Use el siguiente comando para instalar Python textminer:
pip install textminer
Descripción de las funciones:
Las siguientes funciones son útiles al extraer datos de HTML:
Sintaxis:
extract(html, rule)
Parámetros:
- html: El HTML del que extraer datos.
- rule: Regla en formato YAML para aplicar sobre HTML para extraer datos.
Sintaxis:
extract_from_url(url, rule)
Parámetros:
- rule: Regla en formato YAML para aplicar sobre HTML para extraer datos.
- url: la URL HTML desde la que se debe realizar la extracción de HTML.
Ejemplo 1: Extraer datos de HTML
Esta regla básica en formato YAML está formulada para extraer datos entre un sufijo y un prefijo.
Python3
import textminer
# input html
inp_html = '<html><body><div>GFG is best for Geeks</div></body></html>'
# yaml rule string
rule = '''
value:
prefix: <div>
suffix: </div>
'''
# using extract() to get required data
res = textminer.extract(inp_html, rule)
print("The data extracted between divs : ")
print(res)
Producción :
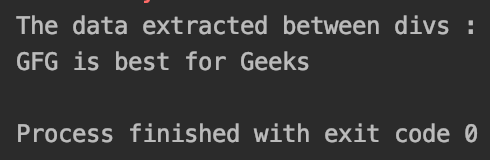
Datos extraídos entre divs
Ejemplo 2: Extraer una lista de HTML
La lista basada en python se puede extraer de Html, a la que comúnmente se hace referencia mediante etiquetas de lista, utilizando <li> y </li> como prefijo y sufijo de la regla. Además, se debe agregar la palabra clave «lista» para lograr esto.
Python3
import textminer
# input html
inp_html = """<html>
<body>
<ul>
<li>Gfg</li>
<li>is</li>
<li>best</li>
</ul>
</body>
</html>"""
# yaml rule string
# extracting list using <li>
# using "list" keyword
rule = '''
list:
prefix: <li>
suffix: </li>
'''
# using extract() to get required data
res = textminer.extract(inp_html, rule)
print("The data extracted between list tags : ")
print(res)
Producción :

Lista extraída
Ejemplo 3: Extraer diccionario de HTML utilizando tipos de datos definidos.
Similar al ejemplo anterior, se puede extraer un diccionario usando la palabra clave «dic», con la mención de «clave» requerida para asignar la clave, y el valor se extrae usando la definición de etiquetas de prefijo y sufijo con una identificación específica. El tipo de datos se puede mencionar usando la palabra clave «tipo».
Python3
import textminer
# input html
inp_html = """<html>
<body>
<div id="Gfg">Best</div>
<div id="4">Geeks</div>
</body>
</html>"""
# yaml rule string
# extracting dict. using dict
# using int to extract key in integer format
rule = '''
dict:
- key: gfg
prefix: <div id="Gfg">
suffix: </div>
- key: 4
prefix: <div id="4">
suffix: </div>
type: int
'''
# using extract() to get required data
res = textminer.extract(inp_html, rule)
print("The data extracted between dictionary tags : ")
print(res)
Producción :

Diccionario extraído
Ejemplo 4: extraer HTML de la URL
Además de dar HTML como una string, HTML también se puede proporcionar usando una URL usando extract_from_url() .
Python3
import textminer
# required url
target_url = "https://www.geeksforgeeks.org/"
# extracting title from url
rule = '''
value:
prefix: <title>
suffix: </title>
'''
# using extract() to get required data
res = textminer.extract_from_url(target_url, rule)
print("The data extracted between title tags from url : ")
print(res)
Producción :

Extracción de URL.
Publicación traducida automáticamente
Artículo escrito por manjeet_04 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA