Veamos cómo extraer los colores dominantes de una imagen usando Python. La agrupación en clústeres se utiliza en muchas aplicaciones del mundo real, uno de esos ejemplos reales de agrupación en clústeres es la extracción de colores dominantes de una imagen.
Cualquier imagen consta de píxeles, cada píxel representa un punto en una imagen. Un píxel contiene tres valores y cada valor oscila entre 0 y 255 , lo que representa la cantidad de componentes rojo , verde y azul . La combinación de estos forma un color real del píxel. Para encontrar los colores dominantes, se utiliza el concepto de agrupación de k-medias. Un uso importante del agrupamiento de k-medias es segmentar imágenes satelitales para identificar características de la superficie.
La imagen satelital que se muestra a continuación contiene el terreno de un valle fluvial.

El terreno del valle del río.
Varios colores generalmente pertenecen a diferentes características, el agrupamiento de k-medias se puede usar para agruparlos en grupos que luego se pueden identificar en varias superficies como agua, vegetación, etc., como se muestra a continuación.

Grupos agrupados (agua, campo abierto, …)
Herramientas para encontrar colores dominantes
- matplotlib.image.imread: convierte la imagen JPEG en una array que contiene valores RGB de cada píxel.
- matplotlib.pyplot.imshow: este método mostraría los colores de los centros de los clústeres después de realizar el agrupamiento de k-means en valores RGB.
Sumerjámonos ahora en un ejemplo, realizando un agrupamiento de k-means en la siguiente imagen:

Imagen de ejemplo
Como se puede ver, hay tres colores dominantes en esta imagen, un tono de azul , un tono de rojo y negro .
Paso 1: El primer paso en el proceso es convertir la imagen a píxeles utilizando el método imread de la clase de imagen.
Python3
# Import image class of matplotlib
import matplotlib.image as img
# Read batman image and print dimensions
batman_image = img.imread('batman.png')
print(batman_image.shape)
Producción :
(187, 295, 4)
La salida es una array M*N*3 donde M y N son las dimensiones de la imagen.
Paso 2: en este análisis, vamos a observar colectivamente todos los píxeles, independientemente de sus posiciones. Entonces, en este paso, todos los valores RGB se extraen y almacenan en sus listas correspondientes. Una vez que se crean las listas, se almacenan en Pandas DataFrame y luego escalan DataFrame para obtener valores estandarizados.
Python3
# Importing the modules
import pandas as pd
from scipy.cluster.vq import whiten
# Store RGB values of all pixels in lists r, g and b
r = []
g = []
b = []
for row in batman_image:
for temp_r, temp_g, temp_b, temp in row:
r.append(temp_r)
g.append(temp_g)
b.append(temp_b)
# only printing the size of these lists
# as the content is too big
print(len(r))
print(len(g))
print(len(b))
# Saving as DataFrame
batman_df = pd.DataFrame({'red' : r,
'green' : g,
'blue' : b})
# Scaling the values
batman_df['scaled_color_red'] = whiten(batman_df['red'])
batman_df['scaled_color_blue'] = whiten(batman_df['blue'])
batman_df['scaled_color_green'] = whiten(batman_df['green'])
Producción :
55165 55165 55165
Paso 3: Ahora, para encontrar el número de conglomerados en k-medias usando el enfoque de diagrama de codo . Este no es un método absoluto para encontrar el número de conglomerados, pero ayuda a dar una indicación sobre los conglomerados.
Gráfica de codo: una gráfica de líneas entre los centros de los grupos y la distorsión (la suma de las diferencias al cuadrado entre las observaciones y el centroide correspondiente).
A continuación se muestra el código para generar el diagrama del codo:
Python3
# Preparing data to construct elbow plot.
distortions = []
num_clusters = range(1, 7) #range of cluster sizes
# Create a list of distortions from the kmeans function
for i in num_clusters:
cluster_centers, distortion = kmeans(batman_df[['scaled_color_red',
'scaled_color_blue',
'scaled_color_green']], i)
distortions.append(distortion)
# Create a data frame with two lists, num_clusters and distortions
elbow_plot = pd.DataFrame({'num_clusters' : num_clusters,
'distortions' : distortions})
# Create a line plot of num_clusters and distortions
sns.lineplot(x = 'num_clusters', y = 'distortions', data = elbow_plot)
plt.xticks(num_clusters)
plt.show()
El diagrama de codo se traza como se muestra a continuación:
Producción :
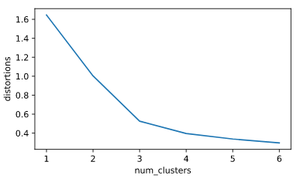
Parcela de codo
Se puede ver que se forma un codo adecuado en 3 en el eje x, lo que significa que el número de grupos es igual a 3 (hay tres colores dominantes en la imagen dada).
Paso 4: Los centros de conglomerados obtenidos son valores RGB estandarizados .
Standardized value = Actual value / Standard Deviation
Los colores dominantes se muestran mediante el método imshow(), que toma valores RGB escalados en el rango de 0 a 1. Para hacerlo, debe multiplicar los valores estandarizados de los centros de los grupos con las desviaciones estándar correspondientes. Dado que los valores RGB reales toman el rango máximo de 255, el resultado multiplicado se divide por 255 para obtener valores escalados en el rango 0-1.
Python3
cluster_centers, _ = kmeans(batman_df[['scaled_color_red', 'scaled_color_blue', 'scaled_color_green']], 3) dominant_colors = [] # Get standard deviations of each color red_std, green_std, blue_std = batman_df[['red', 'green', 'blue']].std() for cluster_center in cluster_centers: red_scaled, green_scaled, blue_scaled = cluster_center # Convert each standardized value to scaled value dominant_colors.append(( red_scaled * red_std / 255, green_scaled * green_std / 255, blue_scaled * blue_std / 255 )) # Display colors of cluster centers plt.imshow([dominant_colors]) plt.show()
Aquí está el gráfico resultante que muestra los tres colores dominantes de la imagen dada.
Producción :
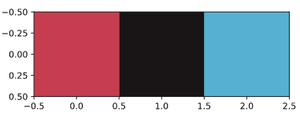
Parcela que muestra los colores dominantes
Observe que los tres colores se parecen a los tres que son indicativos de la inspección visual de la imagen.
A continuación se muestra el código completo sin los comentarios:
Python3
import matplotlib.image as img
import matplotlib.pyplot as plt
from scipy.cluster.vq import whiten
from scipy.cluster.vq import kmeans
import pandas as pd
batman_image = img.imread('batman.jpg')
r = []
g = []
b = []
for row in batman_image:
for temp_r, temp_g, temp_b, temp in row:
r.append(temp_r)
g.append(temp_g)
b.append(temp_b)
batman_df = pd.DataFrame({'red' : r,
'green' : g,
'blue' : b})
batman_df['scaled_color_red'] = whiten(batman_df['red'])
batman_df['scaled_color_blue'] = whiten(batman_df['blue'])
batman_df['scaled_color_green'] = whiten(batman_df['green'])
cluster_centers, _ = kmeans(batman_df[['scaled_color_red',
'scaled_color_blue',
'scaled_color_green']], 3)
dominant_colors = []
red_std, green_std, blue_std = batman_df[['red',
'green',
'blue']].std()
for cluster_center in cluster_centers:
red_scaled, green_scaled, blue_scaled = cluster_center
dominant_colors.append((
red_scaled * red_std / 255,
green_scaled * green_std / 255,
blue_scaled * blue_std / 255
))
plt.imshow([dominant_colors])
plt.show()