En este artículo, veremos cómo raspar datos de trabajo de Indeed usando Python. Aquí usaremos Beautiful Soup y el módulo de solicitud para raspar los datos.
Módulo necesario
- bs4 : Beautiful Soup (bs4) es una biblioteca de Python para extraer datos de archivos HTML y XML. Este módulo no viene integrado con Python. Para instalar este tipo, escriba el siguiente comando en la terminal.
pip instalar bs4
- requests : Request le permite enviar requests HTTP/1.1 de manera extremadamente fácil. Este módulo tampoco viene integrado con Python. Para instalar este tipo, escriba el siguiente comando en la terminal.
requests de instalación de pip
Acercarse:
- Importe todos los módulos necesarios.
- Pase la URL en la función getdata() (función definida por el usuario) para que solicite una URL, devuelve una respuesta. Estamos usando el método get para recuperar información del servidor dado usando una URL dada.
Sintaxis:
requests.get(url, argumentos)
- Convierta esos datos en código HTML.
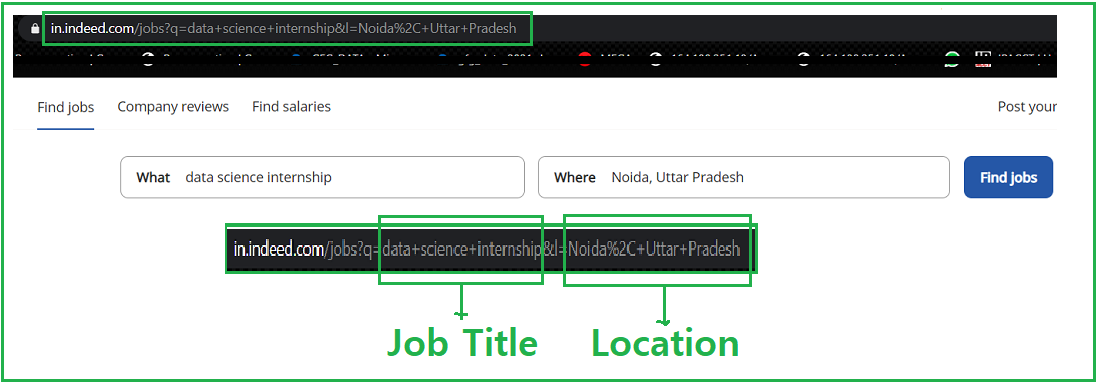
En la imagen dada, vemos el enlace, donde buscamos el trabajo y su ubicación, luego la URL se convierte en algo como esto https://in.indeed.com/jobs?q=”+job+”&l=”+Location, por lo tanto, formateará nuestra string en este formato.
- Ahora analice el contenido HTML usando bs4.
Sintaxis: sopa = BeautifulSoup(r.content, ‘html5lib’)
Parámetros:
- r.content : es el contenido HTML sin procesar.
- html.parser : especificando el analizador HTML que queremos usar.
- Ahora filtre los datos requeridos usando la función de sopa.Find_all.
- Ahora busque la lista con una etiqueta donde class_ = jobtitle turntileLink. Puede abrir la página web en el navegador e inspeccionar el elemento relevante haciendo clic con el botón derecho, como se muestra en la figura.
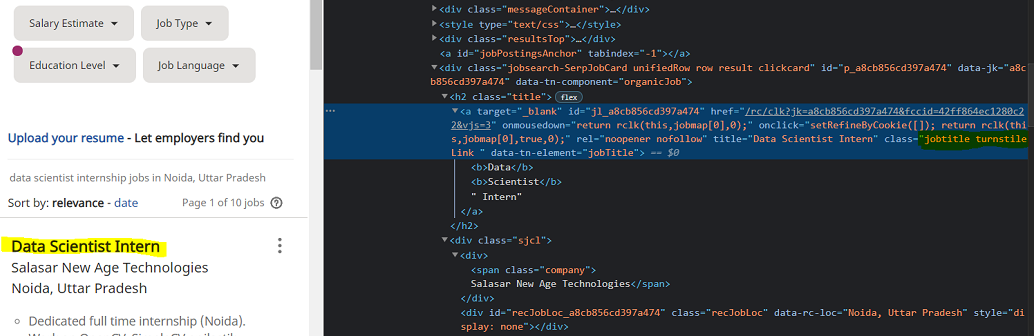
- Encuentre el nombre y la dirección de la empresa con los mismos métodos que los anteriores.
Funciones utilizadas:
El código para esta implementación se divide en funciones definidas por el usuario para aumentar la legibilidad del código y agregar facilidad de uso.
- geturl(): obtiene la URL de la que se van a extraer los datos
- html_code(): obtiene el código HTML de la URL proporcionada
- job_data(): filtra los datos del trabajo
- Company_data(): filtrar los datos de la empresa
Programa:
Python3
# import module
import requests
from bs4 import BeautifulSoup
# user define function
# Scrape the data
# and get in string
def getdata(url):
r = requests.get(url)
return r.text
# Get Html code using parse
def html_code(url):
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# return html code
return(soup)
# filter job data using
# find_all function
def job_data(soup):
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("a", class_="jobtitle turnstileLink"):
data_str = data_str + item.get_text()
result_1 = data_str.split("\n")
return(result_1)
# filter company_data using
# find_all function
def company_data(soup):
# find the Html tag
# with find()
# and convert into string
data_str = ""
result = ""
for item in soup.find_all("div", class_="sjcl"):
data_str = data_str + item.get_text()
result_1 = data_str.split("\n")
res = []
for i in range(1, len(result_1)):
if len(result_1[i]) > 1:
res.append(result_1[i])
return(res)
# driver nodes/main function
if __name__ == "__main__":
# Data for URL
job = "data+science+internship"
Location = "Noida%2C+Uttar+Pradesh"
url = "https://in.indeed.com/jobs?q="+job+"&l="+Location
# Pass this URL into the soup
# which will return
# html string
soup = html_code(url)
# call job and company data
# and store into it var
job_res = job_data(soup)
com_res = company_data(soup)
# Traverse the both data
temp = 0
for i in range(1, len(job_res)):
j = temp
for j in range(temp, 2+temp):
print("Company Name and Address : " + com_res[j])
temp = j
print("Job : " + job_res[i])
print("-----------------------------")
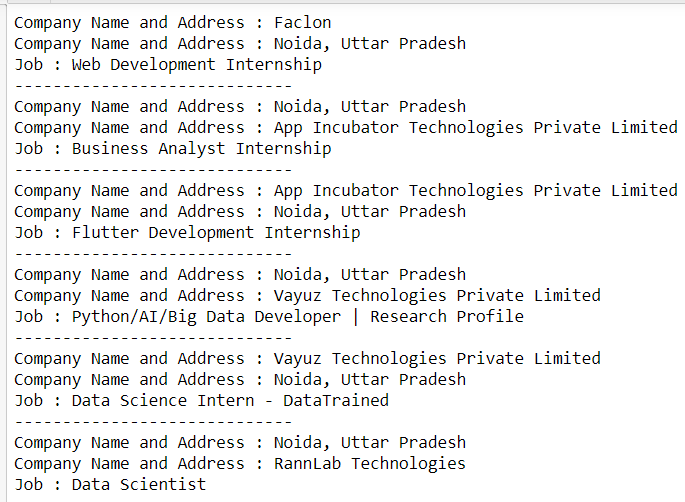
Producción:
Publicación traducida automáticamente
Artículo escrito por kumar_satyam y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA